如何解决这个非递归奇偶合并排序算法?
How to fix this non-recursive odd-even-merge sort algorithm?
我正在搜索非递归奇偶合并排序算法并找到了 2 个来源:
- 来自 Sedgewick R.
的一本书
- 这个SO question
两种算法相同但都是错误的。生成的排序网络不是奇偶合并排序网络。
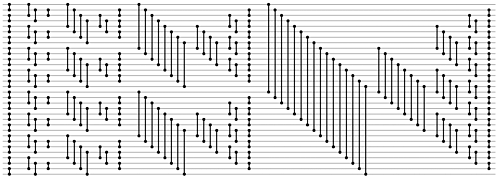
这是具有 32 个输入的生成网络的图像。两条水平线之间的垂直线表示比较值 a[x] 和 a[y],如果更大则交换数组中的值。
(来源:flylib.com)
(可点击)
我将代码从 Java 复制到 C 并将 exch 函数替换为 printf 以打印交换候选人。
画对图时,可以看出生成的对太多了。
有人知道如何修正这个算法吗?
为什么我需要非递归版本?
我想把这个分拣网络改造成硬件。将流水线阶段插入非递归算法很容易。
我也研究了递归版本,但是将算法转换为流水线硬件太复杂了。
我的C代码:
#include <stdlib.h>
#include <stdio.h>
void sort(int l, int r)
{ int n = r-l+1;
for (int p=1; p<n; p+=p)
for (int k=p; k>0; k/=2)
for (int j=k%p; j+k<n; j+=(k+k))
for (int i=0; i<n-j-k; i++)
if ((j+i)/(p+p) == (j+i+k)/(p+p))
printf("%2i cmp %2i\n", l+j+i, l+j+i+k);
}
int main(char* argv, int args)
{ const int COUNT = 8;
sort(0, COUNT);
}
结果:
0 -o--------o-------------------------o---------------o-------------------------
| | | |
1 -o--------|-o------o----------------|-o-------------o-o-----------------------
| | | | | |
2 -o-o------o-|------o-o--------------|-|-o----o--------o-o---------------------
| | | | | | | | |
3 -o-o--------o--------o--------------|-|-|-o--|-o--------o-o-------o-----------
| | | | | | | |
4 -o-o-o----o---o----o-----o----------o-|-|-|--o-|-o--------o-o-----o-o---------
| | | | | | | | | | | | | |
5 -o-o-o----|-o-|-o--o-o---o-o---o------o-|-|----o-|-o--------o-o-----o-o---o---
| | | | | | | | | | | | | |
6 -o-o-o-o--o-|-o-|----o-o---o-o-o-o------o-|------o-|----------o-o-----o-o-o-o-
| | | | | | | | | | | | | |
7 -o-o-o-o----o---o------o-----o---o--------o--------o------------o-------o---o-
当我知道正确的交换对并且算法等于图像时,我会把它翻译成VHDL在我的硬件平台上测试。
其他开源硬件排序网络实现:
附录:
奇偶合并排序(a.k.a Batcher 的排序)就像双调排序(不要与 Batcher 的双调排序混淆)。但是在硬件上,这个算法比双调排序有更好的大小复杂度,而延迟是相同的。
与快速排序等快速软件算法相比,这些算法可以在资源利用率良好的情况下实现。
维基百科:odd-even mergesort
注:
因为排序网络是静态的并且独立于输入值,所以不需要比较和交换来生成网络。这就是它可以转化为硬件的原因之一。我的代码为比较操作生成索引。在硬件中,这些垂直连接将被比较和交换电路所取代。因此,未排序的数据将通过网络传输,并在输出端进行排序。
我想我找到了解决办法。我检查了 length = 2, 4, 8, 16。
这是我的代码:
void sort(int length)
{ int G = log2ceil(length); // number of groups
for (int g = 0; g < G; g++) // iterate groups
{ int B = 1 << (G - g - 1); // number of blocks
for (int b = 0; b < B; b++) // iterate blocks in a group
{ for (int s = 0; s <= g; s++) // iterate stages in a block
{ int d = 1 << (g - s); // compare distance
int J = (s == 0) ? 0 : d; // starting point
for (int j = J; j+d < (2<<g); j += 2*d) // iterate startpoints
{ for (int i = 0; i < d; i++) // shift startpoints
{ int x = (b * (length / B)) + j + i; // index 1
int y = x + d; // index 2
printf("%2i cmp %2i\n", x, y);
}
}
}
}
}
此解决方案引入了第五个 for 循环来处理组中的子块。
j 循环更改了开始和中止值,以处理 post 合并步骤的奇数计数,而不会生成双倍比较步骤。
以下代码适用于任何大小的数组并且不是递归的。它是 Perl 的 Algorithm::Networksort 模块中 the corresponding function 实现的直接移植。该实现恰好对应于 Knuth 在 计算机编程艺术,第 3 卷 中描述的算法(算法 5.2.2M)。它对实际修复您的算法没有帮助,但它至少为您提供了 Batcher 的奇偶合并排序的有效非递归实现,只有三个嵌套循环:)
#include <math.h>
#include <stdio.h>
void oddeven_merge_sort(int length)
{
int t = ceil(log2(length));
int p = pow(2, t - 1);
while (p > 0) {
int q = pow(2, t - 1);
int r = 0;
int d = p;
while (d > 0) {
for (int i = 0 ; i < length - d ; ++i) {
if ((i & p) == r) {
printf("%2i cmp %2i\n", i, i + d);
}
}
d = q - p;
q /= 2;
r = p;
}
p /= 2;
}
}
如果你能拿到一本 计算机编程艺术,第 3 卷,你也会很好地解释算法的工作原理和原因作为一些额外的细节。
这是一个固定的非递归子程序。
void sort(int n)
{
for (int p = 1; p < n; p += p)
for (int k = p; k > 0; k /= 2)
for (int j = k % p; j + k < n; j += k + k)
//for (int i = 0; i < n - (j + k); i++) // wrong
for (int i = 0; i < k; i++) // correct
if ((i + j)/(p + p) == (i + j + k)/(p + p))
printf("%2i cmp %2i\n", i + j, i + j + k);
}
或
void sort(int n)
{
for (int p = 1; p < n; p += p)
for (int k = p; k > 0; k /= 2)
for (int j = 0; j < k; j++)
for (int i = k % p; i + k < n; i += k + k)
if ((i + j)/(p + p) == (i + j + k)/(p + p))
printf("%2i cmp %2i\n", i + j, i + j + k);
}
我正在搜索非递归奇偶合并排序算法并找到了 2 个来源:
- 来自 Sedgewick R. 的一本书
- 这个SO question
两种算法相同但都是错误的。生成的排序网络不是奇偶合并排序网络。
这是具有 32 个输入的生成网络的图像。两条水平线之间的垂直线表示比较值 a[x] 和 a[y],如果更大则交换数组中的值。
(来源:flylib.com)
(可点击)
{kind=link}
我将代码从 Java 复制到 C 并将 exch 函数替换为 printf 以打印交换候选人。
画对图时,可以看出生成的对太多了。
有人知道如何修正这个算法吗?
为什么我需要非递归版本?
我想把这个分拣网络改造成硬件。将流水线阶段插入非递归算法很容易。
我也研究了递归版本,但是将算法转换为流水线硬件太复杂了。
我的C代码:
#include <stdlib.h>
#include <stdio.h>
void sort(int l, int r)
{ int n = r-l+1;
for (int p=1; p<n; p+=p)
for (int k=p; k>0; k/=2)
for (int j=k%p; j+k<n; j+=(k+k))
for (int i=0; i<n-j-k; i++)
if ((j+i)/(p+p) == (j+i+k)/(p+p))
printf("%2i cmp %2i\n", l+j+i, l+j+i+k);
}
int main(char* argv, int args)
{ const int COUNT = 8;
sort(0, COUNT);
}
结果:
0 -o--------o-------------------------o---------------o-------------------------
| | | |
1 -o--------|-o------o----------------|-o-------------o-o-----------------------
| | | | | |
2 -o-o------o-|------o-o--------------|-|-o----o--------o-o---------------------
| | | | | | | | |
3 -o-o--------o--------o--------------|-|-|-o--|-o--------o-o-------o-----------
| | | | | | | |
4 -o-o-o----o---o----o-----o----------o-|-|-|--o-|-o--------o-o-----o-o---------
| | | | | | | | | | | | | |
5 -o-o-o----|-o-|-o--o-o---o-o---o------o-|-|----o-|-o--------o-o-----o-o---o---
| | | | | | | | | | | | | |
6 -o-o-o-o--o-|-o-|----o-o---o-o-o-o------o-|------o-|----------o-o-----o-o-o-o-
| | | | | | | | | | | | | |
7 -o-o-o-o----o---o------o-----o---o--------o--------o------------o-------o---o-
当我知道正确的交换对并且算法等于图像时,我会把它翻译成VHDL在我的硬件平台上测试。
其他开源硬件排序网络实现:
附录:
奇偶合并排序(a.k.a Batcher 的排序)就像双调排序(不要与 Batcher 的双调排序混淆)。但是在硬件上,这个算法比双调排序有更好的大小复杂度,而延迟是相同的。
与快速排序等快速软件算法相比,这些算法可以在资源利用率良好的情况下实现。
维基百科:odd-even mergesort
注:
因为排序网络是静态的并且独立于输入值,所以不需要比较和交换来生成网络。这就是它可以转化为硬件的原因之一。我的代码为比较操作生成索引。在硬件中,这些垂直连接将被比较和交换电路所取代。因此,未排序的数据将通过网络传输,并在输出端进行排序。
我想我找到了解决办法。我检查了 length = 2, 4, 8, 16。
这是我的代码:
void sort(int length)
{ int G = log2ceil(length); // number of groups
for (int g = 0; g < G; g++) // iterate groups
{ int B = 1 << (G - g - 1); // number of blocks
for (int b = 0; b < B; b++) // iterate blocks in a group
{ for (int s = 0; s <= g; s++) // iterate stages in a block
{ int d = 1 << (g - s); // compare distance
int J = (s == 0) ? 0 : d; // starting point
for (int j = J; j+d < (2<<g); j += 2*d) // iterate startpoints
{ for (int i = 0; i < d; i++) // shift startpoints
{ int x = (b * (length / B)) + j + i; // index 1
int y = x + d; // index 2
printf("%2i cmp %2i\n", x, y);
}
}
}
}
}
此解决方案引入了第五个 for 循环来处理组中的子块。 j 循环更改了开始和中止值,以处理 post 合并步骤的奇数计数,而不会生成双倍比较步骤。
以下代码适用于任何大小的数组并且不是递归的。它是 Perl 的 Algorithm::Networksort 模块中 the corresponding function 实现的直接移植。该实现恰好对应于 Knuth 在 计算机编程艺术,第 3 卷 中描述的算法(算法 5.2.2M)。它对实际修复您的算法没有帮助,但它至少为您提供了 Batcher 的奇偶合并排序的有效非递归实现,只有三个嵌套循环:)
#include <math.h>
#include <stdio.h>
void oddeven_merge_sort(int length)
{
int t = ceil(log2(length));
int p = pow(2, t - 1);
while (p > 0) {
int q = pow(2, t - 1);
int r = 0;
int d = p;
while (d > 0) {
for (int i = 0 ; i < length - d ; ++i) {
if ((i & p) == r) {
printf("%2i cmp %2i\n", i, i + d);
}
}
d = q - p;
q /= 2;
r = p;
}
p /= 2;
}
}
如果你能拿到一本 计算机编程艺术,第 3 卷,你也会很好地解释算法的工作原理和原因作为一些额外的细节。
这是一个固定的非递归子程序。
void sort(int n)
{
for (int p = 1; p < n; p += p)
for (int k = p; k > 0; k /= 2)
for (int j = k % p; j + k < n; j += k + k)
//for (int i = 0; i < n - (j + k); i++) // wrong
for (int i = 0; i < k; i++) // correct
if ((i + j)/(p + p) == (i + j + k)/(p + p))
printf("%2i cmp %2i\n", i + j, i + j + k);
}
或
void sort(int n)
{
for (int p = 1; p < n; p += p)
for (int k = p; k > 0; k /= 2)
for (int j = 0; j < k; j++)
for (int i = k % p; i + k < n; i += k + k)
if ((i + j)/(p + p) == (i + j + k)/(p + p))
printf("%2i cmp %2i\n", i + j, i + j + k);
}