自适应替换缓存算法
Adaptive replacement cache algorithm
我正在尝试实现自适应替换缓存算法,但是,我正在阅读文献,但我无法理解该算法。谁能给我解释一下这个算法?
我看到它使用两个列表 L1 到频率和 L2 到新近度。但是对于 L1 和 L2 列表的 T1、B1 和 T2、B2,我无法理解。
ftp://paranoidbits.com/ebooks/Outperforming%20LRU%20with%20an%20Adaptive%20Replacement%20Cache.pdf 在本文中我看到了这个信息。
T1 和 T2 保存正在缓存的实际数据。 T1 保存所有被恰好引用过一次的数据(页面)。 T2 保存已被引用 2 次或更多次的页面。 B1 是一个幽灵列表,用于记住哪些页面曾经在 T1 缓存中。 B2同理,只是针对T2缓存。当您将 T1 和 B1 加在一起时,您会得到一组(称为 L1)对页面的引用,这些页面曾经或当前被缓存,因为它们被引用过一次。 L2 也是如此,只是它包含对那些页面至少被引用两次的引用。
T1 和 T2 共享一组固定大小的插槽(每个插槽可以容纳一页),我们使用 B1 和 B2 来决定如何在 T1 和 T2 之间共享这些插槽。这就是 ARC 自适应的原因——自动调整谁获得最多的插槽。如果 B1 持有对同一个页面的多个引用,这意味着我们不允许 T1 持有其页面足够长的时间,并且应该允许它有更多的插槽来应对这种情况。 B2也是一样。
我不会在这里尝试解释整个算法,但这至少是我对 ARC 列表的理解。
我想强调一些关键思想,并帮助您了解论文的叙述。这应该可以帮助您培养对 ARC 的一些直觉。
我们从大小为 c 的 LRU 缓存开始。除了页面缓存之外,我们还维护了一个大小为c的缓存目录T,它是只是一组描述缓存中页面的元数据。页面元数据包含例如页面在存储介质中的物理地址。
现在,观察 LRU 不是抗扫描的。如果进程拉取一系列 c 页面,缓存中的每个页面都将被逐出。这不是很有效,我们希望能够针对新近度和频率进行优化。
关键思想 #1:将缓存分成 2 个列表:T1 和 T2。 T1 包含最近使用的页面,T2 包含经常使用的页面。这是抗扫描的,因为扫描会导致 T1 被清空,但 T2 基本不受影响。
当缓存已满时,算法必须选择从 T1 或 T2 中驱逐受害者。请注意,这些列表不必具有相同的大小,我们可以根据访问模式智能地将更多缓存分配给最近的页面或频繁访问的页面。您可以在这里发明自己的启发式。
关键思想 #2:保留额外的历史记录。让 B1 和 B2 跟踪 T1 和 T2[ 中被逐出页面的元数据=55=]分别。如果我们观察到 T1 中的许多缓存未命中在 B1 中命中,我们会对驱逐感到遗憾,并将更多缓存分配给 T1.
ARC 保留一个数字 p 以在 T1 和 T2 之间拆分缓存。
关键思想 #3:在 T1 中的缓存未命中和 B1 中的命中时,ARC 增加 p 通过
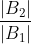 。这是 "delta" 或 "regret ratio",它将 B1 中的命中概率与 B2[= 中的命中概率进行比较55=],假设在所有页面上均匀分布。
。这是 "delta" 或 "regret ratio",它将 B1 中的命中概率与 B2[= 中的命中概率进行比较55=],假设在所有页面上均匀分布。
我正在尝试实现自适应替换缓存算法,但是,我正在阅读文献,但我无法理解该算法。谁能给我解释一下这个算法? 我看到它使用两个列表 L1 到频率和 L2 到新近度。但是对于 L1 和 L2 列表的 T1、B1 和 T2、B2,我无法理解。
ftp://paranoidbits.com/ebooks/Outperforming%20LRU%20with%20an%20Adaptive%20Replacement%20Cache.pdf 在本文中我看到了这个信息。
T1 和 T2 保存正在缓存的实际数据。 T1 保存所有被恰好引用过一次的数据(页面)。 T2 保存已被引用 2 次或更多次的页面。 B1 是一个幽灵列表,用于记住哪些页面曾经在 T1 缓存中。 B2同理,只是针对T2缓存。当您将 T1 和 B1 加在一起时,您会得到一组(称为 L1)对页面的引用,这些页面曾经或当前被缓存,因为它们被引用过一次。 L2 也是如此,只是它包含对那些页面至少被引用两次的引用。
T1 和 T2 共享一组固定大小的插槽(每个插槽可以容纳一页),我们使用 B1 和 B2 来决定如何在 T1 和 T2 之间共享这些插槽。这就是 ARC 自适应的原因——自动调整谁获得最多的插槽。如果 B1 持有对同一个页面的多个引用,这意味着我们不允许 T1 持有其页面足够长的时间,并且应该允许它有更多的插槽来应对这种情况。 B2也是一样。
我不会在这里尝试解释整个算法,但这至少是我对 ARC 列表的理解。
我想强调一些关键思想,并帮助您了解论文的叙述。这应该可以帮助您培养对 ARC 的一些直觉。
我们从大小为 c 的 LRU 缓存开始。除了页面缓存之外,我们还维护了一个大小为c的缓存目录T,它是只是一组描述缓存中页面的元数据。页面元数据包含例如页面在存储介质中的物理地址。
现在,观察 LRU 不是抗扫描的。如果进程拉取一系列 c 页面,缓存中的每个页面都将被逐出。这不是很有效,我们希望能够针对新近度和频率进行优化。
关键思想 #1:将缓存分成 2 个列表:T1 和 T2。 T1 包含最近使用的页面,T2 包含经常使用的页面。这是抗扫描的,因为扫描会导致 T1 被清空,但 T2 基本不受影响。
当缓存已满时,算法必须选择从 T1 或 T2 中驱逐受害者。请注意,这些列表不必具有相同的大小,我们可以根据访问模式智能地将更多缓存分配给最近的页面或频繁访问的页面。您可以在这里发明自己的启发式。
关键思想 #2:保留额外的历史记录。让 B1 和 B2 跟踪 T1 和 T2[ 中被逐出页面的元数据=55=]分别。如果我们观察到 T1 中的许多缓存未命中在 B1 中命中,我们会对驱逐感到遗憾,并将更多缓存分配给 T1.
ARC 保留一个数字 p 以在 T1 和 T2 之间拆分缓存。
关键思想 #3:在 T1 中的缓存未命中和 B1 中的命中时,ARC 增加 p 通过
。这是 "delta" 或 "regret ratio",它将 B1 中的命中概率与 B2[= 中的命中概率进行比较55=],假设在所有页面上均匀分布。