加泰罗尼亚数字递归到记忆
Recursion for Catalan number to Memoized
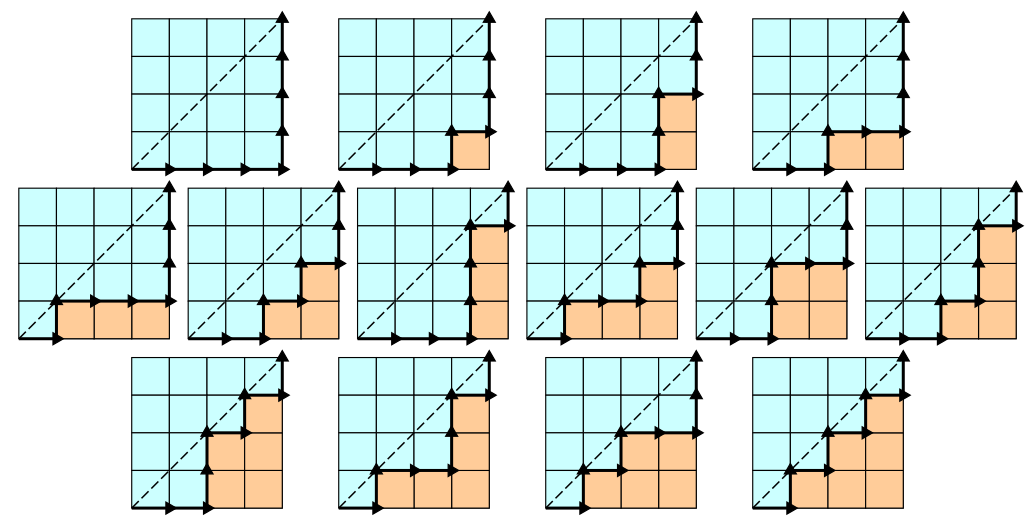
我被要求编写一个递归函数,用于计算沿着具有 n × n 方形单元格的网格边缘的单调格子路径的加泰罗尼亚数,这些单元格不会超过对角线(pic )
不允许我使用 for 循环,只能使用递归调用...这就是我所做的:
public long C(int n) {
if (n == 1)
return 0;
return C(n, 0, 0);
}
private long C(int n, int i, int j) {
// CAN MOVE UP & RIGHT
if (j - i > 0 && j + 1 <= n)
return paths(n, i + 1, j) + paths(n, i, j + 1);
// CAN MOVE UP
else if (j - i > 0)
return paths(n, i + 1, j);
// CAN MOVE RIGHT
else if (j + 1 <= n)
return paths(n, i, j + 1);
// CAN'T MOVE
else
return 1;
}
我不知道这段代码是否最好,但它确实有效...我想将此函数转换为记忆函数。但我不明白它如何以及为什么会使功能更有效率。我明白为什么 memoized 中的 Fibonnaci 效率更高,但在这里我总是必须到达路径的尽头然后 return 1 或 0 所以如果我将 1 / 0 存储在数组中有什么关系说?
感谢您的帮助
看来你知道Memoization是什么了。基本上,您所做的就是创建一个 table memo ,一旦您到达它就会存储一个值,这样您就不必在递归中再次计算它。类似于为什么 fibonacci(5) 不必进入递归来查找 fibonacci(3),如果我们已经计算过,比如说 fibonacci(6),因为我们有 memoized[=20] =] 它。我希望你能明白。这是代码,本着同样的精神记忆。 Andrea 的问题具有很好的视觉效果。
long[][]memo; //Memo table
public long C(int n)
{
if (n == 1)
return 0;
memo=new int[n+1][n+1]; //Increase to n+1 and won't crash!
for(int i=0;i<=n;i++)
for(int j=0;j<=n;j++)
memo[j][i]=-1;
return C(n, 0, 0, memo);
}
private long C(int n, int i, int j, it) {
// CAN MOVE UP & RIGHT
if (j - i > 0 && j + 1 <= n)
{
if(memo[i+1][j]==-1)
memo[i+1][j]=paths(n, i + 1, j);
if(memo[i][j+1]==-1)
memo[i][j+1]=paths(n, i, j + 1);
return memo[i+1][j]+memo[i][j+1];
}
// CAN MOVE UP
else if (j - i > 0)
{
if(memo[i+1][j]==-1)
memo[i+1][j]=paths(n, i + 1, j);
return memo[i+1][j];
}
// CAN MOVE RIGHT
else if (j + 1 <= n)
{
if(memo[i][j+1]==-1)
memo[i][j+1]=paths(n, i, j + 1);
return memo[i][j+1];
}
// CAN'T MOVE
else
return 1;
}
But I can't understand [...] why it would make the function more efficient.
看图,图片编号从1开始,左下角(x,y)坐标为(0,0),可以看到图2,3,4,5,6, 7,8,10,12, 都经过(3,1).
点
来自 (3,1) 的路径:
(3,1) → (4,1) ↑ (4,2) ↑ (4,3) ↑ (4,4)
- 图2、4、5
(3,1) ↑ (3,2) → (4,2) ↑ (4,3) ↑ (4,4)
- 图3、6、8
(3,1) ↑ (3,2) ↑ (3,3) → (4,3) ↑ (4,4)
- 图7、10、12
如您所见,您正在同一条路径上行走多 (3) 次。如果您可以缓存(记住)从 (3,1) 到最后有 3 条路径这一事实,您就可以节省时间。
随着网格变大,节省的时间也会增加。
所以,你所做的是,当你第一次到达一个点时,你使用递归计算结果,就像你已经做的那样,然后保存那个点的数字,当再次到达那个点时,你只需使用缓存值:
public static long paths(int n) {
if (n == 1)
return 0;
return paths(n, 0, 0, new long[n][n]);
}
private static long paths(int n, int y, int x, long[][] cache) {
long result = cache[y][x];
if (result == 0) {
if (y < x && x < n) // CAN MOVE UP & RIGHT
result = paths(n, y + 1, x, cache) + paths(n, y, x + 1, cache);
else if (y < x) // CAN MOVE UP
result = paths(n, y + 1, x, cache);
else if (x < n) // CAN MOVE RIGHT
result = paths(n, y, x + 1, cache);
else // CAN'T MOVE
result = 1;
cache[y][x] = result;
}
return result;
}
我被要求编写一个递归函数,用于计算沿着具有 n × n 方形单元格的网格边缘的单调格子路径的加泰罗尼亚数,这些单元格不会超过对角线(pic )
不允许我使用 for 循环,只能使用递归调用...这就是我所做的:
{kind=link}
public long C(int n) {
if (n == 1)
return 0;
return C(n, 0, 0);
}
private long C(int n, int i, int j) {
// CAN MOVE UP & RIGHT
if (j - i > 0 && j + 1 <= n)
return paths(n, i + 1, j) + paths(n, i, j + 1);
// CAN MOVE UP
else if (j - i > 0)
return paths(n, i + 1, j);
// CAN MOVE RIGHT
else if (j + 1 <= n)
return paths(n, i, j + 1);
// CAN'T MOVE
else
return 1;
}
我不知道这段代码是否最好,但它确实有效...我想将此函数转换为记忆函数。但我不明白它如何以及为什么会使功能更有效率。我明白为什么 memoized 中的 Fibonnaci 效率更高,但在这里我总是必须到达路径的尽头然后 return 1 或 0 所以如果我将 1 / 0 存储在数组中有什么关系说?
感谢您的帮助
看来你知道Memoization是什么了。基本上,您所做的就是创建一个 table memo ,一旦您到达它就会存储一个值,这样您就不必在递归中再次计算它。类似于为什么 fibonacci(5) 不必进入递归来查找 fibonacci(3),如果我们已经计算过,比如说 fibonacci(6),因为我们有 memoized[=20] =] 它。我希望你能明白。这是代码,本着同样的精神记忆。 Andrea 的问题具有很好的视觉效果。
long[][]memo; //Memo table
public long C(int n)
{
if (n == 1)
return 0;
memo=new int[n+1][n+1]; //Increase to n+1 and won't crash!
for(int i=0;i<=n;i++)
for(int j=0;j<=n;j++)
memo[j][i]=-1;
return C(n, 0, 0, memo);
}
private long C(int n, int i, int j, it) {
// CAN MOVE UP & RIGHT
if (j - i > 0 && j + 1 <= n)
{
if(memo[i+1][j]==-1)
memo[i+1][j]=paths(n, i + 1, j);
if(memo[i][j+1]==-1)
memo[i][j+1]=paths(n, i, j + 1);
return memo[i+1][j]+memo[i][j+1];
}
// CAN MOVE UP
else if (j - i > 0)
{
if(memo[i+1][j]==-1)
memo[i+1][j]=paths(n, i + 1, j);
return memo[i+1][j];
}
// CAN MOVE RIGHT
else if (j + 1 <= n)
{
if(memo[i][j+1]==-1)
memo[i][j+1]=paths(n, i, j + 1);
return memo[i][j+1];
}
// CAN'T MOVE
else
return 1;
}
But I can't understand [...] why it would make the function more efficient.
看图,图片编号从1开始,左下角(x,y)坐标为(0,0),可以看到图2,3,4,5,6, 7,8,10,12, 都经过(3,1).
来自 (3,1) 的路径:
(3,1) → (4,1) ↑ (4,2) ↑ (4,3) ↑ (4,4)- 图2、4、5
(3,1) ↑ (3,2) → (4,2) ↑ (4,3) ↑ (4,4)- 图3、6、8
(3,1) ↑ (3,2) ↑ (3,3) → (4,3) ↑ (4,4)- 图7、10、12
如您所见,您正在同一条路径上行走多 (3) 次。如果您可以缓存(记住)从 (3,1) 到最后有 3 条路径这一事实,您就可以节省时间。
随着网格变大,节省的时间也会增加。
所以,你所做的是,当你第一次到达一个点时,你使用递归计算结果,就像你已经做的那样,然后保存那个点的数字,当再次到达那个点时,你只需使用缓存值:
public static long paths(int n) {
if (n == 1)
return 0;
return paths(n, 0, 0, new long[n][n]);
}
private static long paths(int n, int y, int x, long[][] cache) {
long result = cache[y][x];
if (result == 0) {
if (y < x && x < n) // CAN MOVE UP & RIGHT
result = paths(n, y + 1, x, cache) + paths(n, y, x + 1, cache);
else if (y < x) // CAN MOVE UP
result = paths(n, y + 1, x, cache);
else if (x < n) // CAN MOVE RIGHT
result = paths(n, y, x + 1, cache);
else // CAN'T MOVE
result = 1;
cache[y][x] = result;
}
return result;
}