如何使用归一化来设置评分与 Python 或 SQL 中的评分数量之间的置信度?
How to use normalization to set levels of confidence between a rating and the number of ratings in Python or SQL?
我有大约 800 个具有评级(从 1 到 5)的销售商品的列表,以及评级的数量。我想以公正的方式列出最有可能获得 "good" 评级的项目,这意味着 1 人投票 5.0 不如 50 人投票和该项目的评级一个 4.5.
最初我考虑的是获得最少的选票(99% 的情况下为零),以及列表中某项的最高选票并将其计入评级,这让我有信心0 到 100% 的水平,但是我认为这种方法太简单了。
我听说过贝叶斯概率,但我不知道如何实现它。我的项目列表、评分和评分数量在 MySQL 视图中,但我正在使用 Python 解析代码,因此我可以在任一侧进行计算(但最好在 SQL 查看).
有没有什么实用的方法可以使 SQL 的投票正常化,将评级和票数作为参数?
|----------|--------|--------------|
| itemCode | rating | numOfRatings |
|----------|--------|--------------|
| 12330 | 5.00 | 2 |
| 85763 | 4.65 | 36 |
| 85333 | 3.11 | 9 |
|----------|--------|--------------|
我已经开始尝试为评级和 numOfRatings 分配百分位数,这样我就可以进行标准化(将它们与初始 50/50 权重相加)。这是我尝试过的代码:
SELECT p.itemCode AS itemCode, (p.rating - min(p.rating)) / (max(p.rating) - min(p.rating)) AS percentil_rating,
(p.numOfRatings - min(p.numOfRatings)) / (max(p.numOfRatings) - min(p.numOfRatings)) AS percentil_qtd_ratings
FROM products p
WHERE p.available = 1
GROUP BY p.itemCode
然而,这只会给我带来列表中第一个 itemCode 的结果,而不是所有结果。
很明显,这里的问题是您的数据的观测值太少。实施贝叶斯方法是可行的方法,因为它为涉及评级的应用程序提供了很好的概率分布,尤其是在观察有限的情况下,并且它很容易根据给定的参数决定未来的似然比(这个 article 提供了关于贝叶斯的一个很好的解释初学者的概率)。
我建议将您的数据存储在 CSV 文件中,以便在 python 中更容易操作。通过连接对数据进行非规范化是分析评级之前要做的首要任务。
这是要在您的 python 代码中使用的贝叶斯简化公式:
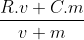
R – Confidence level aka number of observations
v – number of votes for a single product
C – avg vote for all products
m - tuneable parameter aka cutoff number required for votes to be considered (How many votes do you want displayed)
由于这是简化的公式,因此article explains how its been derived from its original formula. This article也有助于解释参数。
了解公式几乎可以完成 50% 的工作,剩下的只是导入数据并使用它。我在下面提供了与您的问题类似的示例,以备您需要完整演示时使用:
我有大约 800 个具有评级(从 1 到 5)的销售商品的列表,以及评级的数量。我想以公正的方式列出最有可能获得 "good" 评级的项目,这意味着 1 人投票 5.0 不如 50 人投票和该项目的评级一个 4.5.
最初我考虑的是获得最少的选票(99% 的情况下为零),以及列表中某项的最高选票并将其计入评级,这让我有信心0 到 100% 的水平,但是我认为这种方法太简单了。
我听说过贝叶斯概率,但我不知道如何实现它。我的项目列表、评分和评分数量在 MySQL 视图中,但我正在使用 Python 解析代码,因此我可以在任一侧进行计算(但最好在 SQL 查看).
有没有什么实用的方法可以使 SQL 的投票正常化,将评级和票数作为参数?
|----------|--------|--------------|
| itemCode | rating | numOfRatings |
|----------|--------|--------------|
| 12330 | 5.00 | 2 |
| 85763 | 4.65 | 36 |
| 85333 | 3.11 | 9 |
|----------|--------|--------------|
我已经开始尝试为评级和 numOfRatings 分配百分位数,这样我就可以进行标准化(将它们与初始 50/50 权重相加)。这是我尝试过的代码:
SELECT p.itemCode AS itemCode, (p.rating - min(p.rating)) / (max(p.rating) - min(p.rating)) AS percentil_rating,
(p.numOfRatings - min(p.numOfRatings)) / (max(p.numOfRatings) - min(p.numOfRatings)) AS percentil_qtd_ratings
FROM products p
WHERE p.available = 1
GROUP BY p.itemCode
然而,这只会给我带来列表中第一个 itemCode 的结果,而不是所有结果。
很明显,这里的问题是您的数据的观测值太少。实施贝叶斯方法是可行的方法,因为它为涉及评级的应用程序提供了很好的概率分布,尤其是在观察有限的情况下,并且它很容易根据给定的参数决定未来的似然比(这个 article 提供了关于贝叶斯的一个很好的解释初学者的概率)。
我建议将您的数据存储在 CSV 文件中,以便在 python 中更容易操作。通过连接对数据进行非规范化是分析评级之前要做的首要任务。
这是要在您的 python 代码中使用的贝叶斯简化公式:
R – Confidence level aka number of observations
v – number of votes for a single product
C – avg vote for all products
m - tuneable parameter aka cutoff number required for votes to be considered (How many votes do you want displayed)
由于这是简化的公式,因此article explains how its been derived from its original formula. This article也有助于解释参数。
了解公式几乎可以完成 50% 的工作,剩下的只是导入数据并使用它。我在下面提供了与您的问题类似的示例,以备您需要完整演示时使用: