当 float 数据类型太小时,如何计算 SQL 服务器中的 Erlang C 值?
How can I calculate Erlang C values in SQL Server when the float datatype is too small?
我们正在我们的数据中心实施 Erlang C 计算,但我遇到了障碍:
SQL 服务器的 float 数据类型的溢出错误。
如何在 SQL 服务器中以我仍然可以执行算术的方式表示超过 10^308 的值?
Wikipedia Article: Erlang C
Better explanation of Erlang C calculation
Erlang C 计算回答了以下问题:“给定预测的呼叫量和估计的处理时间,我们应该安排多少座席以确保在指定时间内接听足够多的呼叫者?”
举个例子:我们的服务水平是 75% 的电话必须在 60 秒内接听。下表探讨了与我们的运营相关的各种数量和处理时间的人员配置。
您可以看到,当所需的代理数量超过 140 时,SQL 服务器无法再处理所需数量的大小。
这里的问题是公式中间的求幂和阶乘项。
]2
例如,导致第一个错误的计算有 V=425 和 AHT=600:
(425 calls/30m @ 10m/call -> 141 call hours/hour -> 141 erlangs) A=141
在 n=142
开始评估
- 对于 N=142,A^N 是 3.02002e+305 和 N!是 2.69536e+245。完成计算得出大约 6% 的服务水平,这是不够的。
- 对于 N=143,A^N 是 4.27836e+307 和 N!是 3.85437e+247。完成计算得出大约 24% 的服务水平,这仍然不够。
- 对于 N=144,A^N 是 6.06101e+309 并且 SQL 服务器在我尝试计算它时产生错误,因为
float 类型最多只能处理大约1e308.
编辑:
@chtz 和@dmuir 给出了我需要的提示。
而不是累积 A^i 和 i!分开,我按照建议把它们累积在一起,新版本完美运行。
SELECT
@acc_ai_if = @acc_ai_if * @intensity / cast(@agentcount as float)
-- @acc_if = @acc_if * @agentcount
--, @acc_ai = @acc_ai * @intensity -- this overflows for N>143
;
很抱歉,我对 SQL 服务器一无所知,但这里有一个避免大数的算法,以及一个 C 程序来演示它。
正如 chtz 在他们的评论中指出的那样,关键是要避免计算大幂和大阶乘。
引入一些任意名称,让
a(N) = pow( A, N)/factorial(N)
b(N) = Sum{ 0<=i<N | a(i)}
那么我们可以写出 N>A 的概率为
P = N/(N-A) * a(N) / (b(N) + N/(N-A) * a(N))
请注意,我们有
b(N+1) = b(N) + a(N)
a(N+1) = (A/(N+1))*a(N)
因此我们可以继续基于这些递归编写代码。但是随着 N 的增加,a 和 b 都会变大,所以我认为最好引入另一个函数 as
beta( N) = a(N)/b(N)
然后 beta(1) = A,当 N 增加超过 A 时 beta(N) 减小(至零)。就 beta 而言,我们有
P = N/(N-A) * beta(N) / (1 + N/(N-A) * beta(N))
一点点代数给出了 beta 的递归:
beta(N) = (A/N) * beta(N-1)/(1+beta(N-1))
如上所述
beta(1) = A
这是一个基于这些想法的 C 程序:
#include <stdio.h>
#include <stdlib.h>
// compute beta(toN) from A and previous value of beta
static double beta_step( int A, int toN, double beta)
{
double f = A/(double)toN;
return f*beta/(1.0+beta);
}
int main( void)
{
int A = 140;
int np = 20; // number of probabilities to compute
// compute values for beta at N=1..A
double beta = A;
for( int N=2; N<=A; ++N)
{ beta = beta_step( A, N, beta);
}
// compute probabilities at N=A+1..A+np
for( int i=1; i<=np; ++i)
{
int N = A+i;
beta = beta_step( A, N, beta);
double f = (double)N/(double)i; // == N/(N-A)
double prob = f*beta/(f*beta + 1.0);
printf( "%d\t%f\n", N, prob);
}
return EXIT_SUCCESS;
}
我用
编译了这个(使用相当古老的 gcc (4.8.5))
gcc -o erl -std=gnu99 -Wall erl.c
在SQL 服务器
中为 A=341 和 N=1000 计算 ErlangC
DECLARE @startnum float=1
DECLARE @X float = 1
DECLARE @A float= 341
DECLARE @N float= 1000
;
WITH comp AS (
SELECT @startnum as num,@A as res
UNION ALL
SELECT num+1, res*@A/(num+1) FROM comp WHERE num<@N
)
SELECT res*(@N/(@N-@A))/((SELECT SUM(res) FROM comp where num<@N)+res*(@N/(@N-@A))) FROM comp where num=@N
option (maxrecursion 32000)
我们正在我们的数据中心实施 Erlang C 计算,但我遇到了障碍:
SQL 服务器的 float 数据类型的溢出错误。
如何在 SQL 服务器中以我仍然可以执行算术的方式表示超过 10^308 的值?
Wikipedia Article: Erlang C
Better explanation of Erlang C calculation
Erlang C 计算回答了以下问题:“给定预测的呼叫量和估计的处理时间,我们应该安排多少座席以确保在指定时间内接听足够多的呼叫者?”
举个例子:我们的服务水平是 75% 的电话必须在 60 秒内接听。下表探讨了与我们的运营相关的各种数量和处理时间的人员配置。
您可以看到,当所需的代理数量超过 140 时,SQL 服务器无法再处理所需数量的大小。
这里的问题是公式中间的求幂和阶乘项。
例如,导致第一个错误的计算有 V=425 和 AHT=600:
(425 calls/30m @ 10m/call -> 141 call hours/hour -> 141 erlangs) A=141
在 n=142
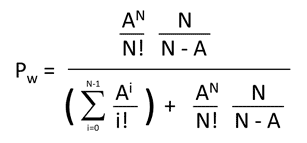{kind=link}
- 对于 N=142,A^N 是 3.02002e+305 和 N!是 2.69536e+245。完成计算得出大约 6% 的服务水平,这是不够的。
- 对于 N=143,A^N 是 4.27836e+307 和 N!是 3.85437e+247。完成计算得出大约 24% 的服务水平,这仍然不够。
- 对于 N=144,A^N 是 6.06101e+309 并且 SQL 服务器在我尝试计算它时产生错误,因为
float类型最多只能处理大约1e308.
编辑:
@chtz 和@dmuir 给出了我需要的提示。
而不是累积 A^i 和 i!分开,我按照建议把它们累积在一起,新版本完美运行。
SELECT
@acc_ai_if = @acc_ai_if * @intensity / cast(@agentcount as float)
-- @acc_if = @acc_if * @agentcount
--, @acc_ai = @acc_ai * @intensity -- this overflows for N>143
;
很抱歉,我对 SQL 服务器一无所知,但这里有一个避免大数的算法,以及一个 C 程序来演示它。
正如 chtz 在他们的评论中指出的那样,关键是要避免计算大幂和大阶乘。 引入一些任意名称,让
a(N) = pow( A, N)/factorial(N)
b(N) = Sum{ 0<=i<N | a(i)}
那么我们可以写出 N>A 的概率为
P = N/(N-A) * a(N) / (b(N) + N/(N-A) * a(N))
请注意,我们有
b(N+1) = b(N) + a(N)
a(N+1) = (A/(N+1))*a(N)
因此我们可以继续基于这些递归编写代码。但是随着 N 的增加,a 和 b 都会变大,所以我认为最好引入另一个函数 as
beta( N) = a(N)/b(N)
然后 beta(1) = A,当 N 增加超过 A 时 beta(N) 减小(至零)。就 beta 而言,我们有
P = N/(N-A) * beta(N) / (1 + N/(N-A) * beta(N))
一点点代数给出了 beta 的递归:
beta(N) = (A/N) * beta(N-1)/(1+beta(N-1))
如上所述
beta(1) = A
这是一个基于这些想法的 C 程序:
#include <stdio.h>
#include <stdlib.h>
// compute beta(toN) from A and previous value of beta
static double beta_step( int A, int toN, double beta)
{
double f = A/(double)toN;
return f*beta/(1.0+beta);
}
int main( void)
{
int A = 140;
int np = 20; // number of probabilities to compute
// compute values for beta at N=1..A
double beta = A;
for( int N=2; N<=A; ++N)
{ beta = beta_step( A, N, beta);
}
// compute probabilities at N=A+1..A+np
for( int i=1; i<=np; ++i)
{
int N = A+i;
beta = beta_step( A, N, beta);
double f = (double)N/(double)i; // == N/(N-A)
double prob = f*beta/(f*beta + 1.0);
printf( "%d\t%f\n", N, prob);
}
return EXIT_SUCCESS;
}
我用
编译了这个(使用相当古老的 gcc (4.8.5))gcc -o erl -std=gnu99 -Wall erl.c
在SQL 服务器
中为 A=341 和 N=1000 计算 ErlangCDECLARE @startnum float=1
DECLARE @X float = 1
DECLARE @A float= 341
DECLARE @N float= 1000
;
WITH comp AS (
SELECT @startnum as num,@A as res
UNION ALL
SELECT num+1, res*@A/(num+1) FROM comp WHERE num<@N
)
SELECT res*(@N/(@N-@A))/((SELECT SUM(res) FROM comp where num<@N)+res*(@N/(@N-@A))) FROM comp where num=@N
option (maxrecursion 32000)