如何在不使用浏览器的情况下获取此表单数据?
How to get this form data without using browser?
我是 python 的新手,我认为最好的学习方法是实践,这是我的第一个项目。
所以就有了这个梦幻足球网站。我的目标是创建登录站点的脚本,自动创建预选团队并提交。
我已成功提交团队部分。
当我添加团队成员时,此数据会发送到服务器:
https://i.gyazo.com/e7e6f82ca91e19a08d1522b93a55719b.png
当我按下保存此列表时,会发送此数据:
https://i.gyazo.com/546d49d1f132eabc5e6f659acf7c929e.png
代码:
import requests
with requests.Session() as c:
gameurl = 'here is link where data is sent'
BPL = ['5388', '5596', '5481', '5587',
'5585', '5514', '5099', '5249', '5566', '5501', '5357']
GID = '168'
UDID = '0'
ACT = 'draft'
ACT2 = 'save_draft'
SIGN = '18852c5f48a94bf3ee58057ff5c016af'
# eleven of those with different BPL since 11 players needed:
c.get(gameurl)
game_data = dict(player_id = BPL[0], action = ACT, id = GID)
c.post(gameurl, data = game_data)
# now I need to submit my list of selected players:
game_data_save = dict( action = ACT2, id = GID, user_draft_id = UDID, sign = SIGN)
c.post(gameurl, data = game_data_save)
这段代码工作得很好,但问题是,'SIGN' 对于每个游戏都是独一无二的,我不知道如何在不使用 Chromes 检查选项的情况下获取这些数据。
如何通过 运行 python 代码获取这些数据?
因为你说你可以使用 devtools 找到它我假设 SIGN 写在 DOM 的某个地方。
在这种情况下,您可以使用 requests.get().text 获取页面的 HTML 并使用 lxml or HTMLParser
之类的工具对其进行解析
通过在没有 'SIGN' 和 return 的情况下发布所有数据来解决我在 html.
中得到了 'SIGN'
我是 python 的新手,我认为最好的学习方法是实践,这是我的第一个项目。
所以就有了这个梦幻足球网站。我的目标是创建登录站点的脚本,自动创建预选团队并提交。
我已成功提交团队部分。
当我添加团队成员时,此数据会发送到服务器:
https://i.gyazo.com/e7e6f82ca91e19a08d1522b93a55719b.png
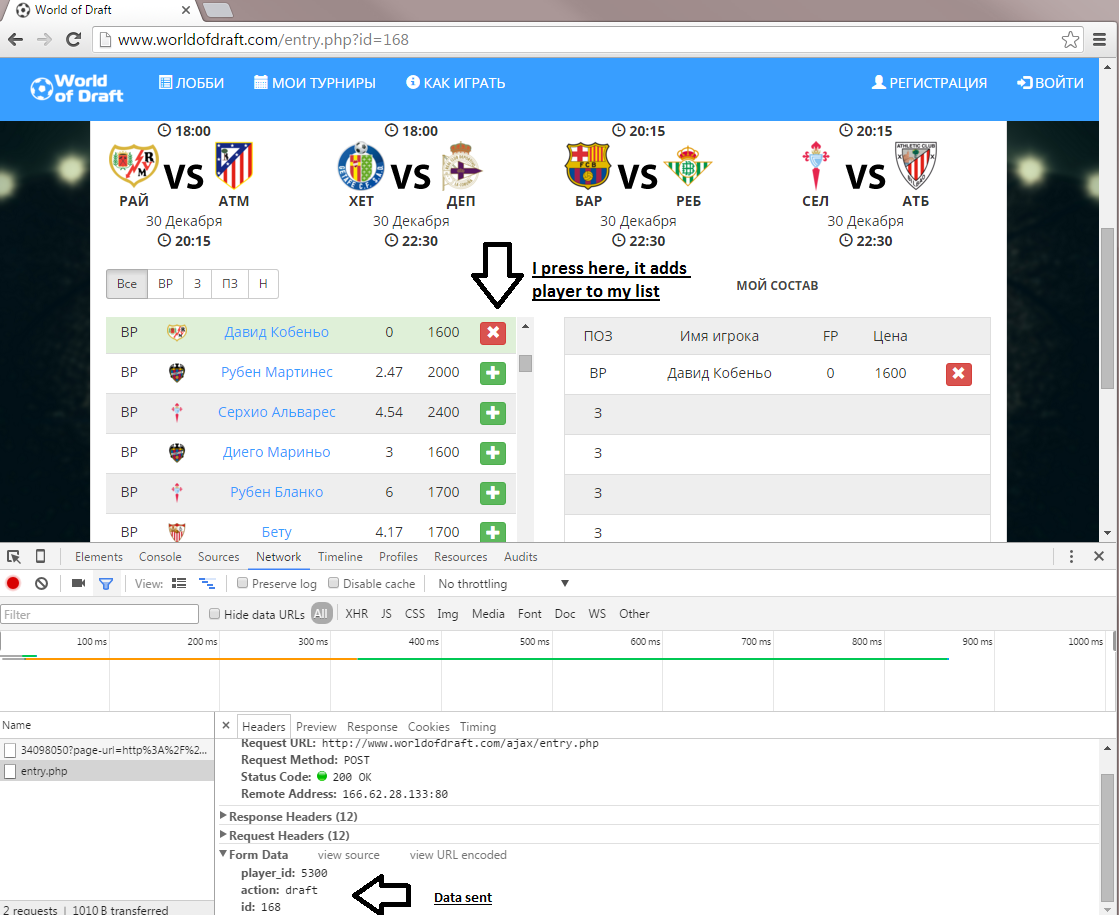{kind=link}
当我按下保存此列表时,会发送此数据:
https://i.gyazo.com/546d49d1f132eabc5e6f659acf7c929e.png
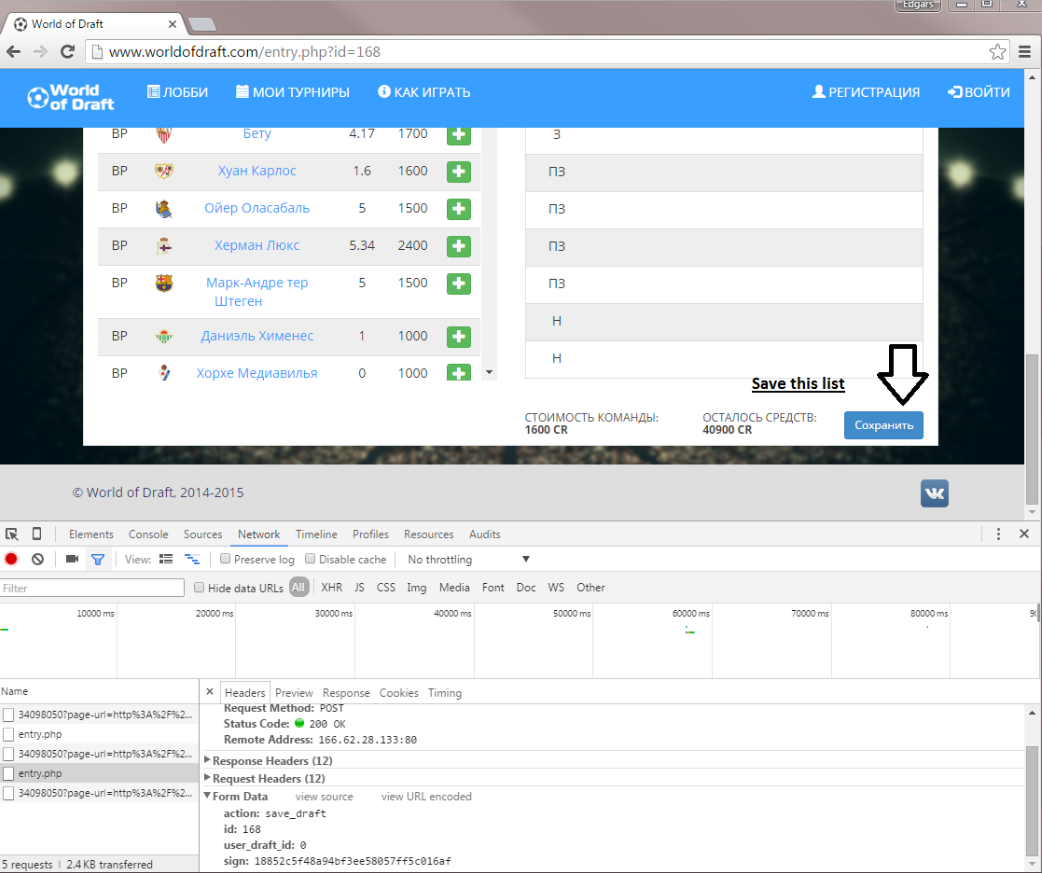{kind=link}
代码:
import requests
with requests.Session() as c:
gameurl = 'here is link where data is sent'
BPL = ['5388', '5596', '5481', '5587',
'5585', '5514', '5099', '5249', '5566', '5501', '5357']
GID = '168'
UDID = '0'
ACT = 'draft'
ACT2 = 'save_draft'
SIGN = '18852c5f48a94bf3ee58057ff5c016af'
# eleven of those with different BPL since 11 players needed:
c.get(gameurl)
game_data = dict(player_id = BPL[0], action = ACT, id = GID)
c.post(gameurl, data = game_data)
# now I need to submit my list of selected players:
game_data_save = dict( action = ACT2, id = GID, user_draft_id = UDID, sign = SIGN)
c.post(gameurl, data = game_data_save)
这段代码工作得很好,但问题是,'SIGN' 对于每个游戏都是独一无二的,我不知道如何在不使用 Chromes 检查选项的情况下获取这些数据。
如何通过 运行 python 代码获取这些数据?
因为你说你可以使用 devtools 找到它我假设 SIGN 写在 DOM 的某个地方。
在这种情况下,您可以使用 requests.get().text 获取页面的 HTML 并使用 lxml or HTMLParser
通过在没有 'SIGN' 和 return 的情况下发布所有数据来解决我在 html.
中得到了 'SIGN'