一维数组是否比本征动态向量快?
Are 1d arrays faster than Eigen dynamic vectors?
我正在使用大型矩阵(100x100 到 3000x3000)进行一些计算(大量求和和多达 120 次矩阵向量乘法),我正在使用 Eigen 库处理我的向量和矩阵。
我想知道如何加快我的程序。我应该继续使用 Eigen、使用一维数组、使用 std::vector 还是使用其他库?
假设您不想迁移到 GPU 并且想要信任 Eigen 的 benchkmark page, Eigen is pretty fast. You specifically mentioned matrix vector products for which in the range you specified, Eigen is on top. Make sure that OpenMP is enabled as Eigen will take advantage of multiple cores. Likewise with vectorization。
我做了一次比较,将 Eigen 与 ViennaCL 进行了比较(都在调试中):
Processing Unit | Mat Size | Exec time | Calc | Sparse %
CPU 10 0,000 dense_mat*mat
GPU 10 0,010 dense_mat*mat
CPU 100 0,103 dense_mat*mat
GPU 100 0,001 dense_mat*mat
CPU 1000 97,232 dense_mat*mat
GPU 1000 0,072 dense_mat*mat
CPU 10 0,000 sparse_mat*mat 0,25
GPU 10 0,007 sparse_mat*mat 0,25
CPU 10 0,000 sparse_mat*mat 0,5
GPU 10 0,000 sparse_mat*mat 0,5
CPU 10 0,000 sparse_mat*mat 1
GPU 10 0,000 sparse_mat*mat 1
CPU 100 0,010 sparse_mat*mat 0,25
GPU 100 0,001 sparse_mat*mat 0,25
CPU 100 0,030 sparse_mat*mat 0,5
GPU 100 0,001 sparse_mat*mat 0,5
CPU 100 0,106 sparse_mat*mat 1
GPU 100 0,001 sparse_mat*mat 1
CPU 1000 7,131 sparse_mat*mat 0,25
GPU 1000 0,073 sparse_mat*mat 0,25
CPU 1000 26,628 sparse_mat*mat 0,5
GPU 1000 0,072 sparse_mat*mat 0,5
CPU 1000 101,389 sparse_mat*mat 1
GPU 1000 0,072 sparse_mat*mat 1
使用的代码是:
//disable debug mechanisms to have a fair comparison with ublas:
#ifndef NDEBUG
#define NDEBUG
#endif
//
// include necessary system headers
//
#include <iostream>
#include <fstream>
//
// ublas includes
//
#include <boost/numeric/ublas/io.hpp>
#include <boost/numeric/ublas/triangular.hpp>
#include <boost/numeric/ublas/matrix_sparse.hpp>
#include <boost/numeric/ublas/matrix.hpp>
#include <boost/numeric/ublas/matrix_proxy.hpp>
#include <boost/numeric/ublas/lu.hpp>
#include <boost/numeric/ublas/io.hpp>
#define EIGEN_YES_I_KNOW_SPARSE_MODULE_IS_NOT_STABLE_YET
//
// Eigen includes
//
#include <Eigen/Core>
#include <Eigen/Dense>
// Must be set if you want to use ViennaCL algorithms on ublas objects
#define VIENNACL_WITH_UBLAS 1
//
// IMPORTANT: Must be set prior to any ViennaCL includes if you want to use ViennaCL algorithms on Eigen objects
//
#define VIENNACL_WITH_EIGEN 1
//
// IMPORTANT: Must be set prior to any ViennaCL includes if you want to use ViennaCL algorithms using OPENCL
//
#ifndef VIENNACL_WITH_OPENCL
#define VIENNACL_WITH_OPENCL
#endif
//
// ViennaCL includes
//
#include "viennacl/scalar.hpp"
#include "viennacl/vector.hpp"
#include "viennacl/matrix.hpp"
#include "viennacl/linalg/prod.hpp"
#include "viennacl/compressed_matrix.hpp"
#include "viennacl/linalg/sparse_matrix_operations.hpp"
#include "viennacl/linalg/ilu.hpp"
#include "viennacl/linalg/detail/ilu/block_ilu.hpp"
#include "viennacl/linalg/direct_solve.hpp"
#include "viennacl/linalg/bicgstab.hpp"
// Some helper functions for this tutorial:
#include "examples/tutorial/Random.hpp"
#include "examples/tutorial/vector-io.hpp"
#include "examples/benchmarks/benchmark-utils.hpp"
#define BLAS3_MATRIX_SIZE 700
using namespace boost::numeric;
#ifndef VIENNACL_WITH_OPENCL
struct dummy
{
std::size_t size() const { return 1; }
};
#endif
int main()
{
typedef float ScalarType;
Timer timer;
double exec_time;
//
// Initialize OpenCL device in the context
//
std::cout << std::endl << "--- initialized OpenGL device using ViennaCL ---" << std::endl;
#ifdef VIENNACL_WITH_OPENCL
std::vector<viennacl::ocl::device> devices = viennacl::ocl::current_context().devices();
#else
dummy devices;
#endif
#ifdef VIENNACL_WITH_OPENCL
viennacl::ocl::current_context().switch_device(devices[0]);
std::cout << " - Device Name: " << viennacl::ocl::current_device().name() << std::endl;
#endif
//// Output results file
std::ofstream resultsFile;
resultsFile.open("resultsFile.txt");
resultsFile << "Processing Unit,Mat Size,Exec time" << std::endl;
std::cout << "Processing Unit,Mat Size,Exec time" << std::endl;
// Start defining the dense matrices
size_t points = 230000;
size_t transRows=4;
size_t transCols=3;
// Other alternative: Use Eigen
Eigen::MatrixXf eigen_A(points, transRows);
Eigen::MatrixXf eigen_B(transRows, transCols);
// One alternative: Put the matrices into a contiguous block of memory (allows to use viennacl::fast_copy(), avoiding temporary memory)
std::vector<ScalarType> stl_A(points * transRows);
std::vector<ScalarType> stl_B(transRows * transCols);
// Set up the ViennaCL object
viennacl::matrix<ScalarType> vcl_A(points, transRows);
viennacl::matrix<ScalarType> vcl_B(transRows, transCols);
// Fill dense matrix in normal memory
for (unsigned int i = 0; i < points; ++i)
{
for (unsigned int j = 0; j < transRows; ++j)
{
stl_A[i*transRows + j] = random<ScalarType>();
eigen_A(i,j) = stl_A[i*transRows + j];
}
}
for (unsigned int i = 0; i < transRows; ++i)
{
for (unsigned int j = 0; j < transCols; ++j)
{
stl_B[i*transCols + j] = random<ScalarType>();
eigen_B(i,j) = stl_A[i*transCols + j];
}
}
// Perform the matrix*matrix product
// On CPU
Eigen::MatrixXf eigen_C(points, transCols);
timer.start();
eigen_C = eigen_A * eigen_B;
exec_time = timer.get();
resultsFile << "CPU," << points << "," << exec_time << std::endl;
std::cout << "CPU," << points << "," << exec_time << std::endl;
// on GPU
timer.start();
// Copy to gpu memory
// Using fastcopy I can get ~500x speed improvement
viennacl::fast_copy(&(stl_A[0]),&(stl_A[0]) + stl_A.size(),vcl_A);
viennacl::fast_copy(&(stl_B[0]),&(stl_B[0]) + stl_B.size(),vcl_B);
viennacl::matrix<ScalarType> vcl_C(points, transCols);
vcl_C = viennacl::linalg::prod(vcl_A, vcl_B);
viennacl::backend::finish();
exec_time = timer.get();
resultsFile << "GPU," << points << "," << exec_time << std::endl;
std::cout << "GPU," << points << "," << exec_time << std::endl;
//// Start defining the dense matrices
//for(size_t denseSize=10; denseSize<=1000; denseSize=denseSize*10)
//{
// // Other alternative: Use Eigen
// Eigen::MatrixXf eigen_A(denseSize, denseSize);
// // One alternative: Put the matrices into a contiguous block of memory (allows to use viennacl::fast_copy(), avoiding temporary memory)
// std::vector<ScalarType> stl_A(denseSize * denseSize);
// // Set up the ViennaCL object
// viennacl::matrix<ScalarType> vcl_A(denseSize, denseSize);
// // Fill dense matrix in normal memory
// for (unsigned int i = 0; i < denseSize; ++i)
// {
// for (unsigned int j = 0; j < denseSize; ++j)
// {
// stl_A[i*denseSize + j] = random<ScalarType>();
// eigen_A(i,j) = stl_A[i*denseSize + j];
// }
// }
// // Perform the matrix*matrix product
// // On CPU
// Eigen::MatrixXf eigen_C(denseSize, denseSize);
// timer.start();
// eigen_C = eigen_A * eigen_A;
// exec_time = timer.get();
// resultsFile << "CPU," << denseSize << "," << exec_time << std::endl;
// std::cout << "CPU," << denseSize << "," << exec_time << std::endl;
// // on GPU
// timer.start();
// // Copy to gpu memory
// // Using fastcopy I can get ~500x speed improvement
// viennacl::fast_copy(&(stl_A[0]),&(stl_A[0]) + stl_A.size(),vcl_A);
// viennacl::matrix<ScalarType> vcl_C(denseSize, denseSize);
// vcl_C = viennacl::linalg::prod(vcl_A, vcl_A);
// viennacl::backend::finish();
// exec_time = timer.get();
// resultsFile << "GPU," << denseSize << "," << exec_time << std::endl;
// std::cout << "GPU," << denseSize << "," << exec_time << std::endl;
//}
//// Start defining the sparse matrices
//for(size_t sparseSize=10; sparseSize<=1000; sparseSize=sparseSize*10)
//{
// for(float sparsePerc=0.25; sparsePerc<=1.0; sparsePerc=2*sparsePerc)
// {
// // Other alternative: Use Eigen
// Eigen::SparseMatrix<float> eigen_A(sparseSize, sparseSize);
// // One alternative: Put the matrices into a contiguous block of memory (allows to use viennacl::fast_copy(), avoiding temporary memory)
// std::vector<ScalarType> stl_A(sparseSize * sparseSize);
// // Set up the ViennaCL sparse matrix
// viennacl::matrix<ScalarType> vcl_A(sparseSize, sparseSize);
// // Fill dense matrix in normal memory
// for (size_t i=0; i<sparseSize; ++i)
// {
// for (size_t j=0; j<sparseSize; ++j)
// {
// if (((rand()%100)/100.0) <= sparsePerc)
// {
// stl_A[i*sparseSize + j] = float(rand());
// eigen_A.insert(i,j) = stl_A[i*sparseSize + j];
// }
// }
// }
// // Perform the matrix*matrix product
// // On CPU
// Eigen::SparseMatrix<float> eigen_C(sparseSize, sparseSize);
// timer.start();
// eigen_C = (eigen_A * eigen_A).pruned();
// exec_time = timer.get();
// resultsFile << "CPU," << sparseSize << "," << sparsePerc << "," << exec_time << std::endl;
// std::cout << "CPU," << sparseSize << "," << sparsePerc << "," << exec_time << std::endl;
// // on GPU
// timer.start();
// // Copy to gpu memory
// // Using fastcopy I can get ~500x speed improvement
// viennacl::fast_copy(&(stl_A[0]),&(stl_A[0]) + stl_A.size(),vcl_A);
// viennacl::matrix<ScalarType> vcl_C(sparseSize, sparseSize);
// vcl_C = viennacl::linalg::prod(vcl_A, vcl_A);
// viennacl::backend::finish();
// exec_time = timer.get();
// resultsFile << "GPU," << sparseSize << "," << sparsePerc << "," << exec_time << std::endl;
// std::cout << "GPU," << sparseSize << "," << sparsePerc << "," << exec_time << std::endl;
// }
//}
resultsFile.close();
//
// That's it.
//
std::cout << "Press [ENTER] to exit " << std::endl;
std::cin.get();
return EXIT_SUCCESS;
}
我正在使用大型矩阵(100x100 到 3000x3000)进行一些计算(大量求和和多达 120 次矩阵向量乘法),我正在使用 Eigen 库处理我的向量和矩阵。
我想知道如何加快我的程序。我应该继续使用 Eigen、使用一维数组、使用 std::vector 还是使用其他库?
假设您不想迁移到 GPU 并且想要信任 Eigen 的 benchkmark page, Eigen is pretty fast. You specifically mentioned matrix vector products for which in the range you specified, Eigen is on top. Make sure that OpenMP is enabled as Eigen will take advantage of multiple cores. Likewise with vectorization。
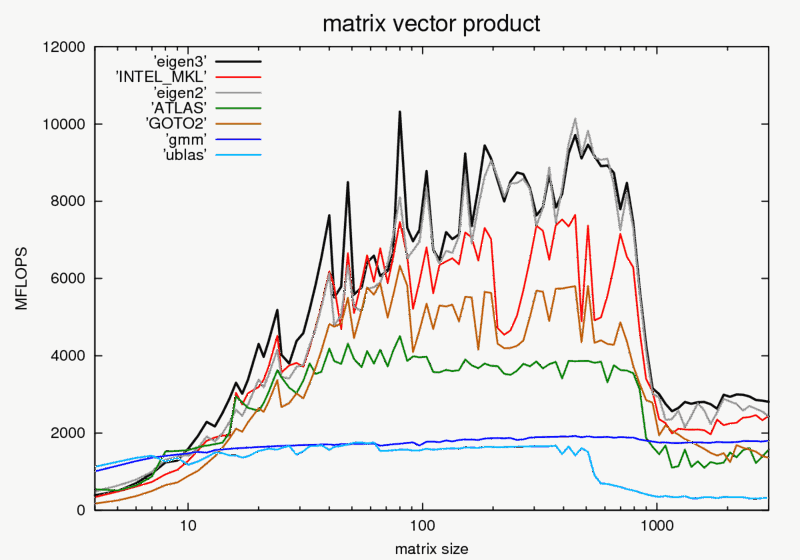{kind=link}
我做了一次比较,将 Eigen 与 ViennaCL 进行了比较(都在调试中):
Processing Unit | Mat Size | Exec time | Calc | Sparse %
CPU 10 0,000 dense_mat*mat
GPU 10 0,010 dense_mat*mat
CPU 100 0,103 dense_mat*mat
GPU 100 0,001 dense_mat*mat
CPU 1000 97,232 dense_mat*mat
GPU 1000 0,072 dense_mat*mat
CPU 10 0,000 sparse_mat*mat 0,25
GPU 10 0,007 sparse_mat*mat 0,25
CPU 10 0,000 sparse_mat*mat 0,5
GPU 10 0,000 sparse_mat*mat 0,5
CPU 10 0,000 sparse_mat*mat 1
GPU 10 0,000 sparse_mat*mat 1
CPU 100 0,010 sparse_mat*mat 0,25
GPU 100 0,001 sparse_mat*mat 0,25
CPU 100 0,030 sparse_mat*mat 0,5
GPU 100 0,001 sparse_mat*mat 0,5
CPU 100 0,106 sparse_mat*mat 1
GPU 100 0,001 sparse_mat*mat 1
CPU 1000 7,131 sparse_mat*mat 0,25
GPU 1000 0,073 sparse_mat*mat 0,25
CPU 1000 26,628 sparse_mat*mat 0,5
GPU 1000 0,072 sparse_mat*mat 0,5
CPU 1000 101,389 sparse_mat*mat 1
GPU 1000 0,072 sparse_mat*mat 1
使用的代码是:
//disable debug mechanisms to have a fair comparison with ublas:
#ifndef NDEBUG
#define NDEBUG
#endif
//
// include necessary system headers
//
#include <iostream>
#include <fstream>
//
// ublas includes
//
#include <boost/numeric/ublas/io.hpp>
#include <boost/numeric/ublas/triangular.hpp>
#include <boost/numeric/ublas/matrix_sparse.hpp>
#include <boost/numeric/ublas/matrix.hpp>
#include <boost/numeric/ublas/matrix_proxy.hpp>
#include <boost/numeric/ublas/lu.hpp>
#include <boost/numeric/ublas/io.hpp>
#define EIGEN_YES_I_KNOW_SPARSE_MODULE_IS_NOT_STABLE_YET
//
// Eigen includes
//
#include <Eigen/Core>
#include <Eigen/Dense>
// Must be set if you want to use ViennaCL algorithms on ublas objects
#define VIENNACL_WITH_UBLAS 1
//
// IMPORTANT: Must be set prior to any ViennaCL includes if you want to use ViennaCL algorithms on Eigen objects
//
#define VIENNACL_WITH_EIGEN 1
//
// IMPORTANT: Must be set prior to any ViennaCL includes if you want to use ViennaCL algorithms using OPENCL
//
#ifndef VIENNACL_WITH_OPENCL
#define VIENNACL_WITH_OPENCL
#endif
//
// ViennaCL includes
//
#include "viennacl/scalar.hpp"
#include "viennacl/vector.hpp"
#include "viennacl/matrix.hpp"
#include "viennacl/linalg/prod.hpp"
#include "viennacl/compressed_matrix.hpp"
#include "viennacl/linalg/sparse_matrix_operations.hpp"
#include "viennacl/linalg/ilu.hpp"
#include "viennacl/linalg/detail/ilu/block_ilu.hpp"
#include "viennacl/linalg/direct_solve.hpp"
#include "viennacl/linalg/bicgstab.hpp"
// Some helper functions for this tutorial:
#include "examples/tutorial/Random.hpp"
#include "examples/tutorial/vector-io.hpp"
#include "examples/benchmarks/benchmark-utils.hpp"
#define BLAS3_MATRIX_SIZE 700
using namespace boost::numeric;
#ifndef VIENNACL_WITH_OPENCL
struct dummy
{
std::size_t size() const { return 1; }
};
#endif
int main()
{
typedef float ScalarType;
Timer timer;
double exec_time;
//
// Initialize OpenCL device in the context
//
std::cout << std::endl << "--- initialized OpenGL device using ViennaCL ---" << std::endl;
#ifdef VIENNACL_WITH_OPENCL
std::vector<viennacl::ocl::device> devices = viennacl::ocl::current_context().devices();
#else
dummy devices;
#endif
#ifdef VIENNACL_WITH_OPENCL
viennacl::ocl::current_context().switch_device(devices[0]);
std::cout << " - Device Name: " << viennacl::ocl::current_device().name() << std::endl;
#endif
//// Output results file
std::ofstream resultsFile;
resultsFile.open("resultsFile.txt");
resultsFile << "Processing Unit,Mat Size,Exec time" << std::endl;
std::cout << "Processing Unit,Mat Size,Exec time" << std::endl;
// Start defining the dense matrices
size_t points = 230000;
size_t transRows=4;
size_t transCols=3;
// Other alternative: Use Eigen
Eigen::MatrixXf eigen_A(points, transRows);
Eigen::MatrixXf eigen_B(transRows, transCols);
// One alternative: Put the matrices into a contiguous block of memory (allows to use viennacl::fast_copy(), avoiding temporary memory)
std::vector<ScalarType> stl_A(points * transRows);
std::vector<ScalarType> stl_B(transRows * transCols);
// Set up the ViennaCL object
viennacl::matrix<ScalarType> vcl_A(points, transRows);
viennacl::matrix<ScalarType> vcl_B(transRows, transCols);
// Fill dense matrix in normal memory
for (unsigned int i = 0; i < points; ++i)
{
for (unsigned int j = 0; j < transRows; ++j)
{
stl_A[i*transRows + j] = random<ScalarType>();
eigen_A(i,j) = stl_A[i*transRows + j];
}
}
for (unsigned int i = 0; i < transRows; ++i)
{
for (unsigned int j = 0; j < transCols; ++j)
{
stl_B[i*transCols + j] = random<ScalarType>();
eigen_B(i,j) = stl_A[i*transCols + j];
}
}
// Perform the matrix*matrix product
// On CPU
Eigen::MatrixXf eigen_C(points, transCols);
timer.start();
eigen_C = eigen_A * eigen_B;
exec_time = timer.get();
resultsFile << "CPU," << points << "," << exec_time << std::endl;
std::cout << "CPU," << points << "," << exec_time << std::endl;
// on GPU
timer.start();
// Copy to gpu memory
// Using fastcopy I can get ~500x speed improvement
viennacl::fast_copy(&(stl_A[0]),&(stl_A[0]) + stl_A.size(),vcl_A);
viennacl::fast_copy(&(stl_B[0]),&(stl_B[0]) + stl_B.size(),vcl_B);
viennacl::matrix<ScalarType> vcl_C(points, transCols);
vcl_C = viennacl::linalg::prod(vcl_A, vcl_B);
viennacl::backend::finish();
exec_time = timer.get();
resultsFile << "GPU," << points << "," << exec_time << std::endl;
std::cout << "GPU," << points << "," << exec_time << std::endl;
//// Start defining the dense matrices
//for(size_t denseSize=10; denseSize<=1000; denseSize=denseSize*10)
//{
// // Other alternative: Use Eigen
// Eigen::MatrixXf eigen_A(denseSize, denseSize);
// // One alternative: Put the matrices into a contiguous block of memory (allows to use viennacl::fast_copy(), avoiding temporary memory)
// std::vector<ScalarType> stl_A(denseSize * denseSize);
// // Set up the ViennaCL object
// viennacl::matrix<ScalarType> vcl_A(denseSize, denseSize);
// // Fill dense matrix in normal memory
// for (unsigned int i = 0; i < denseSize; ++i)
// {
// for (unsigned int j = 0; j < denseSize; ++j)
// {
// stl_A[i*denseSize + j] = random<ScalarType>();
// eigen_A(i,j) = stl_A[i*denseSize + j];
// }
// }
// // Perform the matrix*matrix product
// // On CPU
// Eigen::MatrixXf eigen_C(denseSize, denseSize);
// timer.start();
// eigen_C = eigen_A * eigen_A;
// exec_time = timer.get();
// resultsFile << "CPU," << denseSize << "," << exec_time << std::endl;
// std::cout << "CPU," << denseSize << "," << exec_time << std::endl;
// // on GPU
// timer.start();
// // Copy to gpu memory
// // Using fastcopy I can get ~500x speed improvement
// viennacl::fast_copy(&(stl_A[0]),&(stl_A[0]) + stl_A.size(),vcl_A);
// viennacl::matrix<ScalarType> vcl_C(denseSize, denseSize);
// vcl_C = viennacl::linalg::prod(vcl_A, vcl_A);
// viennacl::backend::finish();
// exec_time = timer.get();
// resultsFile << "GPU," << denseSize << "," << exec_time << std::endl;
// std::cout << "GPU," << denseSize << "," << exec_time << std::endl;
//}
//// Start defining the sparse matrices
//for(size_t sparseSize=10; sparseSize<=1000; sparseSize=sparseSize*10)
//{
// for(float sparsePerc=0.25; sparsePerc<=1.0; sparsePerc=2*sparsePerc)
// {
// // Other alternative: Use Eigen
// Eigen::SparseMatrix<float> eigen_A(sparseSize, sparseSize);
// // One alternative: Put the matrices into a contiguous block of memory (allows to use viennacl::fast_copy(), avoiding temporary memory)
// std::vector<ScalarType> stl_A(sparseSize * sparseSize);
// // Set up the ViennaCL sparse matrix
// viennacl::matrix<ScalarType> vcl_A(sparseSize, sparseSize);
// // Fill dense matrix in normal memory
// for (size_t i=0; i<sparseSize; ++i)
// {
// for (size_t j=0; j<sparseSize; ++j)
// {
// if (((rand()%100)/100.0) <= sparsePerc)
// {
// stl_A[i*sparseSize + j] = float(rand());
// eigen_A.insert(i,j) = stl_A[i*sparseSize + j];
// }
// }
// }
// // Perform the matrix*matrix product
// // On CPU
// Eigen::SparseMatrix<float> eigen_C(sparseSize, sparseSize);
// timer.start();
// eigen_C = (eigen_A * eigen_A).pruned();
// exec_time = timer.get();
// resultsFile << "CPU," << sparseSize << "," << sparsePerc << "," << exec_time << std::endl;
// std::cout << "CPU," << sparseSize << "," << sparsePerc << "," << exec_time << std::endl;
// // on GPU
// timer.start();
// // Copy to gpu memory
// // Using fastcopy I can get ~500x speed improvement
// viennacl::fast_copy(&(stl_A[0]),&(stl_A[0]) + stl_A.size(),vcl_A);
// viennacl::matrix<ScalarType> vcl_C(sparseSize, sparseSize);
// vcl_C = viennacl::linalg::prod(vcl_A, vcl_A);
// viennacl::backend::finish();
// exec_time = timer.get();
// resultsFile << "GPU," << sparseSize << "," << sparsePerc << "," << exec_time << std::endl;
// std::cout << "GPU," << sparseSize << "," << sparsePerc << "," << exec_time << std::endl;
// }
//}
resultsFile.close();
//
// That's it.
//
std::cout << "Press [ENTER] to exit " << std::endl;
std::cin.get();
return EXIT_SUCCESS;
}