加速莱布尼兹级数计算 Pi
Accelerating Leibniz Series for calculating Pi
当我学习数学时,我读到了关于 Pi 的 Leibniz Series 系列:
所以我为此编写了一个程序,对这个系列的 n 项求和:
def leibniz(n):
pi = 0
for i in range(1,n+1):
if(i % 2 == 0):
pi -= 1 / (2*i - 1)
else:
pi += 1/(2*i - 1)
pi = 4 * pi
return pi
此代码有效,但问题是它收敛到 Pi 的速度非常慢。
- 所以我阅读了不同的系列加速,基本上对我来说最好的是 Euler Acceleration
- 收敛慢是因为我的版本是交替序列,即包含(-1)^n。但是我更困惑我该如何编程。
编辑:
我了解了香克斯变换并对其进行了编程
def accelrate(n,depth):
if depth == 1:
a = lebniez(n + 1)
b = lebniez(n)
c = lebniez(n-1)
return (a*c - b*b)/(a + c - 2*b)
a = accelrate(n + 1,depth - 1)
b = accelrate(n,depth - 1)
c = accelrate(n-1,depth - 1)
return (a*c - b*b)/(a + c - 2*b)
所以 htis 所做的是它递归地应用 Shanks 变换并继续加速该系列。但现在的问题是,由于递归,它非常慢,如果增加深度,准确性也不会提高。
这就是香克斯转型的低效吗
所以经过深思熟虑,我想到了在我的 this shanks 转换中减少缓存。
虽然没有太大改进,但仍然是一个很好的改进。
这里是:
import functools as ft
@ft.lru_cache(maxsize=32)
def lebniez(n):
pi = 0
n = n + 1
for i in range(1,n):
if(i % 2 == 1):
pi -= 1 / (2*i - 1)
else:
pi += 1/(2*i - 1)
pi = abs(4 * pi)
return pi
@ft.lru_cache(maxsize=128)
def accelrate(n,depth):
if depth == 1:
a = lebniez(n + 1)
b = lebniez(n)
c = lebniez(n-1)
else:
a = accelrate(n + 1,depth - 1)
b = accelrate(n,depth - 1)
c = accelrate(n-1,depth - 1)
return (a*c - b*b)/(a + c - 2*b)
所以这个基础有助于让它更稳定。
接下来是Inefficiency,原因是Shanks Transformation只是针对Error(n + 1) / Error(n)的比率为常数的序列。但再次应用香克斯变换后,这会导致效率低下
当我学习数学时,我读到了关于 Pi 的 Leibniz Series 系列:
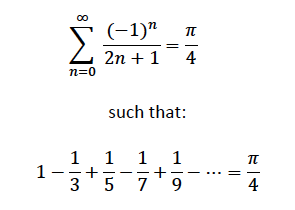{kind=link}
所以我为此编写了一个程序,对这个系列的 n 项求和:
def leibniz(n):
pi = 0
for i in range(1,n+1):
if(i % 2 == 0):
pi -= 1 / (2*i - 1)
else:
pi += 1/(2*i - 1)
pi = 4 * pi
return pi
此代码有效,但问题是它收敛到 Pi 的速度非常慢。
- 所以我阅读了不同的系列加速,基本上对我来说最好的是 Euler Acceleration
- 收敛慢是因为我的版本是交替序列,即包含(-1)^n。但是我更困惑我该如何编程。
编辑:
我了解了香克斯变换并对其进行了编程
def accelrate(n,depth):
if depth == 1:
a = lebniez(n + 1)
b = lebniez(n)
c = lebniez(n-1)
return (a*c - b*b)/(a + c - 2*b)
a = accelrate(n + 1,depth - 1)
b = accelrate(n,depth - 1)
c = accelrate(n-1,depth - 1)
return (a*c - b*b)/(a + c - 2*b)
所以 htis 所做的是它递归地应用 Shanks 变换并继续加速该系列。但现在的问题是,由于递归,它非常慢,如果增加深度,准确性也不会提高。
这就是香克斯转型的低效吗
所以经过深思熟虑,我想到了在我的 this shanks 转换中减少缓存。
虽然没有太大改进,但仍然是一个很好的改进。
这里是:
import functools as ft
@ft.lru_cache(maxsize=32)
def lebniez(n):
pi = 0
n = n + 1
for i in range(1,n):
if(i % 2 == 1):
pi -= 1 / (2*i - 1)
else:
pi += 1/(2*i - 1)
pi = abs(4 * pi)
return pi
@ft.lru_cache(maxsize=128)
def accelrate(n,depth):
if depth == 1:
a = lebniez(n + 1)
b = lebniez(n)
c = lebniez(n-1)
else:
a = accelrate(n + 1,depth - 1)
b = accelrate(n,depth - 1)
c = accelrate(n-1,depth - 1)
return (a*c - b*b)/(a + c - 2*b)
所以这个基础有助于让它更稳定。
接下来是Inefficiency,原因是Shanks Transformation只是针对Error(n + 1) / Error(n)的比率为常数的序列。但再次应用香克斯变换后,这会导致效率低下