多列多选调查问题的 R 频率 table
R Frequency table for multiselect survey question across several columns
我想对 R 中的调查问题做一个相当常见的分析,但卡在了中间。
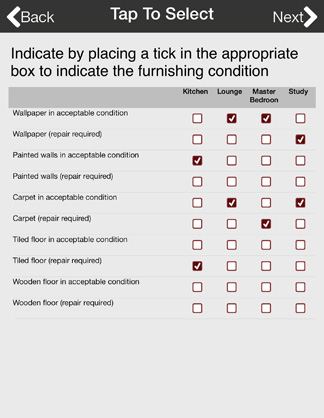
想象一下一项调查,要求您回答哪些品牌与某些功能相关(例如 "brands" 可能是 PlayStation、XBox...,功能可能是 "speed"、"graphics"... 可以检查每个品牌的几个特征,也就是 mulit-select)。例如。 ……像这样:https://www.harvestyourdata.com/fileadmin/images/question-type-screenshots/Grid-multi-select.jpg
您经常将这些问题称为多select 网格或矩阵问题。
无论如何,从数据的角度来看,这种数据通常以宽格式存储,其中每一行*列组合是一个变量,即 0/1 编码(如果调查参与者不选中该框,则为 0 , 否则为 1).
假设我们有 5 个品牌和 10 个项目,我们总共有 50 个变量,最好遵循一个漂亮的结构化命名方案,例如item1_column1、item2_column1、item3_column1、[...]、item1_column2 等等。
现在,我想在一次迭代中分析(频率 table)所有这些变量。我已经在 questionr 包中找到了 cross.multi.table 函数。但是,它只允许基于单一因素分析所有项目。我需要的是同时允许多个列。
有什么想法吗?可能是我缺少另一个包中的函数,或者这可以使用 tidyverse 甚至 cross.multi.table 函数轻松完成?
使用此数据作为测试输入:
dat = data.frame(item1_column1 = c(0,1,1,1),
item2_column1 = c(1,1,1,0),
item3_column1 = c(0,0,1,1),
item1_column2 = c(1,1,1,0),
item2_column2 = c(0,1,1,1),
item3_column2 = c(1,0,1,1),
item1_column3 = c(0,1,1,0),
item2_column3 = c(1,1,1,1),
item3_column3 = c(0,0,1,0))
我期望这样的输出:
column1 column2 column3
item1 3 3 2
item2 3 3 4
item3 2 3 1
或者理想情况下 proportions/percentages:
column1 column2 column3
item1 75% 75% 50%
item2 75% 75% 100%
item3 50% 75% 25%
一种方法是使用基于 _、group_by、item 和 [=17] 的 gather、separate 列将数据转换为长格式=] 并计算 value 列和 spread 数据与宽格式的比率。
library(dplyr)
library(tidyr)
dat %>%
gather(key, value) %>%
separate(key, into = c("item", "column"), sep = "_") %>%
group_by(item, column) %>%
summarise(prop = mean(value) * 100) %>%
spread(column, prop)
# item column1 column2 column3
# <chr> <dbl> <dbl> <dbl>
#1 item1 75 75 50
#2 item2 75 75 100
#3 item3 50 75 25
短一点(感谢@M-M)
dat %>%
summarise_all(~mean(.) * 100) %>%
gather(key, value) %>%
separate(key, into = c("item", "column"), sep = "_") %>%
spread(column, value)
我们可以在 base R 中执行此操作,方法是创建一个两列 data.frame 并复制列名,cbind 包含 unlisted 值,然后使用 xtabs 以获得 sum,同时转向 'wide' 格式
out <- xtabs(val ~ ., cbind(read.table(text = names(dat)[col(dat)],
sep="_", header = FALSE), val = unlist(dat, use.names = FALSE)))
out
# V2
#V1 column1 column2 column3
# item1 3 3 2
# item2 3 3 4
# item3 2 3 1
或者正如@GKi 提到的那样(一个紧凑的版本)将列名称拆分为 _,创建一个 data.frame 以及 colSums (或 colMeans - 百分比)并使用 xtabs 进行旋转
xtabs(n ~ ., data.frame(do.call("rbind",
strsplit(colnames(dat), "_")), n=colSums(dat)))
或获取百分比
xtabs(val ~ ., aggregate(val ~ ., cbind(read.table(text = names(dat)[col(dat)],
sep="_", header = FALSE), val = unlist(dat, use.names = FALSE)), mean)) * 100
# V2
#V1 column1 column2 column3
# item1 75 75 50
# item2 75 75 100
# item3 50 75 25
或受@GKi启发,使用enframe
library(dplyr)
library(tidyr)
library(tibble)
enframe(colSums(dat)) %>%
separate(name, into = c('name1', 'name2')) %>%
spread(name2, value)
# A tibble: 3 x 4
# name1 column1 column2 column3
# <chr> <dbl> <dbl> <dbl>
#1 item1 3 3 2
#2 item2 3 3 4
#3 item3 2 3 1
要获取百分比,只需将第一行代码更改为
enframe(100 *colMeans(dat))
我在这里所做的,通过使用 data.table 包,汇总每一列,将数据转换为长格式,将一列分成两列(item 和 column),以及最后转换为宽格式。往下看;
library(data.table)
dcast(setDT(melt(setDT(dat)[,100*colMeans(.SD),]),keep.rownames = T)[,
c("item", "column") := tstrsplit(rn, "_", fixed=TRUE)],
item ~ column, value.var = "value")
#> item column1 column2 column3
#> 1: item1 75 75 50
#> 2: item2 75 75 100
#> 3: item3 50 75 25
我想对 R 中的调查问题做一个相当常见的分析,但卡在了中间。
想象一下一项调查,要求您回答哪些品牌与某些功能相关(例如 "brands" 可能是 PlayStation、XBox...,功能可能是 "speed"、"graphics"... 可以检查每个品牌的几个特征,也就是 mulit-select)。例如。 ……像这样:https://www.harvestyourdata.com/fileadmin/images/question-type-screenshots/Grid-multi-select.jpg
{kind=link}
您经常将这些问题称为多select 网格或矩阵问题。
无论如何,从数据的角度来看,这种数据通常以宽格式存储,其中每一行*列组合是一个变量,即 0/1 编码(如果调查参与者不选中该框,则为 0 , 否则为 1).
假设我们有 5 个品牌和 10 个项目,我们总共有 50 个变量,最好遵循一个漂亮的结构化命名方案,例如item1_column1、item2_column1、item3_column1、[...]、item1_column2 等等。
现在,我想在一次迭代中分析(频率 table)所有这些变量。我已经在 questionr 包中找到了 cross.multi.table 函数。但是,它只允许基于单一因素分析所有项目。我需要的是同时允许多个列。
有什么想法吗?可能是我缺少另一个包中的函数,或者这可以使用 tidyverse 甚至 cross.multi.table 函数轻松完成?
使用此数据作为测试输入:
dat = data.frame(item1_column1 = c(0,1,1,1),
item2_column1 = c(1,1,1,0),
item3_column1 = c(0,0,1,1),
item1_column2 = c(1,1,1,0),
item2_column2 = c(0,1,1,1),
item3_column2 = c(1,0,1,1),
item1_column3 = c(0,1,1,0),
item2_column3 = c(1,1,1,1),
item3_column3 = c(0,0,1,0))
我期望这样的输出:
column1 column2 column3
item1 3 3 2
item2 3 3 4
item3 2 3 1
或者理想情况下 proportions/percentages:
column1 column2 column3
item1 75% 75% 50%
item2 75% 75% 100%
item3 50% 75% 25%
一种方法是使用基于 _、group_by、item 和 [=17] 的 gather、separate 列将数据转换为长格式=] 并计算 value 列和 spread 数据与宽格式的比率。
library(dplyr)
library(tidyr)
dat %>%
gather(key, value) %>%
separate(key, into = c("item", "column"), sep = "_") %>%
group_by(item, column) %>%
summarise(prop = mean(value) * 100) %>%
spread(column, prop)
# item column1 column2 column3
# <chr> <dbl> <dbl> <dbl>
#1 item1 75 75 50
#2 item2 75 75 100
#3 item3 50 75 25
短一点(感谢@M-M)
dat %>%
summarise_all(~mean(.) * 100) %>%
gather(key, value) %>%
separate(key, into = c("item", "column"), sep = "_") %>%
spread(column, value)
我们可以在 base R 中执行此操作,方法是创建一个两列 data.frame 并复制列名,cbind 包含 unlisted 值,然后使用 xtabs 以获得 sum,同时转向 'wide' 格式
out <- xtabs(val ~ ., cbind(read.table(text = names(dat)[col(dat)],
sep="_", header = FALSE), val = unlist(dat, use.names = FALSE)))
out
# V2
#V1 column1 column2 column3
# item1 3 3 2
# item2 3 3 4
# item3 2 3 1
或者正如@GKi 提到的那样(一个紧凑的版本)将列名称拆分为 _,创建一个 data.frame 以及 colSums (或 colMeans - 百分比)并使用 xtabs 进行旋转
xtabs(n ~ ., data.frame(do.call("rbind",
strsplit(colnames(dat), "_")), n=colSums(dat)))
或获取百分比
xtabs(val ~ ., aggregate(val ~ ., cbind(read.table(text = names(dat)[col(dat)],
sep="_", header = FALSE), val = unlist(dat, use.names = FALSE)), mean)) * 100
# V2
#V1 column1 column2 column3
# item1 75 75 50
# item2 75 75 100
# item3 50 75 25
或受@GKi启发,使用enframe
library(dplyr)
library(tidyr)
library(tibble)
enframe(colSums(dat)) %>%
separate(name, into = c('name1', 'name2')) %>%
spread(name2, value)
# A tibble: 3 x 4
# name1 column1 column2 column3
# <chr> <dbl> <dbl> <dbl>
#1 item1 3 3 2
#2 item2 3 3 4
#3 item3 2 3 1
要获取百分比,只需将第一行代码更改为
enframe(100 *colMeans(dat))
我在这里所做的,通过使用 data.table 包,汇总每一列,将数据转换为长格式,将一列分成两列(item 和 column),以及最后转换为宽格式。往下看;
library(data.table)
dcast(setDT(melt(setDT(dat)[,100*colMeans(.SD),]),keep.rownames = T)[,
c("item", "column") := tstrsplit(rn, "_", fixed=TRUE)],
item ~ column, value.var = "value")
#> item column1 column2 column3
#> 1: item1 75 75 50
#> 2: item2 75 75 100
#> 3: item3 50 75 25