tensorflow BasicLSTMCell 中的 num_units 是什么?
What is num_units in tensorflow BasicLSTMCell?
在MNIST LSTM例子中,我不明白"hidden layer"是什么意思。它是随着时间的推移表示展开的 RNN 时形成的虚构层吗?
为什么大多数情况下 num_units = 128?
BasicLSTMCell的参数n_hidden是LSTM的隐藏单元数
如您所说,您真的应该阅读 Colah 的 blog post 以了解 LSTM,但这里需要注意一点。
如果您有一个形状为 [T, 10] 的输入 x,您将为 LSTM 提供从 t=0 到 t=T-1 的值序列,每个值的大小为 10.
在每个时间步,将输入乘以形状为 [10, n_hidden] 的矩阵,得到一个 n_hidden 向量。
你的 LSTM 在每个时间步得到 t:
- 前一个隐藏状态
h_{t-1},大小n_hidden(在t=0,前一个状态是[0., 0., ...])
- 输入,转换为大小
n_hidden
- 它将对这些输入求和并产生大小为
n_hidden 的下一个隐藏状态h_t
来自 Colah 的博客 post:
如果您只是想让代码正常工作,请继续使用 n_hidden = 128 就可以了。
隐藏单元的数量是神经网络学习能力的直接表示——它反映了学习参数的数量。值 128 可能是任意选择的或凭经验选择的。您可以通过实验更改该值并重新运行 程序以查看它如何影响训练准确性(您可以通过 很多 更少的隐藏单元获得超过 90% 的测试准确性) .使用更多的单位使其更有可能完美地记住完整的训练集(尽管这将花费更长的时间,并且您 运行 有过度拟合的风险)。
要理解的关键,在著名的 Colah's blog post (find "each line carries an entire vector"), is that X is an array of data (nowadays often called a tensor) 中有点微妙 -- 它并不意味着是 标量 值。例如,其中显示了 tanh 函数,这意味着该函数是 broadcast 跨整个数组(隐式 for 循环)- - 而不是简单地每个时间步执行一次。
因此,隐藏单元代表网络中的有形存储,这主要体现在权重数组的大小上。而且因为 LSTM 实际上确实有一点它自己的内部存储与学习的模型参数分开,它必须知道有多少个单元——最终需要与权重的大小一致。在最简单的情况下,RNN 没有内部存储——因此它甚至不需要提前知道它被应用到多少"hidden units"。
- 对类似问题的一个很好的回答 here。
- 您可以在 TensorFlow 中查看 the source for BasicLSTMCell 以了解其具体使用方式。
旁注:This notation 在统计和机器学习以及其他使用通用公式处理大批量数据的领域中非常常见(3D 图形是另一个例子)。对于希望看到他们的 for 循环明确写出的人来说,需要一点时间来适应。
我认为 "num_hidden" 这个词让 TF 用户感到困惑。实际上它与展开的LSTM单元无关,它只是张量的维度,它从时间步长输入张量转换并输入LSTM单元。
num_units can be interpreted as the analogy of hidden layer from the feed forward neural network. The number of nodes in hidden layer of a feed forward neural network is equivalent to num_units number of LSTM units in a LSTM cell at every time step of the network.
那里也有image!
LSTM 在随时间传播时保留两条信息:
一个hidden状态;这是 LSTM 使用其 (forget, input, and output) 门随时间累积的记忆,以及
前一个时间步输出。
Tensorflow 的 num_units 是 LSTM 隐藏状态的大小(如果不使用投影,这也是输出的大小)。
为了让名字num_units更直观,你可以把它看作是LSTM单元中隐藏单元的数量,或者单元中记忆单元的数量。
查看 this 真棒 post 更清楚
这个术语 num_units 或 num_hidden_units 有时在实现中使用变量名称 nhid 表示,意味着 LSTM 单元的输入是维数 nhid(或者对于批量实现,它将是形状为 batch_size x nhid 的矩阵)。因此,输出(来自 LSTM 单元格)也将具有相同的维度,因为 RNN/LSTM/GRU 单元格不会改变输入向量或矩阵的维度。
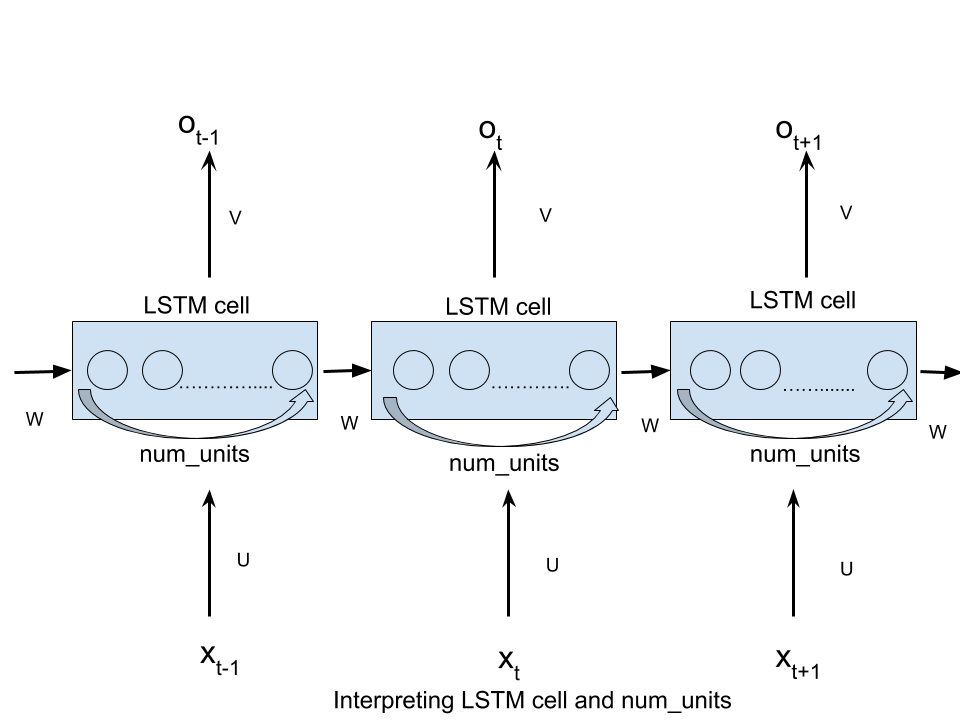
如前所述,该术语是从前馈神经网络 (FFN) 文献中借用的,在 RNN 的上下文中使用时引起了混淆。但是,想法是 即使是 RNN 也可以在每个时间步 被视为 作为 FFN。在这个视图中,隐藏层确实包含 num_hidden 个单元,如下图所示:
更具体地说,在下面的示例中,num_hidden_units 或 nhid 将是 3,因为 隐藏状态的大小 (中间层)是一个3D向量.
由于我在合并来自不同来源的信息时遇到了一些问题,所以我创建了下图,其中显示了博客 post (http://colah.github.io/posts/2015-08-Understanding-LSTMs/) and (https://jasdeep06.github.io/posts/Understanding-LSTM-in-Tensorflow-MNIST/) 的组合,我认为这些图形非常有用但在解释 number_units 时出现错误。
几个 LSTM 单元形成一个 LSTM 层。如下图所示。由于您主要处理的是非常广泛的数据,因此不可能将所有内容都合并到模型中。因此,数据被分成小块作为批次,一个接一个地处理,直到读入包含最后一部分的批次。在图的下半部分,您可以看到读取批次的输入(深灰色)一个接一个地从第1批到第batch_size批。上面的单元格 LSTM 单元格 1 到 LSTM 单元格 time_step 代表描述的 LSTM 模型单元格 (http://colah.github.io/posts/2015-08-Understanding-LSTMs/)。单元格的数量等于固定时间步长的数量。例如,如果您采用总共包含 150 个字符的文本序列,则可以将其分成 3 (batch_size),并且每批的序列长度为 50(time_step 的数量,因此LSTM 细胞)。如果您随后对每个字符进行一次性编码,则每个元素(输入的深灰色框)将表示一个向量,该向量具有词汇表的长度(特征数量)。这些向量将流入各个细胞中的神经元网络(细胞中的绿色元素),并将其维度更改为隐藏单元数量的长度(number_units) .因此输入具有维度(batch_size x time_step x 特征)。长时记忆(细胞状态)和短时记忆(隐藏状态)具有相同的维度(batch_size x number_units)。由细胞产生的浅灰色块具有不同的维度,因为神经网络(绿色元素)中的转换是在隐藏单元的帮助下发生的(batch_size x time_step x number_units)。输出可以从任何单元格返回,但大多数情况下只有最后一个块(黑色边框)的信息是相关的(不是所有问题),因为它包含以前时间步长的所有信息。
大多数 LSTM/RNN 图表只显示隐藏的单元格,但从不显示这些单元格的单位。因此,混乱。
每个隐藏层都有隐藏单元,与时间步数一样多。
此外,每个隐藏单元由多个隐藏单元组成,如下图所示。因此,RNN中一个隐藏层矩阵的维数为(时间步数,隐藏单元数)。
这张图片说明了隐藏单元的概念https://imgur.com/Fjx4Zuo。
我认为这是对您问题的正确回答。 LSTM 总是让人困惑。
您可以参考此博客了解更多详情Animated RNN, LSTM and GRU
根据@SangLe 的回答,我制作了一张图片(请参阅原始图片来源),显示教程中经典表示的单元格 (Source1: Colah's Blog) and an equivalent cell with 2 units (Source2: Raimi Karim 's post)。希望它能澄清 cells/units 和真正的网络架构之间的混淆。
在MNIST LSTM例子中,我不明白"hidden layer"是什么意思。它是随着时间的推移表示展开的 RNN 时形成的虚构层吗?
为什么大多数情况下 num_units = 128?
BasicLSTMCell的参数n_hidden是LSTM的隐藏单元数
如您所说,您真的应该阅读 Colah 的 blog post 以了解 LSTM,但这里需要注意一点。
如果您有一个形状为 [T, 10] 的输入 x,您将为 LSTM 提供从 t=0 到 t=T-1 的值序列,每个值的大小为 10.
在每个时间步,将输入乘以形状为 [10, n_hidden] 的矩阵,得到一个 n_hidden 向量。
你的 LSTM 在每个时间步得到 t:
- 前一个隐藏状态
h_{t-1},大小n_hidden(在t=0,前一个状态是[0., 0., ...]) - 输入,转换为大小
n_hidden - 它将对这些输入求和并产生大小为
n_hidden的下一个隐藏状态
h_t
来自 Colah 的博客 post:
如果您只是想让代码正常工作,请继续使用 n_hidden = 128 就可以了。
隐藏单元的数量是神经网络学习能力的直接表示——它反映了学习参数的数量。值 128 可能是任意选择的或凭经验选择的。您可以通过实验更改该值并重新运行 程序以查看它如何影响训练准确性(您可以通过 很多 更少的隐藏单元获得超过 90% 的测试准确性) .使用更多的单位使其更有可能完美地记住完整的训练集(尽管这将花费更长的时间,并且您 运行 有过度拟合的风险)。
要理解的关键,在著名的 Colah's blog post (find "each line carries an entire vector"), is that X is an array of data (nowadays often called a tensor) 中有点微妙 -- 它并不意味着是 标量 值。例如,其中显示了 tanh 函数,这意味着该函数是 broadcast 跨整个数组(隐式 for 循环)- - 而不是简单地每个时间步执行一次。
因此,隐藏单元代表网络中的有形存储,这主要体现在权重数组的大小上。而且因为 LSTM 实际上确实有一点它自己的内部存储与学习的模型参数分开,它必须知道有多少个单元——最终需要与权重的大小一致。在最简单的情况下,RNN 没有内部存储——因此它甚至不需要提前知道它被应用到多少"hidden units"。
- 对类似问题的一个很好的回答 here。
- 您可以在 TensorFlow 中查看 the source for BasicLSTMCell 以了解其具体使用方式。
旁注:This notation 在统计和机器学习以及其他使用通用公式处理大批量数据的领域中非常常见(3D 图形是另一个例子)。对于希望看到他们的 for 循环明确写出的人来说,需要一点时间来适应。
我认为 "num_hidden" 这个词让 TF 用户感到困惑。实际上它与展开的LSTM单元无关,它只是张量的维度,它从时间步长输入张量转换并输入LSTM单元。
num_unitscan be interpreted as the analogy of hidden layer from the feed forward neural network. The number of nodes in hidden layer of a feed forward neural network is equivalent to num_units number of LSTM units in a LSTM cell at every time step of the network.
那里也有image!
{kind=link}
LSTM 在随时间传播时保留两条信息:
一个hidden状态;这是 LSTM 使用其 (forget, input, and output) 门随时间累积的记忆,以及
前一个时间步输出。
Tensorflow 的 num_units 是 LSTM 隐藏状态的大小(如果不使用投影,这也是输出的大小)。
为了让名字num_units更直观,你可以把它看作是LSTM单元中隐藏单元的数量,或者单元中记忆单元的数量。
查看 this 真棒 post 更清楚
这个术语 num_units 或 num_hidden_units 有时在实现中使用变量名称 nhid 表示,意味着 LSTM 单元的输入是维数 nhid(或者对于批量实现,它将是形状为 batch_size x nhid 的矩阵)。因此,输出(来自 LSTM 单元格)也将具有相同的维度,因为 RNN/LSTM/GRU 单元格不会改变输入向量或矩阵的维度。
如前所述,该术语是从前馈神经网络 (FFN) 文献中借用的,在 RNN 的上下文中使用时引起了混淆。但是,想法是 即使是 RNN 也可以在每个时间步 被视为 作为 FFN。在这个视图中,隐藏层确实包含 num_hidden 个单元,如下图所示:
更具体地说,在下面的示例中,num_hidden_units 或 nhid 将是 3,因为 隐藏状态的大小 (中间层)是一个3D向量.
由于我在合并来自不同来源的信息时遇到了一些问题,所以我创建了下图,其中显示了博客 post (http://colah.github.io/posts/2015-08-Understanding-LSTMs/) and (https://jasdeep06.github.io/posts/Understanding-LSTM-in-Tensorflow-MNIST/) 的组合,我认为这些图形非常有用但在解释 number_units 时出现错误。
几个 LSTM 单元形成一个 LSTM 层。如下图所示。由于您主要处理的是非常广泛的数据,因此不可能将所有内容都合并到模型中。因此,数据被分成小块作为批次,一个接一个地处理,直到读入包含最后一部分的批次。在图的下半部分,您可以看到读取批次的输入(深灰色)一个接一个地从第1批到第batch_size批。上面的单元格 LSTM 单元格 1 到 LSTM 单元格 time_step 代表描述的 LSTM 模型单元格 (http://colah.github.io/posts/2015-08-Understanding-LSTMs/)。单元格的数量等于固定时间步长的数量。例如,如果您采用总共包含 150 个字符的文本序列,则可以将其分成 3 (batch_size),并且每批的序列长度为 50(time_step 的数量,因此LSTM 细胞)。如果您随后对每个字符进行一次性编码,则每个元素(输入的深灰色框)将表示一个向量,该向量具有词汇表的长度(特征数量)。这些向量将流入各个细胞中的神经元网络(细胞中的绿色元素),并将其维度更改为隐藏单元数量的长度(number_units) .因此输入具有维度(batch_size x time_step x 特征)。长时记忆(细胞状态)和短时记忆(隐藏状态)具有相同的维度(batch_size x number_units)。由细胞产生的浅灰色块具有不同的维度,因为神经网络(绿色元素)中的转换是在隐藏单元的帮助下发生的(batch_size x time_step x number_units)。输出可以从任何单元格返回,但大多数情况下只有最后一个块(黑色边框)的信息是相关的(不是所有问题),因为它包含以前时间步长的所有信息。
大多数 LSTM/RNN 图表只显示隐藏的单元格,但从不显示这些单元格的单位。因此,混乱。 每个隐藏层都有隐藏单元,与时间步数一样多。 此外,每个隐藏单元由多个隐藏单元组成,如下图所示。因此,RNN中一个隐藏层矩阵的维数为(时间步数,隐藏单元数)。
这张图片说明了隐藏单元的概念https://imgur.com/Fjx4Zuo。
我认为这是对您问题的正确回答。 LSTM 总是让人困惑。
您可以参考此博客了解更多详情Animated RNN, LSTM and GRU
根据@SangLe 的回答,我制作了一张图片(请参阅原始图片来源),显示教程中经典表示的单元格 (Source1: Colah's Blog) and an equivalent cell with 2 units (Source2: Raimi Karim 's post)。希望它能澄清 cells/units 和真正的网络架构之间的混淆。