查询 MongoDB(使用 Edge Collection - 最有效的方法?)
Querying MongoDB (Using Edge Collection - The most efficient way?)
为了下面的示例,我编写了用户、俱乐部和关注者 collection。
我想从用户 collection 中找到所有跟随 "A famous club" 的用户文档。 我怎样才能找到那些?哪种方式最快?
有关“what do I want to do - Edge collections”的更多信息
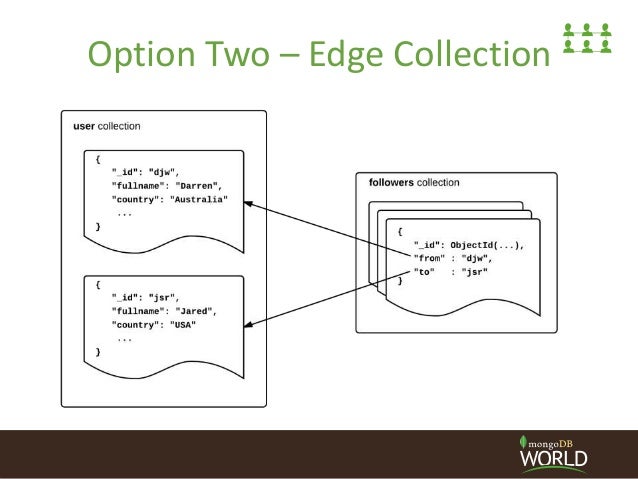
用户collection
{
"_id": "1",
"fullname": "Jared",
"country": "USA"
}
俱乐部collection
{
"_id": "12",
"name": "A famous club"
}
关注者collection
{
"_id": "159",
"user_id": "1",
"club_id": "12"
}
PS:我可以通过如下方式使用 Mongoose 获取文档。但是,创建 followers 数组大约需要 8 秒,包含 150.000 条记录。第二个 find 查询 - 使用 followers 数组查询 - 需要 大约 40 秒 。正常吗?
Clubs.find(
{ club_id: "12" },
'-_id user_id', // select only one field to better perf.
function(err, docs){
var followers = [];
docs.forEach(function(item){
followers.push(item.user_id)
})
Users.find(
{ _id:{ $in: followers } },
function(error, users) {
console.log(users) // RESULTS
})
})
没有符合条件的公式来操纵 MongoDB 上的联接 many-to-many 关系。所以我将 collections 合并为嵌入文档,如下所示。但在这种情况下最重要的任务 创建索引 。例如,如果你想通过 followingClubs 查询,你应该使用 Mongoose 创建一个像 schema.index({ 'followingClubs._id':1 }) 这样的索引。如果你想查询 country 和 followingClubs 你应该创建另一个索引,比如 schema.index({ 'country':1, 'followingClubs._id':1 })
使用嵌入式文档时要注意:http://askasya.com/post/largeembeddedarrays
然后你就可以快速拿到你的文件了。我试图用这种方式计算 150.000 条记录,只用了 1 秒。对我来说够了...
ps:我们不能忘记在我的测试中我的Userscollection从未经历过任何数据碎片。因此,我的查询可能表现出良好的性能。特别是,followingClubs 嵌入文档数组。
用户collection
{
"_id": "1",
"fullname": "Jared",
"country": "USA",
"followingClubs": [ {"_id": "12"} ]
}
俱乐部collection
{
"_id": "12",
"name": "A famous club"
}
为了下面的示例,我编写了用户、俱乐部和关注者 collection。 我想从用户 collection 中找到所有跟随 "A famous club" 的用户文档。 我怎样才能找到那些?哪种方式最快?
有关“what do I want to do - Edge collections”的更多信息
{kind=link}
用户collection
{
"_id": "1",
"fullname": "Jared",
"country": "USA"
}
俱乐部collection
{
"_id": "12",
"name": "A famous club"
}
关注者collection
{
"_id": "159",
"user_id": "1",
"club_id": "12"
}
PS:我可以通过如下方式使用 Mongoose 获取文档。但是,创建 followers 数组大约需要 8 秒,包含 150.000 条记录。第二个 find 查询 - 使用 followers 数组查询 - 需要 大约 40 秒 。正常吗?
Clubs.find(
{ club_id: "12" },
'-_id user_id', // select only one field to better perf.
function(err, docs){
var followers = [];
docs.forEach(function(item){
followers.push(item.user_id)
})
Users.find(
{ _id:{ $in: followers } },
function(error, users) {
console.log(users) // RESULTS
})
})
没有符合条件的公式来操纵 MongoDB 上的联接 many-to-many 关系。所以我将 collections 合并为嵌入文档,如下所示。但在这种情况下最重要的任务 创建索引 。例如,如果你想通过 followingClubs 查询,你应该使用 Mongoose 创建一个像 schema.index({ 'followingClubs._id':1 }) 这样的索引。如果你想查询 country 和 followingClubs 你应该创建另一个索引,比如 schema.index({ 'country':1, 'followingClubs._id':1 })
使用嵌入式文档时要注意:http://askasya.com/post/largeembeddedarrays
然后你就可以快速拿到你的文件了。我试图用这种方式计算 150.000 条记录,只用了 1 秒。对我来说够了...
ps:我们不能忘记在我的测试中我的Userscollection从未经历过任何数据碎片。因此,我的查询可能表现出良好的性能。特别是,followingClubs 嵌入文档数组。
用户collection
{
"_id": "1",
"fullname": "Jared",
"country": "USA",
"followingClubs": [ {"_id": "12"} ]
}
俱乐部collection
{
"_id": "12",
"name": "A famous club"
}