如何使用 python 和 PIL 检测图像的特定边界细节并根据它进行裁剪?
How to detect a specific border detail of an image and crop according to it using python and PIL?
我目前正在尝试通过检测文档右上角和左下角的 2 个大黑角来裁剪图像:http://www.suiteexpert.fr/AideProd/SalaireExpert/Images/Editions/aemapercu.png
我试图找到一种比深度学习 OCR 更简单的方法来获得更好的性能。
我尝试了几种不同的方法,例如检测颜色变化,从文档的边缘开始检测从白色到黑色的变化。这似乎可行,但它首先检测到一些图像示例中非常小的垂直文本:https://www.movinmotion.com/wp-content/uploads/2018/03/AEM-V5-MM-.jpg
这也导致了其他问题,因为我要分析的文件也可能是不同颜色的,也可能是扫描件或照片。
但是,这些文件将始终具有相同的内部形状和结构(这是标准化的行政文件)。
关于如何检测文档右上角和左下角的 2 个大黑角,我希望得到您的一些反馈,这将允许我通过旋转和裁剪图像来处理和标准化图像。
from PIL import Image, ImageChops
def trim(im, border):
bg = Image.new(im.mode, im.size, border)
diff = ImageChops.difference(im, bg)
bbox = diff.getbbox()
if bbox:
return im.crop(bbox)
else:
# found no content
raise ValueError("cannot trim; image was empty")
提前感谢您的帮助!
目前我没有时间在 Python 中写这篇文章,但是如果您按照以下步骤操作,您可以做到:
使用矩形 5x5 结构元素做一个 "morphological closing" 以去除边缘(以及其他任何地方)周围的细线
trim 去除图像边缘多余的白色边框
我在终端中用 ImageMagick 做的是这样的:
convert form.png -threshold 50% -morphology close rectangle:5 -trim result.png
然后偷偷添加了一个红色边框,这样您就可以在 Stack Overflow 的白色背景上看到图像的范围:
在 Python 中,使用 skimage 进行形态学 - 它看起来像这些行:
# Convert edges to Numpy array and dilate (fatten) with our square structuring element
selem = square(6)
fatedges = dilation(np.array(edges),selem)
在 , except you will need binary_closing() in place of dilation() - see documentation here.
然后您可以用 PIL/Pillow 的 Image.getbbox() 进行 trim 训练。当然,您将 trim 框应用于原始图像的干净副本,而不是形态改变的图像:-)
您还可以使用 "Hit-or-Miss morphology" 在右上角查找 L 形状。您定义一个必须 命中 图像的形状,以及一个必须 命中 图像的形状,它会告诉您这两种情况都为真。文档是 here.
如果我们放大右上角的 L 形状直到您可以数出各个像素,您会看到 L 的水平条大约为 18x6 像素:
所以,
import scipy as sp
import numpy as np
import cv2
# Load image
form=cv2.imread('form.png',cv2.IMREAD_GRAYSCALE)
# We are going to do Hit-or-Miss morphology, define structuring elements
hit = np.zeros((10,10), dtype=np.int)
hit[:,-4:]=1
hit[:4,:]=1
看起来像这样:
array([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1]])
现在定义我们必须错过的:
miss = np.zeros_like(hit)
miss[-4:,:4]=1
看起来像这样:
array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 0, 0, 0, 0, 0, 0]])
现在应用命中或未命中:
res = sp.ndimage.binary_hit_or_miss(1-(form.astype(np.bool)),structure1=hit,structure2=miss)
cv2.imwrite('result.png',res*255)
希望您能在找到此图案的右上角看到一个白点。
形态学处理的nett效果是我们正在寻找一个匹配这个的形状,其中B代表黑色,W代表白色,X代表"don't care":
B, B, B, B, B, B, B, B, B, B
B, B, B, B, B, B, B, B, B, B
B, B, B, B, B, B, B, B, B, B
B, B, B, B, B, B, B, B, B, B
X, X, X, X, X, X, B, B, B, B
X, X, X, X, X, X, B, B, B, B
W, W, W, W, X, X, B, B, B, B
W, W, W, W, X, X, B, B, B, B
W, W, W, W, X, X, B, B, B, B
W, W, W, W, X, X, B, B, B, B
然后用转置的形状重复以寻找左下角的 L 形状。
关键字: Python, skimage, scikit-image, shape detection, morphology, morphological, Hit-or-miss, hit or miss, don't care , 命中未命中, 图片, 图片处理.
我目前正在尝试通过检测文档右上角和左下角的 2 个大黑角来裁剪图像:http://www.suiteexpert.fr/AideProd/SalaireExpert/Images/Editions/aemapercu.png 我试图找到一种比深度学习 OCR 更简单的方法来获得更好的性能。
{kind=link}
我尝试了几种不同的方法,例如检测颜色变化,从文档的边缘开始检测从白色到黑色的变化。这似乎可行,但它首先检测到一些图像示例中非常小的垂直文本:https://www.movinmotion.com/wp-content/uploads/2018/03/AEM-V5-MM-.jpg
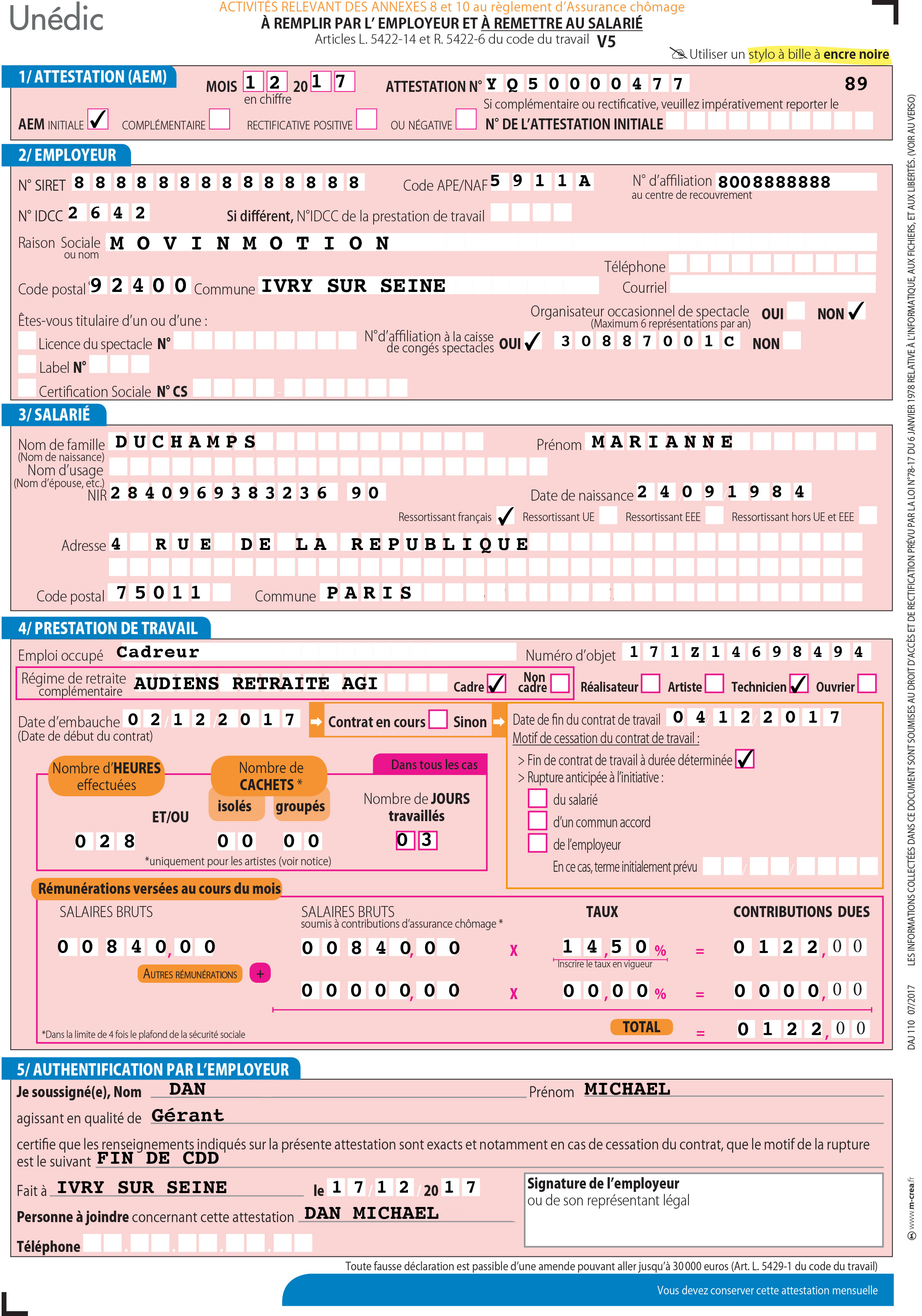{kind=link}
这也导致了其他问题,因为我要分析的文件也可能是不同颜色的,也可能是扫描件或照片。
但是,这些文件将始终具有相同的内部形状和结构(这是标准化的行政文件)。
关于如何检测文档右上角和左下角的 2 个大黑角,我希望得到您的一些反馈,这将允许我通过旋转和裁剪图像来处理和标准化图像。
from PIL import Image, ImageChops
def trim(im, border):
bg = Image.new(im.mode, im.size, border)
diff = ImageChops.difference(im, bg)
bbox = diff.getbbox()
if bbox:
return im.crop(bbox)
else:
# found no content
raise ValueError("cannot trim; image was empty")
提前感谢您的帮助!
目前我没有时间在 Python 中写这篇文章,但是如果您按照以下步骤操作,您可以做到:
使用矩形 5x5 结构元素做一个 "morphological closing" 以去除边缘(以及其他任何地方)周围的细线
trim 去除图像边缘多余的白色边框
我在终端中用 ImageMagick 做的是这样的:
convert form.png -threshold 50% -morphology close rectangle:5 -trim result.png
然后偷偷添加了一个红色边框,这样您就可以在 Stack Overflow 的白色背景上看到图像的范围:
在 Python 中,使用 skimage 进行形态学 - 它看起来像这些行:
# Convert edges to Numpy array and dilate (fatten) with our square structuring element
selem = square(6)
fatedges = dilation(np.array(edges),selem)
在 binary_closing() in place of dilation() - see documentation here.
然后您可以用 PIL/Pillow 的 Image.getbbox() 进行 trim 训练。当然,您将 trim 框应用于原始图像的干净副本,而不是形态改变的图像:-)
您还可以使用 "Hit-or-Miss morphology" 在右上角查找 L 形状。您定义一个必须 命中 图像的形状,以及一个必须 命中 图像的形状,它会告诉您这两种情况都为真。文档是 here.
如果我们放大右上角的 L 形状直到您可以数出各个像素,您会看到 L 的水平条大约为 18x6 像素:
所以,
import scipy as sp
import numpy as np
import cv2
# Load image
form=cv2.imread('form.png',cv2.IMREAD_GRAYSCALE)
# We are going to do Hit-or-Miss morphology, define structuring elements
hit = np.zeros((10,10), dtype=np.int)
hit[:,-4:]=1
hit[:4,:]=1
看起来像这样:
array([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1]])
现在定义我们必须错过的:
miss = np.zeros_like(hit)
miss[-4:,:4]=1
看起来像这样:
array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 0, 0, 0, 0, 0, 0]])
现在应用命中或未命中:
res = sp.ndimage.binary_hit_or_miss(1-(form.astype(np.bool)),structure1=hit,structure2=miss)
cv2.imwrite('result.png',res*255)
希望您能在找到此图案的右上角看到一个白点。
形态学处理的nett效果是我们正在寻找一个匹配这个的形状,其中B代表黑色,W代表白色,X代表"don't care":
B, B, B, B, B, B, B, B, B, B
B, B, B, B, B, B, B, B, B, B
B, B, B, B, B, B, B, B, B, B
B, B, B, B, B, B, B, B, B, B
X, X, X, X, X, X, B, B, B, B
X, X, X, X, X, X, B, B, B, B
W, W, W, W, X, X, B, B, B, B
W, W, W, W, X, X, B, B, B, B
W, W, W, W, X, X, B, B, B, B
W, W, W, W, X, X, B, B, B, B
然后用转置的形状重复以寻找左下角的 L 形状。
关键字: Python, skimage, scikit-image, shape detection, morphology, morphological, Hit-or-miss, hit or miss, don't care , 命中未命中, 图片, 图片处理.