如何将 excel 工作表读入 R 中的一个数据帧并跳过某些行
How to read in excel sheets into one data frame in R and skip certain lines
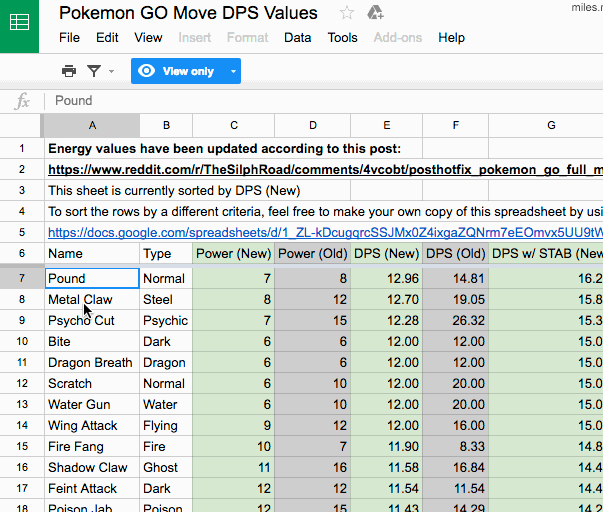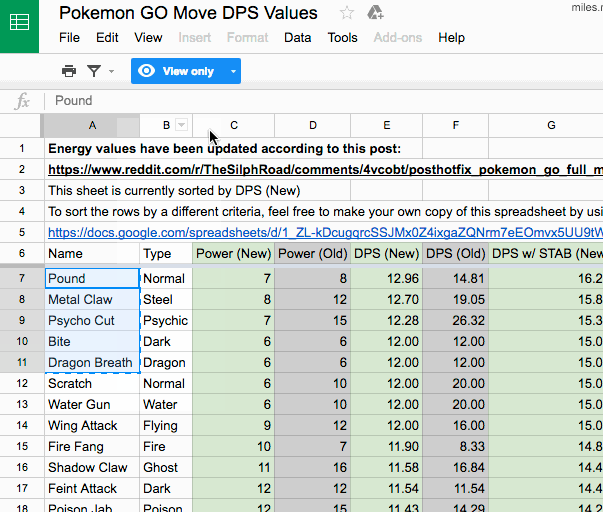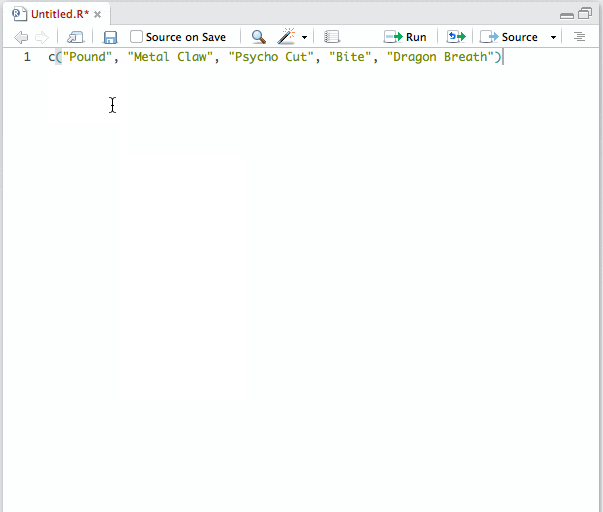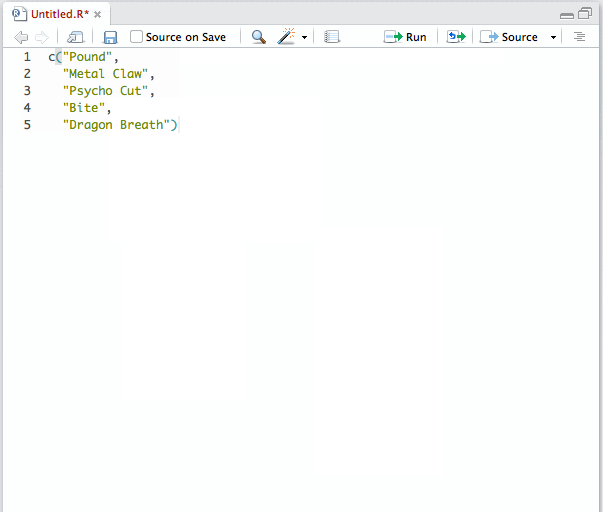
我正在尝试使用 R 读取包含多个 sheet 的 excel 文件,并将它们全部合并到一个数据框中,将 sheet 名称标记为数据框。
然后这次我遇到一个问题,excel sheet 包含 1 行多余的标题,所以我想跳过第 1 行。
在lapply中使用read_excel,自然而然的想到直接加上skip=1比如
mylist <-lapply(excel_sheets(path), read_excel(skip=1)
然后 R 抱怨路径,如果我继续添加路径,它会抱怨 read_excel 不是函数。所以我认为可以使用 function(x){}
编写
这完全搞砸了。生成的列表有一个细微的错误,我只是在绘制数据时才发现:它多次复制并粘贴相同的 sheet 1 并在重复的数据上添加正确的 sheet 名称。
当然我可以手动删除第 1 行,但我想知道我在哪里出错以及如何修复它。
library(readxl)
#read in excel sheets
#but now I need to skip one line
path <- "/Users/xxx/file.xlsx"
sheetnames <- excel_sheets(path)
mylist <- lapply(excel_sheets(path), function(x){read_excel(path= path,col_names = TRUE,skip = 1)})
# name the dataframes
names(mylist) <- sheetnames
#use Map to bind all the elements of the list into a dataframe
my_list <- Map(cbind, mylist, Cluster = names(mylist))
df <- do.call("rbind", my_list)
在 read_excel 函数中,您没有传递要读取的 sheet,它存在于 sheetnames 变量中。尝试以下操作:
library(readxl)
path <- "/Users/xxx/file.xlsx"
sheetnames <- excel_sheets(path)
mylist <- lapply(sheetnames, function(x)
read_excel(path,x, col_names = TRUE,skip = 1))
#col_names is TRUE by default so you can use this without anonymous function like
#mylist <- lapply(sheetnames, read_excel, path = path, skip = 1)
# name the dataframes
names(mylist) <- sheetnames
#use Map to bind all the elements of the list into a dataframe
my_list <- Map(cbind, mylist, Cluster = names(mylist))
df <- do.call("rbind", my_list)
试试 datapasta 包。它粘贴你select.
我正在尝试使用 R 读取包含多个 sheet 的 excel 文件,并将它们全部合并到一个数据框中,将 sheet 名称标记为数据框。
然后这次我遇到一个问题,excel sheet 包含 1 行多余的标题,所以我想跳过第 1 行。
在lapply中使用read_excel,自然而然的想到直接加上skip=1比如
mylist <-lapply(excel_sheets(path), read_excel(skip=1)
然后 R 抱怨路径,如果我继续添加路径,它会抱怨 read_excel 不是函数。所以我认为可以使用 function(x){}
编写这完全搞砸了。生成的列表有一个细微的错误,我只是在绘制数据时才发现:它多次复制并粘贴相同的 sheet 1 并在重复的数据上添加正确的 sheet 名称。
当然我可以手动删除第 1 行,但我想知道我在哪里出错以及如何修复它。
library(readxl)
#read in excel sheets
#but now I need to skip one line
path <- "/Users/xxx/file.xlsx"
sheetnames <- excel_sheets(path)
mylist <- lapply(excel_sheets(path), function(x){read_excel(path= path,col_names = TRUE,skip = 1)})
# name the dataframes
names(mylist) <- sheetnames
#use Map to bind all the elements of the list into a dataframe
my_list <- Map(cbind, mylist, Cluster = names(mylist))
df <- do.call("rbind", my_list)
在 read_excel 函数中,您没有传递要读取的 sheet,它存在于 sheetnames 变量中。尝试以下操作:
library(readxl)
path <- "/Users/xxx/file.xlsx"
sheetnames <- excel_sheets(path)
mylist <- lapply(sheetnames, function(x)
read_excel(path,x, col_names = TRUE,skip = 1))
#col_names is TRUE by default so you can use this without anonymous function like
#mylist <- lapply(sheetnames, read_excel, path = path, skip = 1)
# name the dataframes
names(mylist) <- sheetnames
#use Map to bind all the elements of the list into a dataframe
my_list <- Map(cbind, mylist, Cluster = names(mylist))
df <- do.call("rbind", my_list)
试试 datapasta 包。它粘贴你select.
{kind=link}