功能广度优先搜索
Functional Breadth First Search
功能深度优先搜索在有向无环图中很可爱。
然而在有环的图中,我们如何避免无限递归?在程序语言中,我会在点击时标记节点,但假设我不能那样做。
访问节点的列表是可能的,但会很慢,因为使用一个将导致在重复之前对该列表进行线性搜索。比这里的列表更好的数据结构显然会有所帮助,但这不是游戏的目的,因为我在 ML 中编码 - 列表是王道,其他任何东西我都必须自己写。
有没有解决这个问题的巧妙方法?或者我将不得不使用访问列表或者,上帝保佑,可变状态?
您必须跟踪您访问的节点。列表不是 ML 家族中的王者,它们只是寡头之一。您应该只使用一个集合(基于树)来跟踪访问过的节点。与改变节点状态相比,这将增加一个对数因子,但是更清晰,这并不好笑。如果您对节点了解更多,则可以通过使用不基于树(比如位向量)的集合来消除对数因子。
在函数中隐藏一个可变状态是很不错的。如果它不可见,则它不存在。我通常为此使用哈希集。但总的来说,如果您的分析指出了这一点,您应该坚持这一点。否则,只需使用集合数据结构。 OCaml 有一个基于急切平衡的 AVL 树的优秀集合。
参见example implementation of BFS,
在 Martin Erwig: Inductive Graphs and Functional Graph Algorithms. Also, DFS implementation, based on David King , John Launchbury: Structuring Depth-First Search Algorithms in Haskell
中有解释
(对 S.O 的提示。警察:是的,这看起来像一个 link-only answer,但这就是科学的运作方式 - 你必须真正阅读论文,重新输入他们的摘要不是很有用。)
一种选择是使用归纳图,这是一种表示和处理任意图结构的函数式方法。它们由 Martin Erwig 的 Haskell 的 fgl library and described in "Inductive Graphs and Funtional Graph Algorithms" 提供。
有关更温和的介绍(带插图!),请参阅我的博客 post Generating Mazes with Inductive Graphs。
归纳图的诀窍在于它们可以让你图上的模式匹配。使用列表的常见功能习惯用法是将它们分解为一个头元素和列表的其余部分,然后对其进行递归:
map f [] = []
map f (x:xs) = f x : map f xs
归纳图可以让您做同样的事情,但对于图表。您可以将归纳图分解为一个节点、它的边和图的其余部分。
(来源:jelv.is)
这里我们匹配节点 1 及其所有边(以蓝色突出显示),与图的其余部分分开。
这让我们可以为图编写 map(在 Haskellish 伪代码中,可以用模式同义词实现):
gmap f Empty = Empty
gmap f ((in, node, out) :& rest) = f (in, node, out) :& gmap f rest
与列表相比,这种方法的主要缺点是图没有单一的自然分解方式:同一个图可以用多种方式构建。上面的地图代码将访问所有的顶点,但是以任意(依赖于实现)的顺序。
为了克服这个问题,我们添加了另一个结构:一个接受特定节点的 match 函数。如果该节点在我们的图中,我们就会像上面一样获得成功的匹配;如果不是,则整个匹配失败。
这个构造足以编写 DFS 或 BFS——使用优雅的代码,两者看起来几乎相同!
我们不是手动将节点标记为已访问,而是对图的其余部分进行递归 除了 我们现在看到的节点:在每一步,我们都在使用原始图形的越来越小的部分。如果我们尝试访问一个我们已经用 match 看到的节点,它不会在剩余的图中并且该分支将失败。这让我们的图形处理代码看起来就像我们在列表上的普通递归函数。
这是此类图的 DFS。它将to visit的节点栈保存为一个列表(边界),并以初始边界开始。输出是按顺序遍历的节点列表。 (如果没有一些自定义模式同义词,这里的确切代码不能直接用库编写。)
dfs _frontier Empty = []
dfs [] _graph = []
dfs (n:ns) (match n -> Just (ctx, rest)) = -- not visited n
dfs (neighbors' ctx ++ ns) rest
dfs (n:ns) graph = -- visited n
dfs ns graph
一个非常简单的递归函数。要将其变成广度优先搜索,我们所要做的就是用队列替换堆栈边界:我们不是将邻居放在列表的 front 上,而是放在返回:
bfs _frontier Empty = []
bfs [] _graph = []
bfs (n:ns) (match n -> Just (ctx, rest)) = -- not visited n
bfs (ns ++ neighbors' ctx) rest
bfs (n:ns) graph = -- visited n
bfs ns graph
是的,这就是我们所需要的!我们不必做任何特殊的事情来跟踪我们在图上递归时访问过的节点,就像我们不必跟踪我们访问过的列表单元格一样:每次递归时,我们我们只得到了图表中我们没有看到的部分。
功能深度优先搜索在有向无环图中很可爱。
然而在有环的图中,我们如何避免无限递归?在程序语言中,我会在点击时标记节点,但假设我不能那样做。
访问节点的列表是可能的,但会很慢,因为使用一个将导致在重复之前对该列表进行线性搜索。比这里的列表更好的数据结构显然会有所帮助,但这不是游戏的目的,因为我在 ML 中编码 - 列表是王道,其他任何东西我都必须自己写。
有没有解决这个问题的巧妙方法?或者我将不得不使用访问列表或者,上帝保佑,可变状态?
您必须跟踪您访问的节点。列表不是 ML 家族中的王者,它们只是寡头之一。您应该只使用一个集合(基于树)来跟踪访问过的节点。与改变节点状态相比,这将增加一个对数因子,但是更清晰,这并不好笑。如果您对节点了解更多,则可以通过使用不基于树(比如位向量)的集合来消除对数因子。
在函数中隐藏一个可变状态是很不错的。如果它不可见,则它不存在。我通常为此使用哈希集。但总的来说,如果您的分析指出了这一点,您应该坚持这一点。否则,只需使用集合数据结构。 OCaml 有一个基于急切平衡的 AVL 树的优秀集合。
参见example implementation of BFS, 在 Martin Erwig: Inductive Graphs and Functional Graph Algorithms. Also, DFS implementation, based on David King , John Launchbury: Structuring Depth-First Search Algorithms in Haskell
中有解释(对 S.O 的提示。警察:是的,这看起来像一个 link-only answer,但这就是科学的运作方式 - 你必须真正阅读论文,重新输入他们的摘要不是很有用。)
一种选择是使用归纳图,这是一种表示和处理任意图结构的函数式方法。它们由 Martin Erwig 的 Haskell 的 fgl library and described in "Inductive Graphs and Funtional Graph Algorithms" 提供。
有关更温和的介绍(带插图!),请参阅我的博客 post Generating Mazes with Inductive Graphs。
归纳图的诀窍在于它们可以让你图上的模式匹配。使用列表的常见功能习惯用法是将它们分解为一个头元素和列表的其余部分,然后对其进行递归:
map f [] = []
map f (x:xs) = f x : map f xs
归纳图可以让您做同样的事情,但对于图表。您可以将归纳图分解为一个节点、它的边和图的其余部分。
(来源:jelv.is)
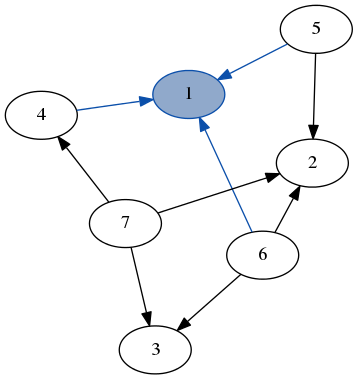{kind=link}
这里我们匹配节点 1 及其所有边(以蓝色突出显示),与图的其余部分分开。
这让我们可以为图编写 map(在 Haskellish 伪代码中,可以用模式同义词实现):
gmap f Empty = Empty
gmap f ((in, node, out) :& rest) = f (in, node, out) :& gmap f rest
与列表相比,这种方法的主要缺点是图没有单一的自然分解方式:同一个图可以用多种方式构建。上面的地图代码将访问所有的顶点,但是以任意(依赖于实现)的顺序。
为了克服这个问题,我们添加了另一个结构:一个接受特定节点的 match 函数。如果该节点在我们的图中,我们就会像上面一样获得成功的匹配;如果不是,则整个匹配失败。
这个构造足以编写 DFS 或 BFS——使用优雅的代码,两者看起来几乎相同!
我们不是手动将节点标记为已访问,而是对图的其余部分进行递归 除了 我们现在看到的节点:在每一步,我们都在使用原始图形的越来越小的部分。如果我们尝试访问一个我们已经用 match 看到的节点,它不会在剩余的图中并且该分支将失败。这让我们的图形处理代码看起来就像我们在列表上的普通递归函数。
这是此类图的 DFS。它将to visit的节点栈保存为一个列表(边界),并以初始边界开始。输出是按顺序遍历的节点列表。 (如果没有一些自定义模式同义词,这里的确切代码不能直接用库编写。)
dfs _frontier Empty = []
dfs [] _graph = []
dfs (n:ns) (match n -> Just (ctx, rest)) = -- not visited n
dfs (neighbors' ctx ++ ns) rest
dfs (n:ns) graph = -- visited n
dfs ns graph
一个非常简单的递归函数。要将其变成广度优先搜索,我们所要做的就是用队列替换堆栈边界:我们不是将邻居放在列表的 front 上,而是放在返回:
bfs _frontier Empty = []
bfs [] _graph = []
bfs (n:ns) (match n -> Just (ctx, rest)) = -- not visited n
bfs (ns ++ neighbors' ctx) rest
bfs (n:ns) graph = -- visited n
bfs ns graph
是的,这就是我们所需要的!我们不必做任何特殊的事情来跟踪我们在图上递归时访问过的节点,就像我们不必跟踪我们访问过的列表单元格一样:每次递归时,我们我们只得到了图表中我们没有看到的部分。