如何解释机器学习模型的损失和准确性
How to interpret loss and accuracy for a machine learning model
当我用 Theano 或 Tensorflow 训练我的神经网络时,它们会在每个时期报告一个名为 "loss" 的变量。
我应该如何解释这个变量?更高的损失是好是坏,或者它对我的神经网络的最终性能(准确性)意味着什么?
损失越低,模型越好(除非模型对训练数据有over-fitted)。损失是在 training 和 validation 上计算的,它的解释是模型对这两个集合的表现。与准确性不同,损失不是百分比。它是训练或验证集中每个示例所犯错误的总和。
对于神经网络,分类和回归的损失通常分别为 negative log-likelihood and residual sum of squares。那么自然地,学习模型中的主要 objective 是通过不同的优化方法(例如神经网络中的反向传播)改变权重向量值来减少(最小化)损失函数相对于模型参数的值。
损失值表示某个模型在每次优化迭代后的表现好坏。理想情况下,人们会期望在每次或几次迭代后减少损失。
模型的准确率通常是在学习并固定模型参数并且没有进行学习之后确定的。然后将测试样本输入模型,并在与真实目标进行比较后记录模型所犯错误的数量(zero-one 损失)。然后计算错误分类的百分比。
例如,如果测试样本的数量为 1000,模型正确分类了其中的 952 个,则模型的准确率为 95.2%。
降低损失值的同时也有一些细微之处。比如你可能运行变成了over-fitting in which the model "memorizes" the training examples and becomes kind of ineffective for the test set. Over-fitting also occurs in cases where you do not employ a regularization的问题,你的模型很复杂(自由参数的数量W很大)或者数据点的数量N 很低。
它们是评估模型性能的两个不同指标,通常用于不同阶段。
损失通常在训练过程中用于查找模型的 "best" 参数值(例如神经网络中的权重)。这是你在训练中尝试通过更新权重来优化的。
准确性更多的是从应用的角度。找到上面的优化参数后,您可以使用此指标来评估模型预测与真实数据相比的准确性。
让我们用一个玩具分类的例子。你想根据一个人的体重和身高来预测性别。你有3个数据,分别是:(0代表男,1代表女)
y1=0,x1_w=50kg,x2_h=160cm;
y2=0,x2_w=60kg,x2_h=170cm;
y3=1,x3_w=55kg,x3_h=175cm;
您使用简单的逻辑回归模型,即 y = 1/(1+exp-(b1*x_w+b2*x_h))
你是怎么找到b1和b2的?您首先定义损失并使用优化方法通过更新 b1 和 b2 以迭代方式最小化损失。
在我们的示例中,此二元分类问题的典型损失可以是:
(求和号前要加负号)
我们不知道 b1 和 b2 应该是什么。让我们随机猜测 b1 = 0.1 和 b2 = -0.03。那我们现在的损失是多少?
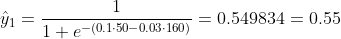
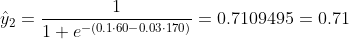
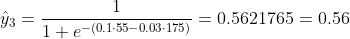
所以损失是
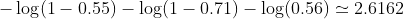
然后你学习算法(例如梯度下降)会找到一种方法来更新 b1 和 b2 以减少损失。
如果b1=0.1和b2=-0.03是最终的b1和b2(梯度下降的输出),那么现在的准确率是多少?
让我们假设如果 y_hat >= 0.5,我们决定我们的预测是 female(1)。否则为 0。因此,我们的算法预测 y1 = 1、y2 = 1 和 y3 = 1。我们的准确度是多少?我们对 y1 和 y2 做出了错误的预测,而对 y3 做出了正确的预测。所以现在我们的准确率是 1/3 = 33.33%
PS:在中,据说反向传播是神经网络中的一种优化方法。我认为这将被视为一种在神经网络中寻找权重梯度的方法。 NN中常用的优化方法有GradientDescent和Adam。
只是为了澄清 Training/Validation/Test 数据集:
训练集用于进行模型的初始训练,初始化神经网络的权重。
验证集在神经网络训练完成后使用。它用于调整网络的超参数,并比较它们的变化如何影响模型的预测准确性。训练集可以被认为是用于构建神经网络的门权重,而验证集允许微调神经网络模型的参数或架构。它很有用,因为它允许将这些不同的 parameters/architectures 与相同的数据和网络权重进行重复比较,以观察 parameter/architecture 变化如何影响网络的预测能力。
然后测试集仅用于测试经过训练的神经网络对以前未见过的数据的预测准确性,在训练和 parameter/architecture 选择训练和验证数据集之后。
当我用 Theano 或 Tensorflow 训练我的神经网络时,它们会在每个时期报告一个名为 "loss" 的变量。
我应该如何解释这个变量?更高的损失是好是坏,或者它对我的神经网络的最终性能(准确性)意味着什么?
损失越低,模型越好(除非模型对训练数据有over-fitted)。损失是在 training 和 validation 上计算的,它的解释是模型对这两个集合的表现。与准确性不同,损失不是百分比。它是训练或验证集中每个示例所犯错误的总和。
对于神经网络,分类和回归的损失通常分别为 negative log-likelihood and residual sum of squares。那么自然地,学习模型中的主要 objective 是通过不同的优化方法(例如神经网络中的反向传播)改变权重向量值来减少(最小化)损失函数相对于模型参数的值。
损失值表示某个模型在每次优化迭代后的表现好坏。理想情况下,人们会期望在每次或几次迭代后减少损失。
模型的准确率通常是在学习并固定模型参数并且没有进行学习之后确定的。然后将测试样本输入模型,并在与真实目标进行比较后记录模型所犯错误的数量(zero-one 损失)。然后计算错误分类的百分比。
例如,如果测试样本的数量为 1000,模型正确分类了其中的 952 个,则模型的准确率为 95.2%。
降低损失值的同时也有一些细微之处。比如你可能运行变成了over-fitting in which the model "memorizes" the training examples and becomes kind of ineffective for the test set. Over-fitting also occurs in cases where you do not employ a regularization的问题,你的模型很复杂(自由参数的数量W很大)或者数据点的数量N 很低。
它们是评估模型性能的两个不同指标,通常用于不同阶段。
损失通常在训练过程中用于查找模型的 "best" 参数值(例如神经网络中的权重)。这是你在训练中尝试通过更新权重来优化的。
准确性更多的是从应用的角度。找到上面的优化参数后,您可以使用此指标来评估模型预测与真实数据相比的准确性。
让我们用一个玩具分类的例子。你想根据一个人的体重和身高来预测性别。你有3个数据,分别是:(0代表男,1代表女)
y1=0,x1_w=50kg,x2_h=160cm;
y2=0,x2_w=60kg,x2_h=170cm;
y3=1,x3_w=55kg,x3_h=175cm;
您使用简单的逻辑回归模型,即 y = 1/(1+exp-(b1*x_w+b2*x_h))
你是怎么找到b1和b2的?您首先定义损失并使用优化方法通过更新 b1 和 b2 以迭代方式最小化损失。
在我们的示例中,此二元分类问题的典型损失可以是: (求和号前要加负号)
我们不知道 b1 和 b2 应该是什么。让我们随机猜测 b1 = 0.1 和 b2 = -0.03。那我们现在的损失是多少?
所以损失是
然后你学习算法(例如梯度下降)会找到一种方法来更新 b1 和 b2 以减少损失。
如果b1=0.1和b2=-0.03是最终的b1和b2(梯度下降的输出),那么现在的准确率是多少?
让我们假设如果 y_hat >= 0.5,我们决定我们的预测是 female(1)。否则为 0。因此,我们的算法预测 y1 = 1、y2 = 1 和 y3 = 1。我们的准确度是多少?我们对 y1 和 y2 做出了错误的预测,而对 y3 做出了正确的预测。所以现在我们的准确率是 1/3 = 33.33%
PS:在
只是为了澄清 Training/Validation/Test 数据集: 训练集用于进行模型的初始训练,初始化神经网络的权重。
验证集在神经网络训练完成后使用。它用于调整网络的超参数,并比较它们的变化如何影响模型的预测准确性。训练集可以被认为是用于构建神经网络的门权重,而验证集允许微调神经网络模型的参数或架构。它很有用,因为它允许将这些不同的 parameters/architectures 与相同的数据和网络权重进行重复比较,以观察 parameter/architecture 变化如何影响网络的预测能力。
然后测试集仅用于测试经过训练的神经网络对以前未见过的数据的预测准确性,在训练和 parameter/architecture 选择训练和验证数据集之后。