基于 LSB-DCT 的图像隐写术
LSB-DCT based Image steganography
我正在研究基于 LSB-DCT 的图像隐写术,其中我必须将 LSB 应用于图像的 DCT 系数,以便将数据嵌入到 JPEG.i 对所有 this.so 搜索和读了一些研究论文后,他们都缺乏很多关于这个过程的信息 DCT.i 也读了很多关于 Whosebug 的问题和答案,变得更加困惑。
问题如下:
1-reasearch 论文和网络上的问题他们都使用图像的 8x8 块大小进行 DCT。如果图像的分辨率没有完全分成 8x8 块,如 724 x 520,我应该怎么做。
520 / 8 = 65 但 724 / 8 = 90.5
2-如果我有很多块和一些信息要隐藏,我们认为这些信息可以放入 5 个块中..我是否仍然需要对剩余的块进行 dct 和 idct。
3-我需要在dct之后应用量化然后应用lsb还是我可以直接应用lsb?
4 篇研究论文没有提到任何关于不接触值为 0 和 1 以及第一个值的量化 dct 系数..现在我应该使用它们吗?那么为何不??我知道它是关于 0 的,因为它是高频分量并且在 JPEG 中被删除以进行压缩..我没有做任何压缩..所以我可以使用它并仍然生成相同的 JPEG 文件吗???
5-in quantization 我们将 DCT 系数除以量化矩阵并四舍五入 values.in 反向,我必须将量化矩阵与 DCT 系数相乘只是..没有四舍五入的撤消???
关于DCT和IDCT的评论:
来自不同的研究论文:
JPEG 隐写术
如果要将图像保存为jpeg,则必须遵循jpeg 编码过程。不幸的是,我读过的大多数论文都说不公正。完整的流程如下(wiki summary of a 182-page specifications book):
- RGB 到 YCbCr 的转换(可选),
- 色度通道二次采样(可选),
- 8x8 块拆分,
- 像素值重新居中,
- DCT,
- 基于压缩的量化 ratio/quality,
- 以之字形排列系数,并且
- 熵编码;最常涉及霍夫曼编码和 运行 长度编码 (RLE)。
实际上有a lot more details involved, such as headers, section markers, specifics of how to store the DC and AC coefficients, etc. Then, there are aspects that the standard has only loosely defined and their implementation can vary between codecs, e.g., subsampling algorithm, quantisation tables and entropy encoding. That said, most pieces of software abide by the general JFIF standard and can be read by various software. If you want your jpeg file to do the same, be prepared to write hundreds (to about a thousand) lines of code just for an encoder. You're better off borrowing an encoder that has already been published on the internet than writing your own. You can start by looking into libjpeg which is written in C and forms the basis of many other jpeg codecs, its C# implementation or even a Java个版本受到它的启发。
在一些伪代码中,encoding/decoding过程可以描述如下。
function saveToJpeg(pixels, fileout) {
// pixels is a 2D or 3D array containing your raw pixel values
// blocks is a list of 2D arrays of size 8x8 each, containing pixel values
blocks = splitBlocks(pixels);
// a list similar to blocks, but for the DCT coefficients
coeffs = dct(blocks);
saveCoefficients(coeffs, fileout);
}
function loadJpeg(filein) {
coeffs = readCoefficients(filein);
blocks = idct(coeffs);
pixels = combineBlocks(blocks);
return pixels;
}
对于隐写术,您可以按如下方式修改它。
function embedSecretToJpeg(pixels, secret, fileout) {
blocks = splitBlocks(pixels);
coeffs = dct(blocks);
modified_coeffs = embedSecret(coeffs, secret);
saveCoefficients(modified_coeffs, fileout);
}
function extractSecretFromJpeg(filein) {
coeffs = readCoefficients(filein);
secret = extractSecret(coeffs);
return secret;
}
如果您的封面图片已经是 jpeg 格式,则无需使用解码器将其加载为像素,然后将其传递给编码器以嵌入您的信息。您可以改为执行此操作。
function embedSecretToJpeg(pixels, secret, filein, fileout) {
coeffs = readCoefficients(filein);
modified_coeffs = embedSecret(coeffs, secret);
saveCoefficients(modified_coeffs, fileout);
}
就您的问题而言,encoder/decoder 应该解决 1、2、3 和 5,除非您自己编写一个。
问题1:一般来说,你想用必要的数量rows/columns填充图像,这样宽度和高度都可以被8整除。在内部,编码器将跟踪填充的 rows/columns,以便解码器在重建后丢弃它们。这些虚拟 rows/columns 的像素值的选择由您决定,但建议您不要使用常量值,因为它会导致 ringing artifacts,这与以下事实有关:方波是 sinc 函数。
问题 2:虽然您只会修改几个块,但编码过程需要您将它们全部转换,以便将它们存储到文件中。
问题 3:您必须量化浮点 DCT 系数,因为这是无损存储到文件中的系数。您可以在量化步骤后根据自己的喜好修改它们。
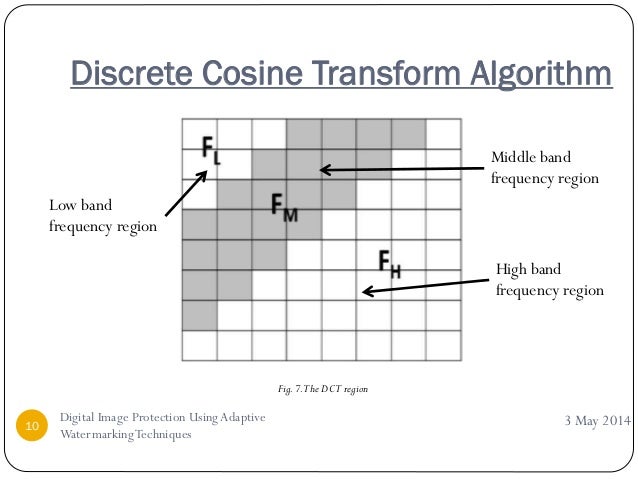
问题4:没有人阻止你修改任何系数,但你必须记住每个系数都会影响一个块中的所有64个像素。 DC 系数和 low frequency AC 会引入最大的失真,因此您可能希望远离它们。更具体地说,由于 DC 系数的存储方式,修改一个会将失真传播到所有后续块。
由于大多数高频系数为0,因此可以使用RLE对其进行有效压缩。修改 0 系数可能会将其翻转为 1(如果您正在进行基本的 LSB 替换),这会破坏这种有效的压缩。
最后,一些算法将它们的秘密存储在任何非零系数中并会跳过任何 0。但是,如果您尝试修改 1,它可能会翻转为 0,并且在提取过程中您会盲目地跳过读取它。因此,此类算法不会接近任何值为 1 或 0 的系数。
问题 5:在解码时,您只需将系数乘以相应的量化值 table。例如,DC 系数为 309.443,量化后得到 round(309.443 / 16) = 19。舍入位是这里的有损部分,它不允许您重建 309.433。所以反过来就是 19 * 16 = 304.
DCT 在隐写术中的其他用途
频率变换,例如 DCT 和 DWT 可用于隐写术以在频域中嵌入秘密,但不一定将隐写图像存储为 jpeg。这个过程是pixels -> DCT -> coefficients -> modify coefficients -> IDCT -> pixels,也就是你发给接收端的。因此,格式的选择在这里很重要。如果您决定将像素保存为 jpeg,则 DCT 系数中的秘密 通过来自 jpeg 编码的另一层量化。
我正在研究基于 LSB-DCT 的图像隐写术,其中我必须将 LSB 应用于图像的 DCT 系数,以便将数据嵌入到 JPEG.i 对所有 this.so 搜索和读了一些研究论文后,他们都缺乏很多关于这个过程的信息 DCT.i 也读了很多关于 Whosebug 的问题和答案,变得更加困惑。
问题如下:
1-reasearch 论文和网络上的问题他们都使用图像的 8x8 块大小进行 DCT。如果图像的分辨率没有完全分成 8x8 块,如 724 x 520,我应该怎么做。
520 / 8 = 65 但 724 / 8 = 90.5
2-如果我有很多块和一些信息要隐藏,我们认为这些信息可以放入 5 个块中..我是否仍然需要对剩余的块进行 dct 和 idct。
3-我需要在dct之后应用量化然后应用lsb还是我可以直接应用lsb?
4 篇研究论文没有提到任何关于不接触值为 0 和 1 以及第一个值的量化 dct 系数..现在我应该使用它们吗?那么为何不??我知道它是关于 0 的,因为它是高频分量并且在 JPEG 中被删除以进行压缩..我没有做任何压缩..所以我可以使用它并仍然生成相同的 JPEG 文件吗???
5-in quantization 我们将 DCT 系数除以量化矩阵并四舍五入 values.in 反向,我必须将量化矩阵与 DCT 系数相乘只是..没有四舍五入的撤消???
关于DCT和IDCT的评论:
来自不同的研究论文:
JPEG 隐写术
如果要将图像保存为jpeg,则必须遵循jpeg 编码过程。不幸的是,我读过的大多数论文都说不公正。完整的流程如下(wiki summary of a 182-page specifications book):
- RGB 到 YCbCr 的转换(可选),
- 色度通道二次采样(可选),
- 8x8 块拆分,
- 像素值重新居中,
- DCT,
- 基于压缩的量化 ratio/quality,
- 以之字形排列系数,并且
- 熵编码;最常涉及霍夫曼编码和 运行 长度编码 (RLE)。
实际上有a lot more details involved, such as headers, section markers, specifics of how to store the DC and AC coefficients, etc. Then, there are aspects that the standard has only loosely defined and their implementation can vary between codecs, e.g., subsampling algorithm, quantisation tables and entropy encoding. That said, most pieces of software abide by the general JFIF standard and can be read by various software. If you want your jpeg file to do the same, be prepared to write hundreds (to about a thousand) lines of code just for an encoder. You're better off borrowing an encoder that has already been published on the internet than writing your own. You can start by looking into libjpeg which is written in C and forms the basis of many other jpeg codecs, its C# implementation or even a Java个版本受到它的启发。
在一些伪代码中,encoding/decoding过程可以描述如下。
function saveToJpeg(pixels, fileout) {
// pixels is a 2D or 3D array containing your raw pixel values
// blocks is a list of 2D arrays of size 8x8 each, containing pixel values
blocks = splitBlocks(pixels);
// a list similar to blocks, but for the DCT coefficients
coeffs = dct(blocks);
saveCoefficients(coeffs, fileout);
}
function loadJpeg(filein) {
coeffs = readCoefficients(filein);
blocks = idct(coeffs);
pixels = combineBlocks(blocks);
return pixels;
}
对于隐写术,您可以按如下方式修改它。
function embedSecretToJpeg(pixels, secret, fileout) {
blocks = splitBlocks(pixels);
coeffs = dct(blocks);
modified_coeffs = embedSecret(coeffs, secret);
saveCoefficients(modified_coeffs, fileout);
}
function extractSecretFromJpeg(filein) {
coeffs = readCoefficients(filein);
secret = extractSecret(coeffs);
return secret;
}
如果您的封面图片已经是 jpeg 格式,则无需使用解码器将其加载为像素,然后将其传递给编码器以嵌入您的信息。您可以改为执行此操作。
function embedSecretToJpeg(pixels, secret, filein, fileout) {
coeffs = readCoefficients(filein);
modified_coeffs = embedSecret(coeffs, secret);
saveCoefficients(modified_coeffs, fileout);
}
就您的问题而言,encoder/decoder 应该解决 1、2、3 和 5,除非您自己编写一个。
问题1:一般来说,你想用必要的数量rows/columns填充图像,这样宽度和高度都可以被8整除。在内部,编码器将跟踪填充的 rows/columns,以便解码器在重建后丢弃它们。这些虚拟 rows/columns 的像素值的选择由您决定,但建议您不要使用常量值,因为它会导致 ringing artifacts,这与以下事实有关:方波是 sinc 函数。
问题 2:虽然您只会修改几个块,但编码过程需要您将它们全部转换,以便将它们存储到文件中。
问题 3:您必须量化浮点 DCT 系数,因为这是无损存储到文件中的系数。您可以在量化步骤后根据自己的喜好修改它们。
问题4:没有人阻止你修改任何系数,但你必须记住每个系数都会影响一个块中的所有64个像素。 DC 系数和 low frequency AC 会引入最大的失真,因此您可能希望远离它们。更具体地说,由于 DC 系数的存储方式,修改一个会将失真传播到所有后续块。
{kind=link}
由于大多数高频系数为0,因此可以使用RLE对其进行有效压缩。修改 0 系数可能会将其翻转为 1(如果您正在进行基本的 LSB 替换),这会破坏这种有效的压缩。
最后,一些算法将它们的秘密存储在任何非零系数中并会跳过任何 0。但是,如果您尝试修改 1,它可能会翻转为 0,并且在提取过程中您会盲目地跳过读取它。因此,此类算法不会接近任何值为 1 或 0 的系数。
问题 5:在解码时,您只需将系数乘以相应的量化值 table。例如,DC 系数为 309.443,量化后得到 round(309.443 / 16) = 19。舍入位是这里的有损部分,它不允许您重建 309.433。所以反过来就是 19 * 16 = 304.
DCT 在隐写术中的其他用途
频率变换,例如 DCT 和 DWT 可用于隐写术以在频域中嵌入秘密,但不一定将隐写图像存储为 jpeg。这个过程是pixels -> DCT -> coefficients -> modify coefficients -> IDCT -> pixels,也就是你发给接收端的。因此,格式的选择在这里很重要。如果您决定将像素保存为 jpeg,则 DCT 系数中的秘密