正则表达式调试
RegEx debugging
我正在使用我有权访问的两个单独的调试工具在字符串 AAAC(来自 rexegg.com 的示例)上调试正则表达式 ^(A+)*B:
- regex101.com
- RegexBuddy v4
下面是结果(左侧为 regex101):
我的问题主要不是关于步骤的数量,这对我来说也很重要,而是如何进行回溯。为什么我们看到差异? (regex101 使用 PCRE 库,我将 RegexBuddy 库设置为相同)
全面的一步一步的解释真的对我有利。
我不会依赖步骤数或任何调试作为测试
要么回溯要么失败。
一般来说,远离简单的结构,例如 (A+)* 不仅
回溯内部 A+ 但也回溯外部 (..)*。
outter 的每一遍都会产生一个新的(新的)inner 系列回溯。
获得像RegexFormat
这样好的基准测试软件
并测试一系列的指数时间结果。
当内容增加相同时,线性结果就是你要找的
数量。
下面是 (A+)? 与 (A+)* 的示例。我们将目标设置为已知故障
并稳步增加长度以延长对该故障的处理。
如果您查看正则表达式 2 (A+)*,您会注意到
呈指数增长
三个目标增加。
最后,我们吹出目标,使引擎内部资源过载。
编辑:经过一些分析,我post对回溯步骤的一个微不足道的结论。
通过分析下面的基准时间,回溯似乎是一个 2^N 过程。
其中 N 是在失败时回溯的字符文字数。
考虑到 Revo 的简单情况,隔离回溯更容易一些。
因为看起来 %98 的总时间只涉及回溯。
鉴于该假设,可以从 2 个点获取时间结果,并生成一个方程。
我用的等式的形式是f(x) = a * r^x.
给定坐标(“A”的数量与所花费的时间),使用点
(7, 1.13) , (9, 4.43) 生成了这个 f(x) = 0.009475 * 1.9799 ^ x
这真的是 # sec's = 0.009475 * 1.9799 ^ # letters
我 运行 将下面基准中的所有字母“A”的数量放入此公式中。
#LTR's Bench Time
7 1.13
9 4.43
13 70.51
产生了准确的基准时间 (+/- .1%)。
然后我看到 1.9799 非常接近 2.0,所以我将 'a' 系数调低至 .009 并再次 运行,得到这个:
f(7 letters) = 2 ^ 7 * .009 = 1.152 sec’s
f(9 letters) = 2 ^ 9 * .009 = 4.608 sec’s
f(13 letters) = 2 ^ 13 * .009 = 73.728 sec’s
f(27 letters) = 2 ^ 27 * .009 = 1207959.552 sec’s = 335 hours
现在看来很清楚回溯步骤与
的数量相关
在 2 ^ N 关系中回溯的字母。
我也认为 一些 引擎可以完成这个简单的 2^N 数学
只有在像这样的简单场景中。这些似乎是
的时代
引擎立即返回并说 太复杂了!.
这里的 t运行slation 是正则表达式足够简单,引擎可以
检测它。其他时候,引擎永远不会回来,
它挂了,可能会在一两年(或十年……)后恢复。
因此结论不是引擎是否会回溯,而是如何
你的目标字符串会影响回溯吗?
所以,在写regex的时候要提高警惕,一定要提防
嵌套的开放式量词。
我想说最好的办法总是使用正则表达式非常困难让它失败。
我说的是可疑地方的过多重复文字。
结束编辑
目标:AAAAAAAC
基准
Regex1: ^(A+)?B
Options: < none >
Completed iterations: 50 / 50 ( x 1000 )
Matches found per iteration: 0
Elapsed Time: 0.07 s, 72.04 ms, 72040 µs
Regex2: ^(A+)*B
Options: < none >
Completed iterations: 50 / 50 ( x 1000 )
Matches found per iteration: 0
Elapsed Time: 1.13 s, 1126.44 ms, 1126444 µs
目标:AAAAAAAAAC
基准
Regex1: ^(A+)?B
Options: < none >
Completed iterations: 50 / 50 ( x 1000 )
Matches found per iteration: 0
Elapsed Time: 0.08 s, 82.43 ms, 82426 µs
Regex2: ^(A+)*B
Options: < none >
Completed iterations: 50 / 50 ( x 1000 )
Matches found per iteration: 0
Elapsed Time: 4.43 s, 4433.19 ms, 4433188 µs
目标:AAAAAAAAAAAAAC
基准
Regex1: ^(A+)?B
Options: < none >
Completed iterations: 50 / 50 ( x 1000 )
Matches found per iteration: 0
Elapsed Time: 0.10 s, 104.02 ms, 104023 µs
Regex2: ^(A+)*B
Options: < none >
Completed iterations: 50 / 50 ( x 1000 )
Matches found per iteration: 0
Elapsed Time: 70.51 s, 70509.32 ms, 70509321 µs
目标:AAAAAAAAAAAAAAAAAAAAAAAAAAAC
基准
Regex1: ^(A+)?B
Options: < none >
Completed iterations: 50 / 50 ( x 1000 )
Matches found per iteration: 0
Elapsed Time: 0.18 s, 184.05 ms, 184047 µs
Regex2: ^(A+)*B
Options: < none >
Error: Regex Runtime Error !!
Completed iterations: 0 / 50 ( x 1000 )
Matches found per iteration: -1
Elapsed Time: 0.01 s, 7.38 ms, 7384 µs
Error item 2 : Target Operation ..
The complexity of matching the regular expression exceeded predefined
bounds. Try refactoring the regular expression to make each choice made by
the state machine unambiguous. This exception is thrown to prevent
"eternal" matches that take an indefinite period time to locate.
TL;DR
简而言之,"backtracking" 是当正则表达式引擎 returns 与 "flexible" 匹配时,尝试不同的路径来获得成功的匹配。
交替回溯
例如,在下面的模式中输入:
foo(bar|baz)
foobaz
正则表达式引擎将匹配 "foo",然后尝试两个选项中的第一个,匹配 "b",然后匹配 "a",但在 "r" 处失败。但是,它不会让整个匹配失败,而是 "rewind the tape" 并从第二个选择开始,匹配 "b" 然后 "a" 然后 "z"... 成功!
用量词回溯
这也适用于量词。量词是鼓励引擎匹配重复模式的任何内容,包括 ?、*、+ 和 {n,m}(取决于引擎)。
贪心量词(默认)将匹配尽可能多的重复,然后再继续模式的其余部分。例如,给定以下模式和输入:
\w+bar
foobar
模式 \w+ 将从匹配整个字符串开始:"foobar"。但是,当它移动到 b 时,正则表达式引擎已到达输入的末尾并且匹配失败。引擎不会简单地放弃,而是会要求最后一个贪婪量词放弃其重复之一,现在匹配 "fooba"。匹配仍然失败,因此引擎要求 \w+ 放弃 "a"(失败),然后 "b"。放弃"b"后,引擎现在可以匹配bar,匹配成功。
树和回溯
另一种思考正则表达式的方式是 "tree",回溯是返回一个节点并尝试另一条路径。给定模式 foo(bar|baz) 和输入 "foobaz",引擎将尝试如下操作:
foo(bar|baz)
|\
| \
| : f (match)
| : o (match)
| : o (match)
| | (bar|baz)
| |\
| | \
| | : b (match)
| | : a (match)
| | : r (FAIL: go back up a level)
| | ^
| |\
| | \
| | : b (match)
| | : a (match)
| | : z (match)
| | /
| |/
| /
|/
SUCCESS
计数 "Backtracks"
至于为什么你看到回溯 "number" 的差异...这可能与内部优化和日志记录级别有很大关系。例如,RegexBuddy 似乎不会将匹配记录到 ^ 之前的空字符串,而 regex101 会。不过,最后,只要最终得到相同的结果,你回溯的确切顺序(你爬回树的顺序)并不重要。
邪恶的正则表达式
您已经知道这一点,但为了其他任何碰巧路过的人的利益,您的正则表达式是为了演示“catastrophic backtracking" (aka "evil regex"), where the number of backtrack attempts grows exponentially as the length of the input increases. These regexes can be exploited to perform DoS attacks, so you must use caution not to introduce these into your patterns (as I found out”而编写的。
我正在使用我有权访问的两个单独的调试工具在字符串 AAAC(来自 rexegg.com 的示例)上调试正则表达式 ^(A+)*B:
- regex101.com
- RegexBuddy v4
下面是结果(左侧为 regex101):
我的问题主要不是关于步骤的数量,这对我来说也很重要,而是如何进行回溯。为什么我们看到差异? (regex101 使用 PCRE 库,我将 RegexBuddy 库设置为相同)
全面的一步一步的解释真的对我有利。
我不会依赖步骤数或任何调试作为测试
要么回溯要么失败。
一般来说,远离简单的结构,例如 (A+)* 不仅
回溯内部 A+ 但也回溯外部 (..)*。
outter 的每一遍都会产生一个新的(新的)inner 系列回溯。
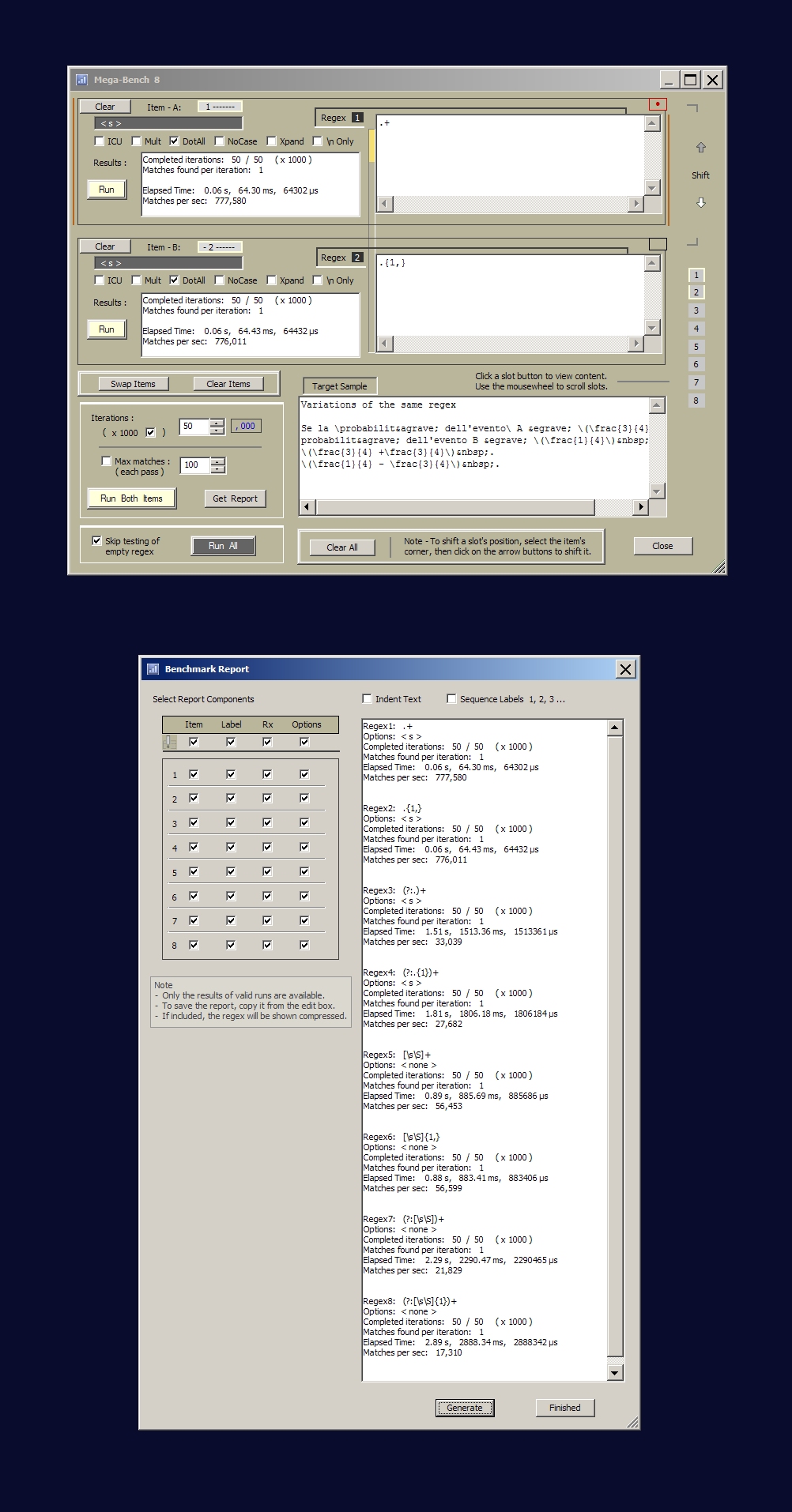
获得像RegexFormat
这样好的基准测试软件
并测试一系列的指数时间结果。
当内容增加相同时,线性结果就是你要找的
数量。
下面是 (A+)? 与 (A+)* 的示例。我们将目标设置为已知故障
并稳步增加长度以延长对该故障的处理。
如果您查看正则表达式 2 (A+)*,您会注意到
呈指数增长
三个目标增加。
最后,我们吹出目标,使引擎内部资源过载。
编辑:经过一些分析,我post对回溯步骤的一个微不足道的结论。
通过分析下面的基准时间,回溯似乎是一个 2^N 过程。
其中 N 是在失败时回溯的字符文字数。
考虑到 Revo 的简单情况,隔离回溯更容易一些。
因为看起来 %98 的总时间只涉及回溯。
鉴于该假设,可以从 2 个点获取时间结果,并生成一个方程。
我用的等式的形式是f(x) = a * r^x.
给定坐标(“A”的数量与所花费的时间),使用点
(7, 1.13) , (9, 4.43) 生成了这个 f(x) = 0.009475 * 1.9799 ^ x
这真的是 # sec's = 0.009475 * 1.9799 ^ # letters
我 运行 将下面基准中的所有字母“A”的数量放入此公式中。
#LTR's Bench Time
7 1.13
9 4.43
13 70.51
产生了准确的基准时间 (+/- .1%)。
然后我看到 1.9799 非常接近 2.0,所以我将 'a' 系数调低至 .009 并再次 运行,得到这个:
f(7 letters) = 2 ^ 7 * .009 = 1.152 sec’s
f(9 letters) = 2 ^ 9 * .009 = 4.608 sec’s
f(13 letters) = 2 ^ 13 * .009 = 73.728 sec’s
f(27 letters) = 2 ^ 27 * .009 = 1207959.552 sec’s = 335 hours
现在看来很清楚回溯步骤与
的数量相关
在 2 ^ N 关系中回溯的字母。
我也认为 一些 引擎可以完成这个简单的 2^N 数学
只有在像这样的简单场景中。这些似乎是
的时代
引擎立即返回并说 太复杂了!.
这里的 t运行slation 是正则表达式足够简单,引擎可以
检测它。其他时候,引擎永远不会回来,
它挂了,可能会在一两年(或十年……)后恢复。
因此结论不是引擎是否会回溯,而是如何
你的目标字符串会影响回溯吗?
所以,在写regex的时候要提高警惕,一定要提防
嵌套的开放式量词。
我想说最好的办法总是使用正则表达式非常困难让它失败。
我说的是可疑地方的过多重复文字。
结束编辑
{kind=link}
目标:AAAAAAAC
基准
Regex1: ^(A+)?B
Options: < none >
Completed iterations: 50 / 50 ( x 1000 )
Matches found per iteration: 0
Elapsed Time: 0.07 s, 72.04 ms, 72040 µs
Regex2: ^(A+)*B
Options: < none >
Completed iterations: 50 / 50 ( x 1000 )
Matches found per iteration: 0
Elapsed Time: 1.13 s, 1126.44 ms, 1126444 µs
目标:AAAAAAAAAC
基准
Regex1: ^(A+)?B
Options: < none >
Completed iterations: 50 / 50 ( x 1000 )
Matches found per iteration: 0
Elapsed Time: 0.08 s, 82.43 ms, 82426 µs
Regex2: ^(A+)*B
Options: < none >
Completed iterations: 50 / 50 ( x 1000 )
Matches found per iteration: 0
Elapsed Time: 4.43 s, 4433.19 ms, 4433188 µs
目标:AAAAAAAAAAAAAC
基准
Regex1: ^(A+)?B
Options: < none >
Completed iterations: 50 / 50 ( x 1000 )
Matches found per iteration: 0
Elapsed Time: 0.10 s, 104.02 ms, 104023 µs
Regex2: ^(A+)*B
Options: < none >
Completed iterations: 50 / 50 ( x 1000 )
Matches found per iteration: 0
Elapsed Time: 70.51 s, 70509.32 ms, 70509321 µs
目标:AAAAAAAAAAAAAAAAAAAAAAAAAAAC
基准
Regex1: ^(A+)?B
Options: < none >
Completed iterations: 50 / 50 ( x 1000 )
Matches found per iteration: 0
Elapsed Time: 0.18 s, 184.05 ms, 184047 µs
Regex2: ^(A+)*B
Options: < none >
Error: Regex Runtime Error !!
Completed iterations: 0 / 50 ( x 1000 )
Matches found per iteration: -1
Elapsed Time: 0.01 s, 7.38 ms, 7384 µs
Error item 2 : Target Operation ..
The complexity of matching the regular expression exceeded predefined
bounds. Try refactoring the regular expression to make each choice made by
the state machine unambiguous. This exception is thrown to prevent
"eternal" matches that take an indefinite period time to locate.
TL;DR
简而言之,"backtracking" 是当正则表达式引擎 returns 与 "flexible" 匹配时,尝试不同的路径来获得成功的匹配。
交替回溯
例如,在下面的模式中输入:
foo(bar|baz)
foobaz
正则表达式引擎将匹配 "foo",然后尝试两个选项中的第一个,匹配 "b",然后匹配 "a",但在 "r" 处失败。但是,它不会让整个匹配失败,而是 "rewind the tape" 并从第二个选择开始,匹配 "b" 然后 "a" 然后 "z"... 成功!
用量词回溯
这也适用于量词。量词是鼓励引擎匹配重复模式的任何内容,包括 ?、*、+ 和 {n,m}(取决于引擎)。
贪心量词(默认)将匹配尽可能多的重复,然后再继续模式的其余部分。例如,给定以下模式和输入:
\w+bar
foobar
模式 \w+ 将从匹配整个字符串开始:"foobar"。但是,当它移动到 b 时,正则表达式引擎已到达输入的末尾并且匹配失败。引擎不会简单地放弃,而是会要求最后一个贪婪量词放弃其重复之一,现在匹配 "fooba"。匹配仍然失败,因此引擎要求 \w+ 放弃 "a"(失败),然后 "b"。放弃"b"后,引擎现在可以匹配bar,匹配成功。
树和回溯
另一种思考正则表达式的方式是 "tree",回溯是返回一个节点并尝试另一条路径。给定模式 foo(bar|baz) 和输入 "foobaz",引擎将尝试如下操作:
foo(bar|baz)
|\
| \
| : f (match)
| : o (match)
| : o (match)
| | (bar|baz)
| |\
| | \
| | : b (match)
| | : a (match)
| | : r (FAIL: go back up a level)
| | ^
| |\
| | \
| | : b (match)
| | : a (match)
| | : z (match)
| | /
| |/
| /
|/
SUCCESS
计数 "Backtracks"
至于为什么你看到回溯 "number" 的差异...这可能与内部优化和日志记录级别有很大关系。例如,RegexBuddy 似乎不会将匹配记录到 ^ 之前的空字符串,而 regex101 会。不过,最后,只要最终得到相同的结果,你回溯的确切顺序(你爬回树的顺序)并不重要。
邪恶的正则表达式
您已经知道这一点,但为了其他任何碰巧路过的人的利益,您的正则表达式是为了演示“catastrophic backtracking" (aka "evil regex"), where the number of backtrack attempts grows exponentially as the length of the input increases. These regexes can be exploited to perform DoS attacks, so you must use caution not to introduce these into your patterns (as I found out”而编写的。