statsmodels:一起打印多个回归模型的摘要
statsmodels: printing summary of more than one regression models together
在Python库Statsmodels中,可以用print(results.summary())打印出回归结果,如何在一个[=32中打印出多个回归的摘要=],为了更好的比较?
线性回归,代码取自 statsmodels 文档:
nsample = 100
x = np.linspace(0, 10, 100)
X = np.column_stack((x, x**2))
beta = np.array([0.1, 10])
e = np.random.normal(size=nsample)
y = np.dot(X, beta) + e
model = sm.OLS(y, X)
results_noconstant = model.fit()
然后我向模型添加一个常量并再次 运行 回归:
beta = np.array([1, 0.1, 10])
X = sm.add_constant(X)
y = np.dot(X, beta) + e
model = sm.OLS(y, X)
results_withconstant = model.fit()
我希望看到 results_noconstant 和 results_withconstant 的摘要打印在一个 table 中。这应该是一个非常有用的功能,但我在 statsmodels 文档中没有找到任何关于此的说明。
编辑:回归table我想到的是this,我想知道是否有现成的功能可以做到这一点.
我相信有很多方法可以做到这一点。取决于你能/想用什么来实现。
起点很可能相同:
statsmodels 'linear_model'.fit() returns RegressionResults class,其中有 summary2() 方法返回 subclass 一些方便的方法。
其中一个,例如.tables returns pandas.DataFrame。
以下是您的使用方法:
import pandas as pd
results = {'Noconst':results_noconstant.summary2(),
'withcon':results_withconstant.summary2()}
df = pd.DataFrame({'Model':[], 'Param':[], 'Value':[]})
for mod in results.keys():
for col in results[mod].tables[0].columns:
if col % 2 == 0:
df = df.append(pd.DataFrame({'Model': [mod]*results[mod].tables[0][col].size,
'Param':results[mod].tables[0][col].values,
'Value':results[mod].tables[0][col+1].values}))
print df
产生:
Model Param Value
0 Noconst Model: OLS
1 Noconst Dependent Variable: y
2 Noconst Date: 2016-01-29 00:33
3 Noconst No. Observations: 100
4 Noconst Df Model: 2
5 Noconst Df Residuals: 98
6 Noconst R-squared: 1.000
0 Noconst Adj. R-squared: 1.000
1 Noconst AIC: 296.0102
2 Noconst BIC: 301.2205
3 Noconst Log-Likelihood: -146.01
4 Noconst F-statistic: 9.182e+06
5 Noconst Prob (F-statistic): 4.33e-259
6 Noconst Scale: 1.1079
0 withcon Model: OLS
1 withcon Dependent Variable: y
2 withcon Date: 2016-01-29 00:33
3 withcon No. Observations: 100
4 withcon Df Model: 2
5 withcon Df Residuals: 97
6 withcon R-squared: 1.000
0 withcon Adj. R-squared: 1.000
1 withcon AIC: 297.8065
2 withcon BIC: 305.6220
3 withcon Log-Likelihood: -145.90
4 withcon F-statistic: 4.071e+06
5 withcon Prob (F-statistic): 1.55e-239
6 withcon Scale: 1.1170
你能用它做什么只受限于你使用 pandas - powerful Python data analysis toolkit.
的能力
文档中仍然缺少 summary_col,AFAIR。
我并没有真正尝试太多,但我从一个问题中找到了一个相关示例来删除一些 "nuisance" 参数。
"""
mailing list, and issue https://github.com/statsmodels/statsmodels/pull/1638
"""
import pandas as pd
import numpy as np
import string
import statsmodels.formula.api as smf
from statsmodels.iolib.summary2 import summary_col
df = pd.DataFrame({'A' : list(string.ascii_uppercase)*10,
'B' : list(string.ascii_lowercase)*10,
'C' : np.random.randn(260),
'D' : np.random.normal(size=260),
'E' : np.random.random_integers(0,10,260)})
m1 = smf.ols('E ~ D',data=df).fit()
m2 = smf.ols('E ~ D + C',data=df).fit()
m3 = smf.ols('E ~ D + C + B',data=df).fit()
m4 = smf.ols('E ~ D + C + B + A',data=df).fit()
print(summary_col([m1,m2,m3,m4]))
还有改进的空间
这是一个可能的实现:
import pandas as pd
def compare_statsmodels_ols(estimators, indice=0):
if indice in [0, 2]:
data_dict = {}
if len(estimators) > 1:
for k, est in estimators.iteritems():
data_dict[k] = est.summary2().tables[indice].iloc[:, 1::2].stack().values
index = estimators.popitem()[1].summary2().tables[indice].iloc[:, 0::2].stack().values
df = pd.DataFrame.from_dict(data_dict)
df.index = index
return df
else:
raise 'waiting for a dictionnary for estimators parameter'
else:
raise 'Not working for the coeff table'
estimators = {'m1': m1, 'm2': m2 }
compare_stats_models(estimators, 0)
其中 m1 和 m2 是预装模型。
此解决方案仅适用于第一个(索引=0)和第三个(索引=2)ols 汇总表。
输出:
<table border="1" class="dataframe"> <thead> <tr style="text-align: right;"> <th></th> <th>m1</th> <th>m2</th> </tr> </thead> <tbody> <tr> <th>Model:</th> <td>OLS</td> <td>OLS</td> </tr> <tr> <th>Adj. R-squared:</th> <td>0.882</td> <td>0.864</td> </tr> <tr> <th>Dependent Variable:</th> <td>Mpg</td> <td>Mpg</td> </tr> <tr> <th>AIC:</th> <td>254.6367</td> <td>273.3427</td> </tr> <tr> <th>Date:</th> <td>2016-12-14 16:28</td> <td>2016-12-14 16:28</td> </tr> <tr> <th>BIC:</th> <td>389.3848</td> <td>310.7728</td> </tr> <tr> <th>No. Observations:</th> <td>312</td> <td>312</td> </tr> <tr> <th>Log-Likelihood:</th> <td>-91.318</td> <td>-126.67</td> </tr> <tr> <th>Df Model:</th> <td>35</td> <td>9</td> </tr> <tr> <th>F-statistic:</th> <td>67.12</td> <td>220.9</td> </tr> <tr> <th>Df Residuals:</th> <td>276</td> <td>302</td> </tr> <tr> <th>Prob (F-statistic):</th> <td>1.06e-114</td> <td>3.28e-127</td> </tr> <tr> <th>R-squared:</th> <td>0.895</td> <td>0.868</td> </tr> <tr> <th>Scale:</th> <td>0.11885</td> <td>0.13624</td> </tr> </tbody></table>
现在有一个 Python version 众所周知的 stargazer R 包,它就是这样做的。
在Python库Statsmodels中,可以用print(results.summary())打印出回归结果,如何在一个[=32中打印出多个回归的摘要=],为了更好的比较?
线性回归,代码取自 statsmodels 文档:
nsample = 100
x = np.linspace(0, 10, 100)
X = np.column_stack((x, x**2))
beta = np.array([0.1, 10])
e = np.random.normal(size=nsample)
y = np.dot(X, beta) + e
model = sm.OLS(y, X)
results_noconstant = model.fit()
然后我向模型添加一个常量并再次 运行 回归:
beta = np.array([1, 0.1, 10])
X = sm.add_constant(X)
y = np.dot(X, beta) + e
model = sm.OLS(y, X)
results_withconstant = model.fit()
我希望看到 results_noconstant 和 results_withconstant 的摘要打印在一个 table 中。这应该是一个非常有用的功能,但我在 statsmodels 文档中没有找到任何关于此的说明。
编辑:回归table我想到的是this,我想知道是否有现成的功能可以做到这一点.
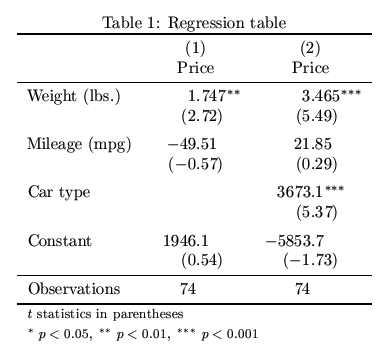{kind=link}
我相信有很多方法可以做到这一点。取决于你能/想用什么来实现。
起点很可能相同:
statsmodels 'linear_model'.fit() returns RegressionResults class,其中有 summary2() 方法返回 subclass 一些方便的方法。
其中一个,例如.tables returns pandas.DataFrame。
以下是您的使用方法:
import pandas as pd
results = {'Noconst':results_noconstant.summary2(),
'withcon':results_withconstant.summary2()}
df = pd.DataFrame({'Model':[], 'Param':[], 'Value':[]})
for mod in results.keys():
for col in results[mod].tables[0].columns:
if col % 2 == 0:
df = df.append(pd.DataFrame({'Model': [mod]*results[mod].tables[0][col].size,
'Param':results[mod].tables[0][col].values,
'Value':results[mod].tables[0][col+1].values}))
print df
产生:
Model Param Value
0 Noconst Model: OLS
1 Noconst Dependent Variable: y
2 Noconst Date: 2016-01-29 00:33
3 Noconst No. Observations: 100
4 Noconst Df Model: 2
5 Noconst Df Residuals: 98
6 Noconst R-squared: 1.000
0 Noconst Adj. R-squared: 1.000
1 Noconst AIC: 296.0102
2 Noconst BIC: 301.2205
3 Noconst Log-Likelihood: -146.01
4 Noconst F-statistic: 9.182e+06
5 Noconst Prob (F-statistic): 4.33e-259
6 Noconst Scale: 1.1079
0 withcon Model: OLS
1 withcon Dependent Variable: y
2 withcon Date: 2016-01-29 00:33
3 withcon No. Observations: 100
4 withcon Df Model: 2
5 withcon Df Residuals: 97
6 withcon R-squared: 1.000
0 withcon Adj. R-squared: 1.000
1 withcon AIC: 297.8065
2 withcon BIC: 305.6220
3 withcon Log-Likelihood: -145.90
4 withcon F-statistic: 4.071e+06
5 withcon Prob (F-statistic): 1.55e-239
6 withcon Scale: 1.1170
你能用它做什么只受限于你使用 pandas - powerful Python data analysis toolkit.
的能力文档中仍然缺少 summary_col,AFAIR。
我并没有真正尝试太多,但我从一个问题中找到了一个相关示例来删除一些 "nuisance" 参数。
"""
mailing list, and issue https://github.com/statsmodels/statsmodels/pull/1638
"""
import pandas as pd
import numpy as np
import string
import statsmodels.formula.api as smf
from statsmodels.iolib.summary2 import summary_col
df = pd.DataFrame({'A' : list(string.ascii_uppercase)*10,
'B' : list(string.ascii_lowercase)*10,
'C' : np.random.randn(260),
'D' : np.random.normal(size=260),
'E' : np.random.random_integers(0,10,260)})
m1 = smf.ols('E ~ D',data=df).fit()
m2 = smf.ols('E ~ D + C',data=df).fit()
m3 = smf.ols('E ~ D + C + B',data=df).fit()
m4 = smf.ols('E ~ D + C + B + A',data=df).fit()
print(summary_col([m1,m2,m3,m4]))
还有改进的空间
这是一个可能的实现:
import pandas as pd
def compare_statsmodels_ols(estimators, indice=0):
if indice in [0, 2]:
data_dict = {}
if len(estimators) > 1:
for k, est in estimators.iteritems():
data_dict[k] = est.summary2().tables[indice].iloc[:, 1::2].stack().values
index = estimators.popitem()[1].summary2().tables[indice].iloc[:, 0::2].stack().values
df = pd.DataFrame.from_dict(data_dict)
df.index = index
return df
else:
raise 'waiting for a dictionnary for estimators parameter'
else:
raise 'Not working for the coeff table'
estimators = {'m1': m1, 'm2': m2 }
compare_stats_models(estimators, 0)
其中 m1 和 m2 是预装模型。 此解决方案仅适用于第一个(索引=0)和第三个(索引=2)ols 汇总表。
输出:
<table border="1" class="dataframe"> <thead> <tr style="text-align: right;"> <th></th> <th>m1</th> <th>m2</th> </tr> </thead> <tbody> <tr> <th>Model:</th> <td>OLS</td> <td>OLS</td> </tr> <tr> <th>Adj. R-squared:</th> <td>0.882</td> <td>0.864</td> </tr> <tr> <th>Dependent Variable:</th> <td>Mpg</td> <td>Mpg</td> </tr> <tr> <th>AIC:</th> <td>254.6367</td> <td>273.3427</td> </tr> <tr> <th>Date:</th> <td>2016-12-14 16:28</td> <td>2016-12-14 16:28</td> </tr> <tr> <th>BIC:</th> <td>389.3848</td> <td>310.7728</td> </tr> <tr> <th>No. Observations:</th> <td>312</td> <td>312</td> </tr> <tr> <th>Log-Likelihood:</th> <td>-91.318</td> <td>-126.67</td> </tr> <tr> <th>Df Model:</th> <td>35</td> <td>9</td> </tr> <tr> <th>F-statistic:</th> <td>67.12</td> <td>220.9</td> </tr> <tr> <th>Df Residuals:</th> <td>276</td> <td>302</td> </tr> <tr> <th>Prob (F-statistic):</th> <td>1.06e-114</td> <td>3.28e-127</td> </tr> <tr> <th>R-squared:</th> <td>0.895</td> <td>0.868</td> </tr> <tr> <th>Scale:</th> <td>0.11885</td> <td>0.13624</td> </tr> </tbody></table>
现在有一个 Python version 众所周知的 stargazer R 包,它就是这样做的。