有人可以解释一下内容丢失功能吗?
Can someone please explain the content loss function?
我目前正在熟悉 TensorFlow 和机器学习。我正在做一些关于风格转换的教程,现在我有一部分我无法理解的示例代码。
我想我明白了主要的想法:有三个图像,内容图像,风格图像和混合图像。让我们先谈谈内容损失,因为如果我能理解这一点,我也会理解风格损失。所以我有内容图像和混合图像(从一些带有一些噪声的分布开始),以及 VGG16 模型。
据我所知,我现在应该将内容图像馈送到网络的某个层,并查看该层对于内容图像输入的输出(特征图)是什么。
之后,我还应该将混合图像的网络提供给与之前相同的层,并查看该层对于混合图像输入的输出(特征图)是什么。
然后我应该根据这两个输出计算损失函数,因为我希望混合图像具有与内容图像相似的特征图。
我的问题是我不明白我在网上找到的示例代码是如何完成的。
示例代码可以如下:
http://gcucurull.github.io/tensorflow/style-transfer/2016/08/18/neural-art-tf/
但几乎所有示例都使用相同的方法。
内容损失是这样定义的:
def content_loss(cont_out, target_out, layer, content_weight):
# content loss is just the mean square error between the outputs of a given layer
# in the content image and the target image
cont_loss = tf.reduce_sum(tf.square(tf.sub(target_out[layer], cont_out)))
# multiply the loss by its weight
cont_loss = tf.mul(cont_loss, content_weight, name="cont_loss")
return cont_loss
并这样称呼:
# compute loss
cont_cost = losses.content_loss(content_out, model, C_LAYER, content_weight)
其中 content_out 是内容图像的输出,model 是使用的模型,C_LAYER 是对我们想要输出的图层的引用,content_weight 是我们乘以的权重。
问题是我不知何故看不到这将混合图像提供给网络的位置。在我看来,"cont_loss" 计算内容图像的输出与图层本身之间的均方根。
魔法应该就在这里:
cont_loss = tf.reduce_sum(tf.square(tf.sub(target_out[layer], cont_out)))
但我根本找不到它是如何在给定层的内容图像的特征图和混合图像的特征图之间产生 RMS 的。
如果有人能指出我的错误并向我解释内容损失是如何计算的,我将不胜感激。
谢谢!
损失迫使网络在您选择的层上具有相似的激活。
让我们从 target_out[layer] 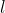 调用一个卷积 map/pixel 并从
调用一个卷积 map/pixel 并从 cont_out  调用相应的映射。您希望它们的差异
调用相应的映射。您希望它们的差异  尽可能小,即它们差异的绝对值。为了数值稳定性,我们使用平方函数而不是绝对值,因为它是一个光滑的函数并且更能容忍小误差。
尽可能小,即它们差异的绝对值。为了数值稳定性,我们使用平方函数而不是绝对值,因为它是一个光滑的函数并且更能容忍小误差。
我们因此得到%5E2) ,即:
,即:tf.square(tf.sub(target_out[layer], cont_out)).
最后,我们要最小化批处理中每个地图和每个示例的差异。这就是为什么我们使用 tf.reduce_sum.
将所有差异求和为一个标量的原因
我目前正在熟悉 TensorFlow 和机器学习。我正在做一些关于风格转换的教程,现在我有一部分我无法理解的示例代码。
我想我明白了主要的想法:有三个图像,内容图像,风格图像和混合图像。让我们先谈谈内容损失,因为如果我能理解这一点,我也会理解风格损失。所以我有内容图像和混合图像(从一些带有一些噪声的分布开始),以及 VGG16 模型。
据我所知,我现在应该将内容图像馈送到网络的某个层,并查看该层对于内容图像输入的输出(特征图)是什么。
之后,我还应该将混合图像的网络提供给与之前相同的层,并查看该层对于混合图像输入的输出(特征图)是什么。
然后我应该根据这两个输出计算损失函数,因为我希望混合图像具有与内容图像相似的特征图。
我的问题是我不明白我在网上找到的示例代码是如何完成的。
示例代码可以如下: http://gcucurull.github.io/tensorflow/style-transfer/2016/08/18/neural-art-tf/
但几乎所有示例都使用相同的方法。
内容损失是这样定义的:
def content_loss(cont_out, target_out, layer, content_weight):
# content loss is just the mean square error between the outputs of a given layer
# in the content image and the target image
cont_loss = tf.reduce_sum(tf.square(tf.sub(target_out[layer], cont_out)))
# multiply the loss by its weight
cont_loss = tf.mul(cont_loss, content_weight, name="cont_loss")
return cont_loss
并这样称呼:
# compute loss
cont_cost = losses.content_loss(content_out, model, C_LAYER, content_weight)
其中 content_out 是内容图像的输出,model 是使用的模型,C_LAYER 是对我们想要输出的图层的引用,content_weight 是我们乘以的权重。
问题是我不知何故看不到这将混合图像提供给网络的位置。在我看来,"cont_loss" 计算内容图像的输出与图层本身之间的均方根。
魔法应该就在这里:
cont_loss = tf.reduce_sum(tf.square(tf.sub(target_out[layer], cont_out)))
但我根本找不到它是如何在给定层的内容图像的特征图和混合图像的特征图之间产生 RMS 的。
如果有人能指出我的错误并向我解释内容损失是如何计算的,我将不胜感激。
谢谢!
损失迫使网络在您选择的层上具有相似的激活。
让我们从 target_out[layer] 调用一个卷积 map/pixel 并从
cont_out 调用相应的映射。您希望它们的差异
尽可能小,即它们差异的绝对值。为了数值稳定性,我们使用平方函数而不是绝对值,因为它是一个光滑的函数并且更能容忍小误差。
我们因此得到,即:
tf.square(tf.sub(target_out[layer], cont_out)).
最后,我们要最小化批处理中每个地图和每个示例的差异。这就是为什么我们使用 tf.reduce_sum.