霍夫曼编码如何知道它正在读取的每个值代码的长度?
How does huffman encoding know the length of each value code it's reading?
我正在尝试了解霍夫曼编码的工作原理。我读过的所有摘要都解释了如何生成值代码,但没有解释如何实际读入它们的完整过程。我想知道算法如何知道它正在读入的每个值的位长度。
例如,如果您用代码系列“01 -- 110 -- 1101 -- 1 -- 10”表示符号字符串 "ETQ A",您如何知道一个符号从哪里开始,另一个符号从哪里开始一个结束?你怎么知道在索引 1 处读取两位,在索引 2 处读取三位,等等?
解码时,有两个给定:
- 霍夫曼编码树
- 输入字节
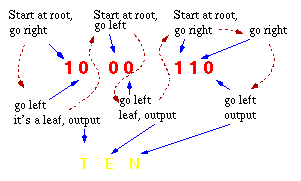
然后您只需使用这些位直到到达叶节点,此时您终止对单个字符的解码。
(来源:kirk at people.cs.pitt.edu)
然后您继续消耗位,直到所有字符都被解码
取自http://people.cs.pitt.edu/~kirk/cs1501/animations/Huffman.html
The decoding procedure is deceptively simple.
Starting with the first bit in the stream, one then uses successive bits from
the stream to determine whether
to go left or right in the decoding tree.
When we reach a leaf of the tree,
we've decoded a character, so we place
that character onto the (uncompressed)
output stream. The next bit in the
input stream is the first bit of the
next character.
我正在尝试了解霍夫曼编码的工作原理。我读过的所有摘要都解释了如何生成值代码,但没有解释如何实际读入它们的完整过程。我想知道算法如何知道它正在读入的每个值的位长度。
例如,如果您用代码系列“01 -- 110 -- 1101 -- 1 -- 10”表示符号字符串 "ETQ A",您如何知道一个符号从哪里开始,另一个符号从哪里开始一个结束?你怎么知道在索引 1 处读取两位,在索引 2 处读取三位,等等?
解码时,有两个给定:
- 霍夫曼编码树
- 输入字节
然后您只需使用这些位直到到达叶节点,此时您终止对单个字符的解码。
(来源:kirk at people.cs.pitt.edu)
{kind=link}
然后您继续消耗位,直到所有字符都被解码
取自http://people.cs.pitt.edu/~kirk/cs1501/animations/Huffman.html
The decoding procedure is deceptively simple.
Starting with the first bit in the stream, one then uses successive bits from
the stream to determine whether
to go left or right in the decoding tree.
When we reach a leaf of the tree,
we've decoded a character, so we place
that character onto the (uncompressed)
output stream. The next bit in the
input stream is the first bit of the
next character.