Spark 1.5.2 和 Hadoop 2.4 (Hive 2) 版本兼容性
Spark 1.5.2 and Hadoop 2.4 (Hive 2) version compatibility
我是将 Spark 与 Hadoop 结合使用的新手。
当前情况:
我已经使用预构建二进制 "spark-1.5.2-bin-hadoop2.6" 在 4 节点集群上配置了 Spark。
我的环境中还有一个具有 4 个节点的 Hadoop-2.4 集群。
我想要的:
我计划使用 Hive HQL 对 Hadoop 集群中的 hdfs 中存在的数据使用 Spark RDD 处理。
查询
我是否需要使用 "spark-1.5.2-bin-hadoop2.4" 二进制文件重新配置 spark 集群,否则当前的就可以了。
在两个不同的集群(但在云中的同一子网下)上使用 Spark over Hadoop 和 Hadoop 在 Spark over Hadoop 上工作是一个好习惯吗?
我认为最佳做法是 运行 在同一个集群上运行 spark 和 hadoop。事实上,spark 可以 运行 作为 yarn 应用程序(如果你使用 --master yarn client 进行 spark-submit)。
为什么 ?它归结为数据局部性。
数据局部性是 hadoop 和一般数据系统的基本概念。一般的想法是,您要处理的数据太大了,与其移动数据,不如将程序移动到数据所在的节点。
因此,对于 spark,如果你 运行 它在不同的集群上,所有数据都必须通过网络从一个集群移动到另一个集群。
计算和数据在同一个节点上更高效
至于版本,拥有两个不同版本的 hadoop 集群可能会很痛苦。我建议你有 2 个不同的 spark 安装,每个集群一个,为适当版本的 hadoop 编译。
您应该使用与 hadoop 兼容的 spark 版本。
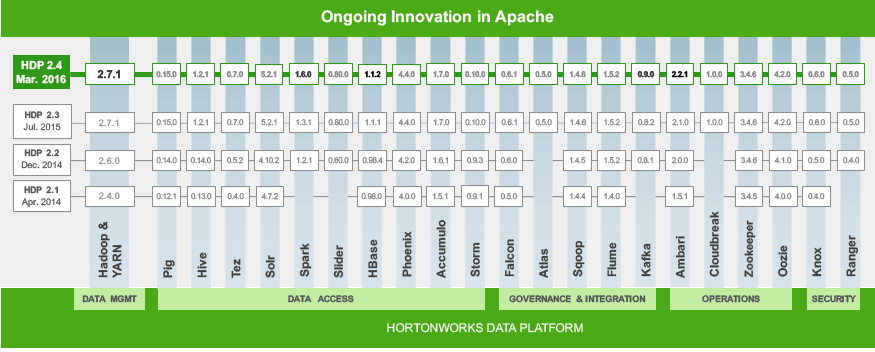
最近了解到,可以参考这里的兼容表:
http://hortonworks.com/wp-content/uploads/2016/03/asparagus-chart-hdp24.png
我是将 Spark 与 Hadoop 结合使用的新手。
当前情况:
我已经使用预构建二进制 "spark-1.5.2-bin-hadoop2.6" 在 4 节点集群上配置了 Spark。
我的环境中还有一个具有 4 个节点的 Hadoop-2.4 集群。
我想要的:
我计划使用 Hive HQL 对 Hadoop 集群中的 hdfs 中存在的数据使用 Spark RDD 处理。
查询
我是否需要使用 "spark-1.5.2-bin-hadoop2.4" 二进制文件重新配置 spark 集群,否则当前的就可以了。
在两个不同的集群(但在云中的同一子网下)上使用 Spark over Hadoop 和 Hadoop 在 Spark over Hadoop 上工作是一个好习惯吗?
我认为最佳做法是 运行 在同一个集群上运行 spark 和 hadoop。事实上,spark 可以 运行 作为 yarn 应用程序(如果你使用 --master yarn client 进行 spark-submit)。 为什么 ?它归结为数据局部性。 数据局部性是 hadoop 和一般数据系统的基本概念。一般的想法是,您要处理的数据太大了,与其移动数据,不如将程序移动到数据所在的节点。 因此,对于 spark,如果你 运行 它在不同的集群上,所有数据都必须通过网络从一个集群移动到另一个集群。 计算和数据在同一个节点上更高效
至于版本,拥有两个不同版本的 hadoop 集群可能会很痛苦。我建议你有 2 个不同的 spark 安装,每个集群一个,为适当版本的 hadoop 编译。
您应该使用与 hadoop 兼容的 spark 版本。
最近了解到,可以参考这里的兼容表: http://hortonworks.com/wp-content/uploads/2016/03/asparagus-chart-hdp24.png
{kind=link}