PyTorch 是否具有按元素乘积和求和的隐式函数?
Does PyTorch have implicit functions for element-wise product and sum?
我正在尝试通过 Yulun Zhang 等人在 Tensorflow 中实现用于超分辨率的 RCAN(与论文一起发布的原始代码是在 PyTorch 中实现的:https://github.com/yulunzhang/RCAN)。
我想了解他们是如何实施 RCAB 的。通过查看他们发布的网络架构图,神经网络的构建方式似乎非常简单。但是代码好像不匹配
根据此处的图表:https://raw.githubusercontent.com/yulunzhang/RCAN/master/Figs/RCAB.PNG
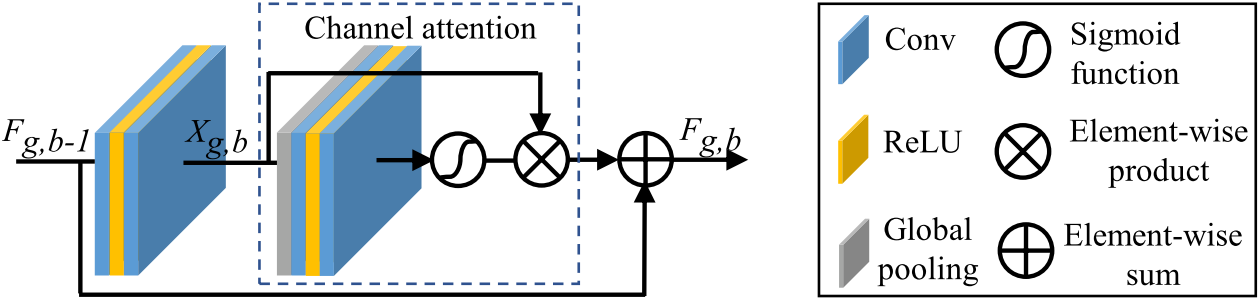
每个 RCAB 应具有以下结构:
Residual Channel Attention Block(RCAB){
--0) Conv2D
--1) Relu
--2) Conv2D
--3) Channel Attention Layer{
----0)Global pooling
----1)Conv2D
----2)Relu
----3)Conv2D
----4)Sigmoid
----5)Element Wise Product (Input of this layer/function would be the output from the Conv2D layer 3)
--}
--4) Element Wise Sum (Input of this layer/function would be the input of layer 1)
}
然而,当我在论文的 GitHub 存储库中打印 PyTorch 模型时,RCAB 看起来像这样:
(完整打印模型请参见 https://github.com/yulunzhang/RCAN/blob/master/RCAN_TrainCode/experiment/model/Network_RCAN_BIX2_G10R20P48-2018-07-15-20-14-55.txt)
(0)RCAB(
(body): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): CALayer(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(conv_du): Sequential(
(0): Conv2d(64, 4, kernel_size=(1, 1), stride=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(4, 64, kernel_size=(1, 1), stride=(1, 1))
(3): Sigmoid()
)
)
)
)
论文中发布的模型的 RCAB 中似乎没有提及 Element Wise sum 和 Element Wise product。 Signmoid 层是每个 RCAB 中的最后一层。
所以我的问题是:Pytorch 是否有一些隐含的方式来声明这些元素明智的 sum/product 层?还是 code/model 的发布者根本没有添加任何此类层,因此没有遵循他们发布的模型架构图?
如果您查看他们的实际模型文件,您可以找到元素总和(仅按 + 实现):https://github.com/yulunzhang/RCAN/blob/master/RCAN_TrainCode/code/model/rcan.py
我相信元素乘积的处理方式相同。在 PyTorch 意义上,这些并不完全是 "part of the model"。它们不是在 __init__ 中创建的,并且是动态的,仅在 forward 传递期间显示其行为。静态模型分析无法揭示它们(因此不会在 txt 中显示)。
我正在尝试通过 Yulun Zhang 等人在 Tensorflow 中实现用于超分辨率的 RCAN(与论文一起发布的原始代码是在 PyTorch 中实现的:https://github.com/yulunzhang/RCAN)。
我想了解他们是如何实施 RCAB 的。通过查看他们发布的网络架构图,神经网络的构建方式似乎非常简单。但是代码好像不匹配
根据此处的图表:https://raw.githubusercontent.com/yulunzhang/RCAN/master/Figs/RCAB.PNG
{kind=link}
每个 RCAB 应具有以下结构:
Residual Channel Attention Block(RCAB){
--0) Conv2D
--1) Relu
--2) Conv2D
--3) Channel Attention Layer{
----0)Global pooling
----1)Conv2D
----2)Relu
----3)Conv2D
----4)Sigmoid
----5)Element Wise Product (Input of this layer/function would be the output from the Conv2D layer 3)
--}
--4) Element Wise Sum (Input of this layer/function would be the input of layer 1)
}
然而,当我在论文的 GitHub 存储库中打印 PyTorch 模型时,RCAB 看起来像这样: (完整打印模型请参见 https://github.com/yulunzhang/RCAN/blob/master/RCAN_TrainCode/experiment/model/Network_RCAN_BIX2_G10R20P48-2018-07-15-20-14-55.txt)
(0)RCAB(
(body): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): CALayer(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(conv_du): Sequential(
(0): Conv2d(64, 4, kernel_size=(1, 1), stride=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(4, 64, kernel_size=(1, 1), stride=(1, 1))
(3): Sigmoid()
)
)
)
)
论文中发布的模型的 RCAB 中似乎没有提及 Element Wise sum 和 Element Wise product。 Signmoid 层是每个 RCAB 中的最后一层。
所以我的问题是:Pytorch 是否有一些隐含的方式来声明这些元素明智的 sum/product 层?还是 code/model 的发布者根本没有添加任何此类层,因此没有遵循他们发布的模型架构图?
如果您查看他们的实际模型文件,您可以找到元素总和(仅按 + 实现):https://github.com/yulunzhang/RCAN/blob/master/RCAN_TrainCode/code/model/rcan.py
我相信元素乘积的处理方式相同。在 PyTorch 意义上,这些并不完全是 "part of the model"。它们不是在 __init__ 中创建的,并且是动态的,仅在 forward 传递期间显示其行为。静态模型分析无法揭示它们(因此不会在 txt 中显示)。