MPI处理器数量产生错误,如何实现广播?
MPI processor quantity creates error, how to implement broadcast?
我创建了一个 python 程序来计算圆周率。然后我决定用 mpi4py 将它写到 运行 几个进程。该程序可以运行,但它 returns 的 pi 值与原始 python 版本不同。当我进一步研究这个问题时,我发现当我 运行 使用更多处理器时,它 returns 的值不太准确。为什么 MPI 版本会改变更多处理器的结果?使用广播而不是发送大量单独的消息是否更有意义?如果更有效,我将如何实施广播?
MPI 版本:
#!/apps/moose/miniconda/bin/python
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
name = MPI.Get_processor_name()
def f(x):
return (1-(float(x)**2))**float(0.5)
n = 1000000
nm = dict()
pi = dict()
for i in range(1,size+1):
if i == size:
nm[i] = (i*n/size)+1
else:
nm[i] = i*n/size
if rank == 0:
val = 0
for i in range(0,nm[1]):
val = val+f(float(i)/float(n))
val = val*2
pi[0] = (float(2)/n)*(float(1)+val)
print name, "rank", rank, "calculated", pi[0]
for i in range(1, size):
pi[i] = comm.recv(source=i, tag=i)
number = sum(pi.itervalues())
number = "%.20f" %(number)
import time
time.sleep(0.3)
print "Pi is approximately", number
for proc in range(1, size):
if proc == rank:
val = 0
for i in range(nm[proc]+1,nm[proc+1]):
val = val+f(float(i)/float(n))
val = val*2
pi[proc] = (float(2)/n)*(float(1)+val)
comm.send(pi[proc], dest=0, tag = proc)
print name, "rank", rank, "calculated", pi[proc]
原始Python版本:
#!/usr/bin/python
n = 1000000
def f(x):
return (1-(float(x)**2))**float(0.5)
val = 0
for i in range(n):
i = i+1
val = val+f(float(i)/float(n))
val = val*2
pi = (float(2)/n)*(float(1)+val)
print pi
您的代码通过计算四分之一圆盘的面积来估算 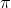 ,即使用梯形法则
,即使用梯形法则  的积分。
的积分。
你的代码的问题是每个进程的i值范围不完整。实际上,使用一个小 n 并打印 i 来查看发生了什么。例如,for i in range(nm[proc]+1,nm[proc+1]): 必须更改为 for i in range(nm[proc],nm[proc+1]):。否则,永远不会处理 i=nm[proc]。
另外,在pi[0] = (float(2)/n)*(float(1)+val)和pi[proc] = (float(2)/n)*(float(1)+val)中,float(1)项来自积分中的x=0。但是被统计了很多次,每个进程一次!由于错误数直接随进程数变化,增加进程数会降低准确性,这就是您报告的症状。
广播对应于一个通信器的所有进程都必须从给定进程获取相同的数据的情况。相反,这里要求来自所有处理器的数据必须使用总和来组合以产生可供单个进程使用的结果(称为"root")。后一个操作称为 reduction,由 comm.Reduce().
执行
这是一段基于您使用 comm.Reduce() 而不是 send() 和 recv() 的代码。
from mpi4py import MPI
import numpy as np
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
name = MPI.Get_processor_name()
def f(x):
return (1-(float(x)**2))**float(0.5)
n = 10000000
nm =np.zeros(size+1,'i')
nm[0]=1
for i in range(1,size+1):
if i == size:
nm[i]=n
else:
nm[i] = (i*n)/size
val=0
for i in range(nm[rank],nm[rank+1]):
val = val+f((float(i))/float(n))
out=np.array(0.0, 'd')
vala=np.array(val, 'd')
comm.Reduce([vala,MPI.DOUBLE],[out,MPI.DOUBLE],op=MPI.SUM,root=0)
if rank == 0:
number =(float(4)/n)*(out)+float(2)/n
number = "%.20f" %(number)
import time
time.sleep(0.3)
print "Pi is approximately", number
我创建了一个 python 程序来计算圆周率。然后我决定用 mpi4py 将它写到 运行 几个进程。该程序可以运行,但它 returns 的 pi 值与原始 python 版本不同。当我进一步研究这个问题时,我发现当我 运行 使用更多处理器时,它 returns 的值不太准确。为什么 MPI 版本会改变更多处理器的结果?使用广播而不是发送大量单独的消息是否更有意义?如果更有效,我将如何实施广播?
MPI 版本:
#!/apps/moose/miniconda/bin/python
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
name = MPI.Get_processor_name()
def f(x):
return (1-(float(x)**2))**float(0.5)
n = 1000000
nm = dict()
pi = dict()
for i in range(1,size+1):
if i == size:
nm[i] = (i*n/size)+1
else:
nm[i] = i*n/size
if rank == 0:
val = 0
for i in range(0,nm[1]):
val = val+f(float(i)/float(n))
val = val*2
pi[0] = (float(2)/n)*(float(1)+val)
print name, "rank", rank, "calculated", pi[0]
for i in range(1, size):
pi[i] = comm.recv(source=i, tag=i)
number = sum(pi.itervalues())
number = "%.20f" %(number)
import time
time.sleep(0.3)
print "Pi is approximately", number
for proc in range(1, size):
if proc == rank:
val = 0
for i in range(nm[proc]+1,nm[proc+1]):
val = val+f(float(i)/float(n))
val = val*2
pi[proc] = (float(2)/n)*(float(1)+val)
comm.send(pi[proc], dest=0, tag = proc)
print name, "rank", rank, "calculated", pi[proc]
原始Python版本:
#!/usr/bin/python
n = 1000000
def f(x):
return (1-(float(x)**2))**float(0.5)
val = 0
for i in range(n):
i = i+1
val = val+f(float(i)/float(n))
val = val*2
pi = (float(2)/n)*(float(1)+val)
print pi
您的代码通过计算四分之一圆盘的面积来估算 ,即使用梯形法则
的积分。
你的代码的问题是每个进程的i值范围不完整。实际上,使用一个小 n 并打印 i 来查看发生了什么。例如,for i in range(nm[proc]+1,nm[proc+1]): 必须更改为 for i in range(nm[proc],nm[proc+1]):。否则,永远不会处理 i=nm[proc]。
另外,在pi[0] = (float(2)/n)*(float(1)+val)和pi[proc] = (float(2)/n)*(float(1)+val)中,float(1)项来自积分中的x=0。但是被统计了很多次,每个进程一次!由于错误数直接随进程数变化,增加进程数会降低准确性,这就是您报告的症状。
广播对应于一个通信器的所有进程都必须从给定进程获取相同的数据的情况。相反,这里要求来自所有处理器的数据必须使用总和来组合以产生可供单个进程使用的结果(称为"root")。后一个操作称为 reduction,由 comm.Reduce().
这是一段基于您使用 comm.Reduce() 而不是 send() 和 recv() 的代码。
from mpi4py import MPI
import numpy as np
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
name = MPI.Get_processor_name()
def f(x):
return (1-(float(x)**2))**float(0.5)
n = 10000000
nm =np.zeros(size+1,'i')
nm[0]=1
for i in range(1,size+1):
if i == size:
nm[i]=n
else:
nm[i] = (i*n)/size
val=0
for i in range(nm[rank],nm[rank+1]):
val = val+f((float(i))/float(n))
out=np.array(0.0, 'd')
vala=np.array(val, 'd')
comm.Reduce([vala,MPI.DOUBLE],[out,MPI.DOUBLE],op=MPI.SUM,root=0)
if rank == 0:
number =(float(4)/n)*(out)+float(2)/n
number = "%.20f" %(number)
import time
time.sleep(0.3)
print "Pi is approximately", number