使用 R 绘制描绘 R2 (Rsquared) 值的 100x100 等高线图
Drawing a 100x100 contour plot depicting R2 (Rsquared) values using R
我有一个由 106 列和 28 行组成的遥感数据集。在我的例子中,这些行与个人观察或个人情节有关。第一列存储可以识别每个地块的唯一 ID。接下来的 100 列存储连续光谱带(band_x、band_x2、band_x3 等)中每个图的平均测量反射率值。其余 5 列存储在每个地块的田间测量的各种植物参数(例如叶绿素、氮、生物量等)的值。数据集大致如下所示:
PlotID b1 b2 .... b99 b100 biomass nitrogen
1 0.11 0.16 0.40 0.41 10 52
2 0.09 0.11 0.41 0.40 19 35
3 0.10 0.19 0.43 0.49 18 72
4 0.13 0.10 0.44 0.39 16 46
...
我希望创建等高线图,描绘与单个植物参数(例如生物量)相关的两个波段的所有可能组合的所有可能相关性的 R2(R 平方)值。例如,等高线图需要显示所有可能的简单比率组合 (band_x1/band_x2) 与单个性状之间相关性的 R2 值。此外,我希望将其复制到其他两种类型的指数中,即归一化差异指数 ((band_x2+band_x1)/(band_x2-band_x 1)) 和一个简单的差异索引 (band_x2-band_x1).
我一直在研究 R 中的 contour.plot 语法和各种实际示例,但是,none 确实与我所追求的有关。我以前见过这些图表,所以一定有生成它们的方法。谁能帮帮我?
提前致谢!
编辑:为了澄清一些事情,这里是我正在寻找重新创建的图表示例:
http://image.slidesharecdn.com/2269e63a-1825-41b1-8d58-6901fd5b56ba-150102021118-conversion-gate01/95/thenkabailuavgermanyfinal1b-46-638.jpg?cb=1420186425
在 Heroka 的帮助下,我现在已经根据以下代码重新创建了大部分情节(但是,大部分代码主要与图形相关):
n_band=101
dat <- read.table("C:\data.txt", header=TRUE)
res <- expand.grid(paste0("b", seq(from = 450, to = 950, by = 5)),paste0("b",seq(from = 450, to = 950, by = 5)),outcome=c("nitrogen"))
res$R2 <- apply(res, MARGIN=1,FUN=function(x){
return(cor(dat[,x[1]]/dat[,x[2]],dat[,x[3]])^2)
})
library(scales)
library(ggplot2)
p1 <- ggplot(res, aes(x=Var1, y=Var2, fill=R2)) +
geom_tile() +
facet_grid(~outcome)
p1 +
theme(axis.text.x=element_text(angle=+90)) +
geom_vline(xintercept=c(seq(from = 1, to = 101, by = 5)),color="#8C8C8C") +
geom_hline(yintercept=c(seq(from = 1, to = 101, by = 5)),color="#8C8C8C") +
labs(list(title = "Contour plot of R^2 values for all possible correlations between Simple Ratio indices & Nitrogen Content", x = "Wavelength 1 (nm)", y = "Wavelength 2 (nm)")) +
scale_x_discrete(breaks = c("b450","b475","b500","b525","b550","b575","b600","b625","b650","b675","b700","b725","b750","b775","b800","b825","b850","b875","b900","b925","b950")) +
scale_y_discrete(breaks = c("b450","b475","b500","b525","b550","b575","b600","b625","b650","b675","b700","b725","b750","b775","b800","b825","b850","b875","b900","b925","b950")) +
scale_fill_continuous(low = "black", high = "green")
ContourPlot
我越来越接近我的最终目标,但还有一些事情我想改变:
- 有一个离散颜色的比例尺,最好依靠广泛多样但渐变的配色方案,以更好地识别具有最高 R2 值的波段组合。理想情况下,我想对所有地块使用标准数量的 类 (8),每个都包含相同数量的观察值。因此,允许软件本身根据每个相关参数的最小和最大 R2 值来确定中断值。
- 此外,我希望能够从每个图中识别出最高值,或者更具体地说是它们的 (x,y) 坐标,这样我就可以判断哪些波段产生最高的相关性。我使用了 which.min 和 which.max,但它们没有产生任何合理的结果,也没有产生 (x,y) 坐标。
下面是一个示例,您可以如何解决此类问题。我对如何计算 R2 做了一个假设,但如果它有误,很容易修复。
首先,我们模拟一些数据
set.seed(123)
n_band=100
dat <- data.frame(matrix(runif(28*n_band),ncol=n_band))
colnames(dat) <- paste0("b",1:n_band)
dat$biomass <- rpois(28,10)
dat$nitrogen <- rpois(28,10)
dat$ID <- 1:28
然后,我们观察到对于 band1、band2 和结果的每个组合,我们只需要存储一个数字 (R2)。因此,首先我们生成一个数据框,其中包含列名的所有组合作为字符串:
res <- expand.grid(paste0("b",1:n_band),paste0("b",1:n_band),outcome=c("biomass","nitrogen"))
然后我们使用 apply 为 res 的每一行(因此每个组合)获取 R2。由于 res 的每一行包含三个列名,我们可以使用它们来访问原始数据。
#ignore warnings; correlation between similar variables is missing
res$R2 <- apply(res, MARGIN=1,FUN=function(x){
return(cor(dat[,x[1]]/dat[,x[2]],dat[,x[3]])^2)
})
那么绘图就简单了:
library(ggplot2)
p1 <- ggplot(res, aes(x=Var1, y=Var2, fill=R2))+
geom_tile() +
facet_grid(~outcome)
p1
我有一个由 106 列和 28 行组成的遥感数据集。在我的例子中,这些行与个人观察或个人情节有关。第一列存储可以识别每个地块的唯一 ID。接下来的 100 列存储连续光谱带(band_x、band_x2、band_x3 等)中每个图的平均测量反射率值。其余 5 列存储在每个地块的田间测量的各种植物参数(例如叶绿素、氮、生物量等)的值。数据集大致如下所示:
PlotID b1 b2 .... b99 b100 biomass nitrogen
1 0.11 0.16 0.40 0.41 10 52
2 0.09 0.11 0.41 0.40 19 35
3 0.10 0.19 0.43 0.49 18 72
4 0.13 0.10 0.44 0.39 16 46
...
我希望创建等高线图,描绘与单个植物参数(例如生物量)相关的两个波段的所有可能组合的所有可能相关性的 R2(R 平方)值。例如,等高线图需要显示所有可能的简单比率组合 (band_x1/band_x2) 与单个性状之间相关性的 R2 值。此外,我希望将其复制到其他两种类型的指数中,即归一化差异指数 ((band_x2+band_x1)/(band_x2-band_x 1)) 和一个简单的差异索引 (band_x2-band_x1).
我一直在研究 R 中的 contour.plot 语法和各种实际示例,但是,none 确实与我所追求的有关。我以前见过这些图表,所以一定有生成它们的方法。谁能帮帮我?
提前致谢!
编辑:为了澄清一些事情,这里是我正在寻找重新创建的图表示例: http://image.slidesharecdn.com/2269e63a-1825-41b1-8d58-6901fd5b56ba-150102021118-conversion-gate01/95/thenkabailuavgermanyfinal1b-46-638.jpg?cb=1420186425
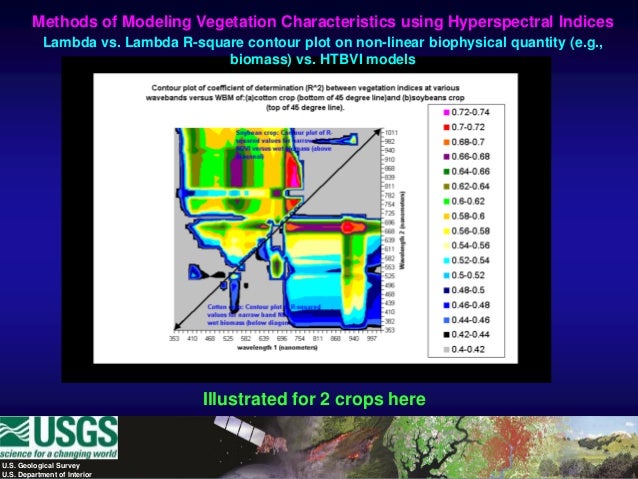{kind=link}
在 Heroka 的帮助下,我现在已经根据以下代码重新创建了大部分情节(但是,大部分代码主要与图形相关):
n_band=101
dat <- read.table("C:\data.txt", header=TRUE)
res <- expand.grid(paste0("b", seq(from = 450, to = 950, by = 5)),paste0("b",seq(from = 450, to = 950, by = 5)),outcome=c("nitrogen"))
res$R2 <- apply(res, MARGIN=1,FUN=function(x){
return(cor(dat[,x[1]]/dat[,x[2]],dat[,x[3]])^2)
})
library(scales)
library(ggplot2)
p1 <- ggplot(res, aes(x=Var1, y=Var2, fill=R2)) +
geom_tile() +
facet_grid(~outcome)
p1 +
theme(axis.text.x=element_text(angle=+90)) +
geom_vline(xintercept=c(seq(from = 1, to = 101, by = 5)),color="#8C8C8C") +
geom_hline(yintercept=c(seq(from = 1, to = 101, by = 5)),color="#8C8C8C") +
labs(list(title = "Contour plot of R^2 values for all possible correlations between Simple Ratio indices & Nitrogen Content", x = "Wavelength 1 (nm)", y = "Wavelength 2 (nm)")) +
scale_x_discrete(breaks = c("b450","b475","b500","b525","b550","b575","b600","b625","b650","b675","b700","b725","b750","b775","b800","b825","b850","b875","b900","b925","b950")) +
scale_y_discrete(breaks = c("b450","b475","b500","b525","b550","b575","b600","b625","b650","b675","b700","b725","b750","b775","b800","b825","b850","b875","b900","b925","b950")) +
scale_fill_continuous(low = "black", high = "green")
ContourPlot 我越来越接近我的最终目标,但还有一些事情我想改变: - 有一个离散颜色的比例尺,最好依靠广泛多样但渐变的配色方案,以更好地识别具有最高 R2 值的波段组合。理想情况下,我想对所有地块使用标准数量的 类 (8),每个都包含相同数量的观察值。因此,允许软件本身根据每个相关参数的最小和最大 R2 值来确定中断值。 - 此外,我希望能够从每个图中识别出最高值,或者更具体地说是它们的 (x,y) 坐标,这样我就可以判断哪些波段产生最高的相关性。我使用了 which.min 和 which.max,但它们没有产生任何合理的结果,也没有产生 (x,y) 坐标。
{kind=link}
下面是一个示例,您可以如何解决此类问题。我对如何计算 R2 做了一个假设,但如果它有误,很容易修复。
首先,我们模拟一些数据
set.seed(123)
n_band=100
dat <- data.frame(matrix(runif(28*n_band),ncol=n_band))
colnames(dat) <- paste0("b",1:n_band)
dat$biomass <- rpois(28,10)
dat$nitrogen <- rpois(28,10)
dat$ID <- 1:28
然后,我们观察到对于 band1、band2 和结果的每个组合,我们只需要存储一个数字 (R2)。因此,首先我们生成一个数据框,其中包含列名的所有组合作为字符串:
res <- expand.grid(paste0("b",1:n_band),paste0("b",1:n_band),outcome=c("biomass","nitrogen"))
然后我们使用 apply 为 res 的每一行(因此每个组合)获取 R2。由于 res 的每一行包含三个列名,我们可以使用它们来访问原始数据。
#ignore warnings; correlation between similar variables is missing
res$R2 <- apply(res, MARGIN=1,FUN=function(x){
return(cor(dat[,x[1]]/dat[,x[2]],dat[,x[3]])^2)
})
那么绘图就简单了:
library(ggplot2)
p1 <- ggplot(res, aes(x=Var1, y=Var2, fill=R2))+
geom_tile() +
facet_grid(~outcome)
p1