使用 import.io 批量提取时防止 URL 跳过
Prevent URL skipping when Bulk extracting with import.io
所以,我使用 import.io 桌面应用程序提取大量数据已经有一段时间了;但总是困扰我的是,当您尝试批量提取多个 URL 时,它总是会跳过其中的一半。
这不是 URL 的问题,如果你采用相同的假设 15 URLs 它将 return 例如第一次 8,第二次 7,第三次 9;某些链接会在第一次提取但会在第二次被跳过,依此类推。
我想知道有没有办法让它处理所有 URL 我喂它?
我在提取数据时遇到过几次这个问题。这通常是由于批量提取从站点服务器请求 URL 的速度所致。
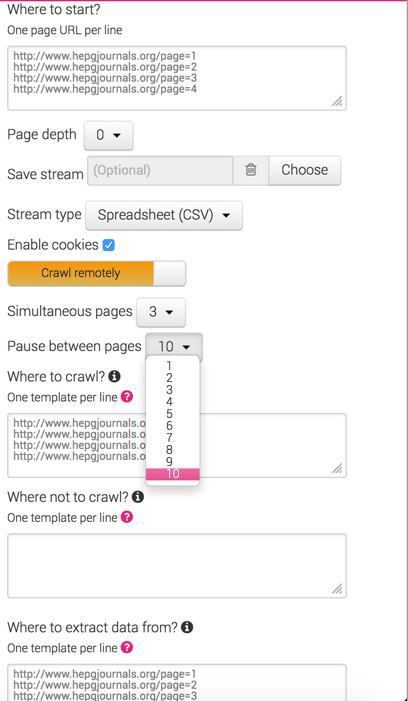
解决方法是像使用提取器一样使用爬网程序。您可以将 created/collected 的 URL 粘贴到“从哪里开始”、“从哪里抓取”和“从哪里获取数据”部分(您需要单击“抓取工具”中的高级设置按钮)。
确保打开 0 深度抓取。 (这将 Crawler 变成了 Extractor;即没有发现额外的 URL)
增加页面之间的停顿。
这是我前段时间制作的截图。
http://i.gyazo.com/92de3b7c7fbca2bc4830c27aefd7cba4.png
所以,我使用 import.io 桌面应用程序提取大量数据已经有一段时间了;但总是困扰我的是,当您尝试批量提取多个 URL 时,它总是会跳过其中的一半。
这不是 URL 的问题,如果你采用相同的假设 15 URLs 它将 return 例如第一次 8,第二次 7,第三次 9;某些链接会在第一次提取但会在第二次被跳过,依此类推。
我想知道有没有办法让它处理所有 URL 我喂它?
我在提取数据时遇到过几次这个问题。这通常是由于批量提取从站点服务器请求 URL 的速度所致。
解决方法是像使用提取器一样使用爬网程序。您可以将 created/collected 的 URL 粘贴到“从哪里开始”、“从哪里抓取”和“从哪里获取数据”部分(您需要单击“抓取工具”中的高级设置按钮)。
确保打开 0 深度抓取。 (这将 Crawler 变成了 Extractor;即没有发现额外的 URL)
增加页面之间的停顿。
这是我前段时间制作的截图。 http://i.gyazo.com/92de3b7c7fbca2bc4830c27aefd7cba4.png
{kind=link}