有没有什么方法可以可视化具有从一个热编码特征整合的分类特征的决策树(sklearn)?
Is there any way to visualize decision tree (sklearn) with categorical features consolidated from one hot encoded features?
这是一个 link .csv 文件。这是一个 classic 数据集,可用于练习决策树!
import pandas as pd
import numpy as np
import scipy as sc
import scipy.stats
from math import log
import operator
df = pd.read_csv('tennis.csv')
target = df['play']
target.columns = ['play']
features_dataframe = df.loc[:, df.columns != 'play']
这是我头疼的地方
features_dataframe = pd.get_dummies(features_dataframe)
features_dataframe.columns
我正在对存储在 features_dataframe 中的特征(数据)列执行一次热编码,这些列都是分类的并打印出来,returns
Index(['windy', 'outlook_overcast', 'outlook_rainy', 'outlook_sunny',
'temp_cool', 'temp_hot', 'temp_mild', 'humidity_high',
'humidity_normal'],
dtype='object')
我明白为什么要进行one-hot编码了! sklearn 不适用于分类列。
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
le.fit(target.values)
k = le.transform(target.values)
上面的代码将我存储在 target 中的目标列转换为整数,因为 sklearn 不会使用类别(耶!)
现在终于可以拟合 DecisionTreeClassifier,criterion = "entropy" 我假设使用的是 ID3 概念!
from sklearn import tree
from os import system
dtree = tree.DecisionTreeClassifier(criterion = "entropy")
dtree = dtree.fit(features_dataframe, k)
dotfile = open("id3.dot", 'w')
tree.export_graphviz(dtree, out_file = dotfile, feature_names = features_dataframe.columns)
dotfile.close()
文件 id3.dot 包含必要的代码,可以将其粘贴到此 site 上,以将二合字母代码转换为正确可理解的可视化!
为了方便大家有效方便的帮助我,我把postid3.dot的代码放在这里!
digraph Tree {
node [shape=box] ;
0 [label="outlook_overcast <= 0.5\nentropy = 0.94\nsamples = 14\nvalue = [5, 9]"] ;
1 [label="humidity_high <= 0.5\nentropy = 1.0\nsamples = 10\nvalue = [5, 5]"] ;
0 -> 1 [labeldistance=2.5, labelangle=45, headlabel="True"] ;
2 [label="windy <= 0.5\nentropy = 0.722\nsamples = 5\nvalue = [1, 4]"] ;
1 -> 2 ;
3 [label="entropy = 0.0\nsamples = 3\nvalue = [0, 3]"] ;
2 -> 3 ;
4 [label="outlook_rainy <= 0.5\nentropy = 1.0\nsamples = 2\nvalue = [1, 1]"] ;
2 -> 4 ;
5 [label="entropy = 0.0\nsamples = 1\nvalue = [0, 1]"] ;
4 -> 5 ;
6 [label="entropy = 0.0\nsamples = 1\nvalue = [1, 0]"] ;
4 -> 6 ;
7 [label="outlook_sunny <= 0.5\nentropy = 0.722\nsamples = 5\nvalue = [4, 1]"] ;
1 -> 7 ;
8 [label="windy <= 0.5\nentropy = 1.0\nsamples = 2\nvalue = [1, 1]"] ;
7 -> 8 ;
9 [label="entropy = 0.0\nsamples = 1\nvalue = [0, 1]"] ;
8 -> 9 ;
10 [label="entropy = 0.0\nsamples = 1\nvalue = [1, 0]"] ;
8 -> 10 ;
11 [label="entropy = 0.0\nsamples = 3\nvalue = [3, 0]"] ;
7 -> 11 ;
12 [label="entropy = 0.0\nsamples = 4\nvalue = [0, 4]"] ;
0 -> 12 [labeldistance=2.5, labelangle=-45, headlabel="False"] ;
}
转到here,并粘贴上面的二合字母代码以获得创建的决策树的正确可视化!这里的问题是,对于更大的树和更大的数据集,将很难解释,因为一个热编码的特征被显示为代表节点分裂的特征名称!
是否有解决方法,决策树可视化将显示合并的特征名称以表示从单热编码特征中拆分出来的节点?[=48=]
我的意思是,有没有一种方法可以创建像 this
这样的决策树可视化
不使用 One-Hot Encoding 而是对特定特征的类别使用一些任意整数代码可能更简单。
您可以使用 pandas.factorize 对分类变量进行整数编码。
这是一个 link .csv 文件。这是一个 classic 数据集,可用于练习决策树!
import pandas as pd
import numpy as np
import scipy as sc
import scipy.stats
from math import log
import operator
df = pd.read_csv('tennis.csv')
target = df['play']
target.columns = ['play']
features_dataframe = df.loc[:, df.columns != 'play']
这是我头疼的地方
features_dataframe = pd.get_dummies(features_dataframe)
features_dataframe.columns
我正在对存储在 features_dataframe 中的特征(数据)列执行一次热编码,这些列都是分类的并打印出来,returns
Index(['windy', 'outlook_overcast', 'outlook_rainy', 'outlook_sunny',
'temp_cool', 'temp_hot', 'temp_mild', 'humidity_high',
'humidity_normal'],
dtype='object')
我明白为什么要进行one-hot编码了! sklearn 不适用于分类列。
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
le.fit(target.values)
k = le.transform(target.values)
上面的代码将我存储在 target 中的目标列转换为整数,因为 sklearn 不会使用类别(耶!)
现在终于可以拟合 DecisionTreeClassifier,criterion = "entropy" 我假设使用的是 ID3 概念!
from sklearn import tree
from os import system
dtree = tree.DecisionTreeClassifier(criterion = "entropy")
dtree = dtree.fit(features_dataframe, k)
dotfile = open("id3.dot", 'w')
tree.export_graphviz(dtree, out_file = dotfile, feature_names = features_dataframe.columns)
dotfile.close()
文件 id3.dot 包含必要的代码,可以将其粘贴到此 site 上,以将二合字母代码转换为正确可理解的可视化!
为了方便大家有效方便的帮助我,我把postid3.dot的代码放在这里!
digraph Tree {
node [shape=box] ;
0 [label="outlook_overcast <= 0.5\nentropy = 0.94\nsamples = 14\nvalue = [5, 9]"] ;
1 [label="humidity_high <= 0.5\nentropy = 1.0\nsamples = 10\nvalue = [5, 5]"] ;
0 -> 1 [labeldistance=2.5, labelangle=45, headlabel="True"] ;
2 [label="windy <= 0.5\nentropy = 0.722\nsamples = 5\nvalue = [1, 4]"] ;
1 -> 2 ;
3 [label="entropy = 0.0\nsamples = 3\nvalue = [0, 3]"] ;
2 -> 3 ;
4 [label="outlook_rainy <= 0.5\nentropy = 1.0\nsamples = 2\nvalue = [1, 1]"] ;
2 -> 4 ;
5 [label="entropy = 0.0\nsamples = 1\nvalue = [0, 1]"] ;
4 -> 5 ;
6 [label="entropy = 0.0\nsamples = 1\nvalue = [1, 0]"] ;
4 -> 6 ;
7 [label="outlook_sunny <= 0.5\nentropy = 0.722\nsamples = 5\nvalue = [4, 1]"] ;
1 -> 7 ;
8 [label="windy <= 0.5\nentropy = 1.0\nsamples = 2\nvalue = [1, 1]"] ;
7 -> 8 ;
9 [label="entropy = 0.0\nsamples = 1\nvalue = [0, 1]"] ;
8 -> 9 ;
10 [label="entropy = 0.0\nsamples = 1\nvalue = [1, 0]"] ;
8 -> 10 ;
11 [label="entropy = 0.0\nsamples = 3\nvalue = [3, 0]"] ;
7 -> 11 ;
12 [label="entropy = 0.0\nsamples = 4\nvalue = [0, 4]"] ;
0 -> 12 [labeldistance=2.5, labelangle=-45, headlabel="False"] ;
}
转到here,并粘贴上面的二合字母代码以获得创建的决策树的正确可视化!这里的问题是,对于更大的树和更大的数据集,将很难解释,因为一个热编码的特征被显示为代表节点分裂的特征名称!
是否有解决方法,决策树可视化将显示合并的特征名称以表示从单热编码特征中拆分出来的节点?[=48=]
我的意思是,有没有一种方法可以创建像 this
这样的决策树可视化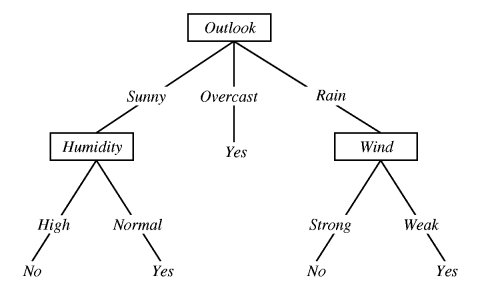{kind=link}
不使用 One-Hot Encoding 而是对特定特征的类别使用一些任意整数代码可能更简单。
您可以使用 pandas.factorize 对分类变量进行整数编码。