分数函数如何帮助策略梯度?
How does score function help in policy gradient?
我正在尝试学习用于强化学习的策略梯度方法,但我停留在分数函数部分。
在函数中搜索最大或最小点时,我们取导数并将其设置为零,然后寻找满足此方程的点。
在策略梯度方法中,我们通过轨迹期望的梯度来做到这一点,我们得到:
这里我无法理解这种对数策略的梯度如何改变分布(通过其参数 θ)以增加其样本的分数数学上?难道我们没有像我上面解释的那样寻找使这个 objective 函数的梯度为零的东西吗?
你想要最大化的是
J(theta) = int( p(tau;theta)*R(tau) )
积分超过 tau(轨迹),p(tau;theta) 是它的概率(即看到序列状态、动作、下一个状态、下一个动作……),它取决于环境的动态和策略(由 theta 参数化)。正式
p(tau;theta) = p(s_0)*pi(a_0|s_0;theta)*P(s_1|s_0,a_0)*pi(a_1|s_1;theta)*P(s_2|s_1,a_1)*...
其中P(s'|s,a)是由动力学给出的转移概率。
由于我们无法控制动态,只能控制策略,我们优化 w.r.t。它的参数,我们通过梯度上升来完成,这意味着我们采用梯度给定的方向。图片中的方程式来自 log-trick df(x)/dx = f(x)*d(logf(x))/dx.
在我们的例子中 f(x) 是 p(tau;theta) 我们得到了你的等式。然后,由于我们只能访问有限数量的数据(我们的样本),我们用期望来近似积分。
一步接一步,您将(理想情况下)到达梯度为 0 的点,这意味着您达到了(局部)最优值。
你可以找到更详细的解释here。
编辑
非正式地,您可以考虑学习增加看到高概率的策略 return R(tau)。通常,R(tau)是奖励的累计总和。因此,对于每个 state-action 对 (s,a),您可以最大化在状态 s 中执行 a 并随后执行 pi 所获得的奖励总和。查看 this 精彩摘要了解更多详情(图 1)。
我正在尝试学习用于强化学习的策略梯度方法,但我停留在分数函数部分。
在函数中搜索最大或最小点时,我们取导数并将其设置为零,然后寻找满足此方程的点。
在策略梯度方法中,我们通过轨迹期望的梯度来做到这一点,我们得到:
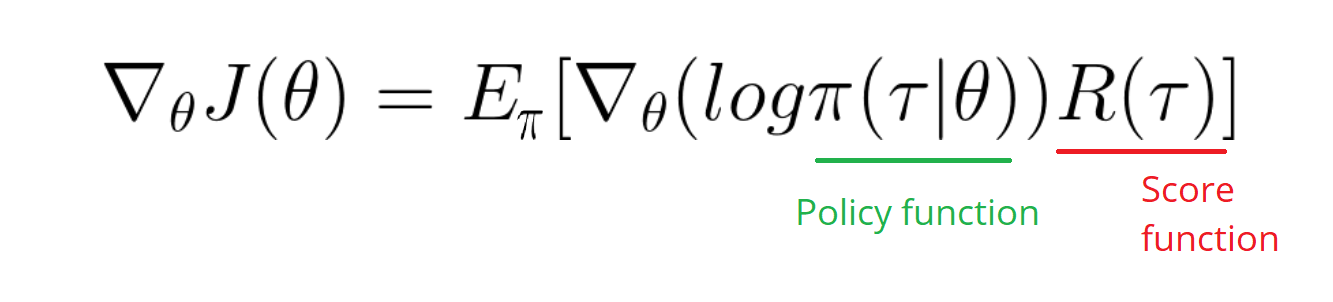{kind=link}
这里我无法理解这种对数策略的梯度如何改变分布(通过其参数 θ)以增加其样本的分数数学上?难道我们没有像我上面解释的那样寻找使这个 objective 函数的梯度为零的东西吗?
你想要最大化的是
J(theta) = int( p(tau;theta)*R(tau) )
积分超过 tau(轨迹),p(tau;theta) 是它的概率(即看到序列状态、动作、下一个状态、下一个动作……),它取决于环境的动态和策略(由 theta 参数化)。正式
p(tau;theta) = p(s_0)*pi(a_0|s_0;theta)*P(s_1|s_0,a_0)*pi(a_1|s_1;theta)*P(s_2|s_1,a_1)*...
其中P(s'|s,a)是由动力学给出的转移概率。
由于我们无法控制动态,只能控制策略,我们优化 w.r.t。它的参数,我们通过梯度上升来完成,这意味着我们采用梯度给定的方向。图片中的方程式来自 log-trick df(x)/dx = f(x)*d(logf(x))/dx.
在我们的例子中 f(x) 是 p(tau;theta) 我们得到了你的等式。然后,由于我们只能访问有限数量的数据(我们的样本),我们用期望来近似积分。
一步接一步,您将(理想情况下)到达梯度为 0 的点,这意味着您达到了(局部)最优值。
你可以找到更详细的解释here。
编辑
非正式地,您可以考虑学习增加看到高概率的策略 return R(tau)。通常,R(tau)是奖励的累计总和。因此,对于每个 state-action 对 (s,a),您可以最大化在状态 s 中执行 a 并随后执行 pi 所获得的奖励总和。查看 this 精彩摘要了解更多详情(图 1)。