Linux 上的堆栈大小 - 有限堆栈大小与自动堆栈扩展
Stack size on Linux - Limited stack size vs automatic stack expansion
- 我记得我十几岁的时候第一次从书上学习内存处理,下面的例子:
void foo()
{
int a[1000000]; // waste of stack
// ...
}
对
void foo()
{
int* ptr = malloc(1000000 * sizeof(int)); // much better, because the size of stack is limited
// ...
}
(是的,我听说有时编译器可能会将第二个代码优化为第一个代码)
我一直把堆栈想象成一个“固定的、有限的”内存space,我的旧书上说“堆栈很小,不要浪费它”,但是堆可以根据需要利用 RAM(限制来自明显的硬件)。
但是:
https://unix.stackexchange.com/questions/63742/what-is-automatic-stack-expansion
https://www.youtube.com/watch?v=7aONIVSXiJ8 47:05
所以如果我理解得很好,堆栈大小不是我们选择堆的主要原因吗?
好吧,我们仍然需要 malloc()/calloc() 因为我们不知道数组大小的编译时间(并且想避免 VLA)。但是除了这个原因,我们把数据实例存储在堆上还有什么其他原因吗?
我一直想象堆会随着我们 malloc() 的增加而扩展。这是正确的吗?
- 我很困惑如果堆栈是动态增长的,那么为什么会发生堆栈溢出?
这是一张关于 Linux 程序在虚拟内存中的图片:
https://cdn-images-1.medium.com/max/1200/1*8b9-Z3FV6X9SP9We8gSC3Q.jpeg
当两个箭头之间的虚拟内存space耗尽时发生堆栈溢出?
youtube 视频 (https://www.youtube.com/watch?v=7aONIVSXiJ8) 在 47:40 处说堆栈扩展可能会导致新分配的页面与堆栈的其余部分在物理上不连续。新分配的页面将映射到进程的堆栈中,因此程序的虚拟内存布局保持平坦。我这个正确吗?
堆向上增长(例如 malloc() 时)。但是,这再次得出结论,堆的大小是有限的(在堆栈上方,在 BSS 底部)。如何通过堆来利用整个 RAM?如果低地址为 0,而高地址是 RAM 可用的最高内存地址,我唯一可以想象的原因。一个进程可能“看到整个 RAM 都可用指针”。这些是虚拟内存地址,因此 CPU 将它们转换为物理地址。我理解的好吗?
由于堆栈和堆都随着我们分配的更多而动态增长,我们不必关心用 brk() 手动增加程序中断或在堆栈上分配alloca() 函数。这些是内核调用的低级函数,我们不会直接调用这些函数。这是正确的吗?
如果我理解正确,请您回答我将不胜感激。
堆栈可以增长,但不是无限增长。正如您 link 的第一个问题中的图表所示,堆栈和堆都可以增长到空闲内存区域,但如果它们继续增长,最终它们将 运行 相互融合。
编写需要大量堆栈增长的程序并不常见。通常,如果程序不断增加堆栈,则表明存在导致无限递归的错误。限制堆栈大小会捕获这些错误。虽然有一些深度递归的算法,但它们并不常见,并且通常可以重构为迭代算法。
问题在于
int a[1000000];
是不是它“浪费”了堆栈。大多数架构对单个堆栈帧的大小都有相对较小的限制,因此您不能拥有像局部变量这样大的数组。
但除此之外,选择堆内存还是栈内存的通常原因与数据的使用方式有关。堆栈上的变量在程序代码中静态声明。如果您需要可变数量的对象,通常需要使用堆(C 有可变长度数组,但 C++ 没有,并且您不能像使用 realloc() 那样调整它们的大小)。此外,当函数 returns 时,堆栈上分配的内存消失,因此您必须使用堆对象来存储超出单个函数的数据。
不用担心他在 47:40 视频中说的是什么。应用程序只与虚拟内存打交道,物理内存是完全隐藏的,只与内核中的虚拟内存子系统内部有关。
进程中断由 运行时间库的 malloc() 实现使用。您通常不会直接在应用程序中处理它。
- 我记得我十几岁的时候第一次从书上学习内存处理,下面的例子:
void foo()
{
int a[1000000]; // waste of stack
// ...
}
对
void foo()
{
int* ptr = malloc(1000000 * sizeof(int)); // much better, because the size of stack is limited
// ...
}
(是的,我听说有时编译器可能会将第二个代码优化为第一个代码)
我一直把堆栈想象成一个“固定的、有限的”内存space,我的旧书上说“堆栈很小,不要浪费它”,但是堆可以根据需要利用 RAM(限制来自明显的硬件)。
但是:
https://unix.stackexchange.com/questions/63742/what-is-automatic-stack-expansion
https://www.youtube.com/watch?v=7aONIVSXiJ8 47:05
所以如果我理解得很好,堆栈大小不是我们选择堆的主要原因吗?
好吧,我们仍然需要 malloc()/calloc() 因为我们不知道数组大小的编译时间(并且想避免 VLA)。但是除了这个原因,我们把数据实例存储在堆上还有什么其他原因吗?
我一直想象堆会随着我们 malloc() 的增加而扩展。这是正确的吗?
- 我很困惑如果堆栈是动态增长的,那么为什么会发生堆栈溢出?
这是一张关于 Linux 程序在虚拟内存中的图片:
https://cdn-images-1.medium.com/max/1200/1*8b9-Z3FV6X9SP9We8gSC3Q.jpeg
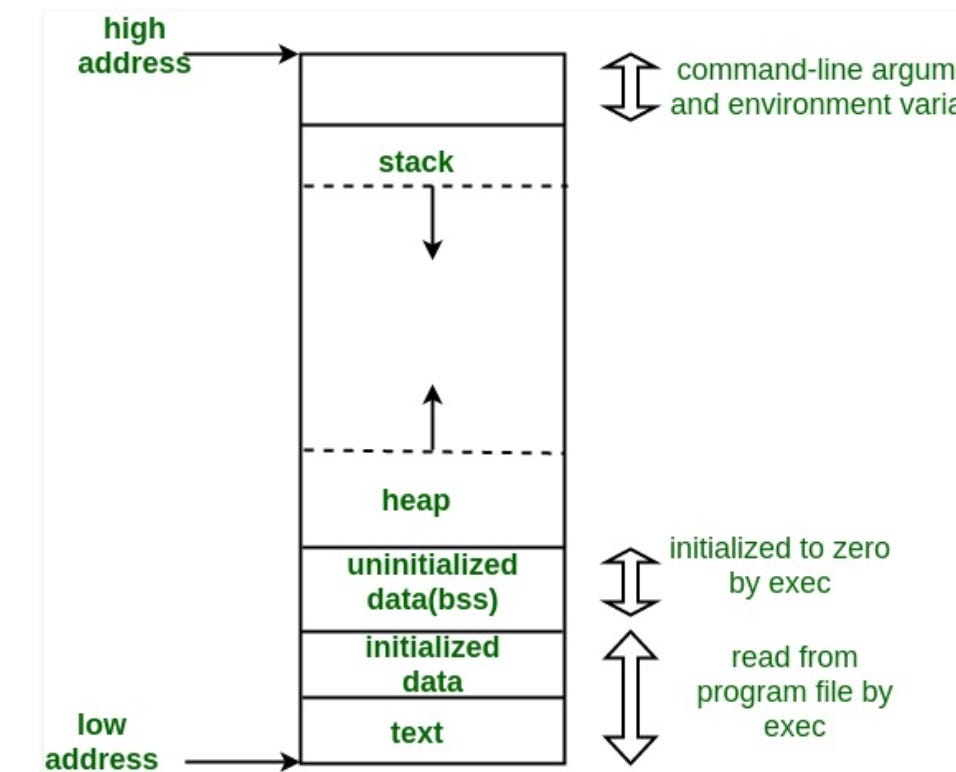{kind=link}
当两个箭头之间的虚拟内存space耗尽时发生堆栈溢出?
youtube 视频 (https://www.youtube.com/watch?v=7aONIVSXiJ8) 在 47:40 处说堆栈扩展可能会导致新分配的页面与堆栈的其余部分在物理上不连续。新分配的页面将映射到进程的堆栈中,因此程序的虚拟内存布局保持平坦。我这个正确吗?
堆向上增长(例如
malloc()时)。但是,这再次得出结论,堆的大小是有限的(在堆栈上方,在 BSS 底部)。如何通过堆来利用整个 RAM?如果低地址为 0,而高地址是 RAM 可用的最高内存地址,我唯一可以想象的原因。一个进程可能“看到整个 RAM 都可用指针”。这些是虚拟内存地址,因此 CPU 将它们转换为物理地址。我理解的好吗?由于堆栈和堆都随着我们分配的更多而动态增长,我们不必关心用
brk()手动增加程序中断或在堆栈上分配alloca()函数。这些是内核调用的低级函数,我们不会直接调用这些函数。这是正确的吗?
如果我理解正确,请您回答我将不胜感激。
堆栈可以增长,但不是无限增长。正如您 link 的第一个问题中的图表所示,堆栈和堆都可以增长到空闲内存区域,但如果它们继续增长,最终它们将 运行 相互融合。
编写需要大量堆栈增长的程序并不常见。通常,如果程序不断增加堆栈,则表明存在导致无限递归的错误。限制堆栈大小会捕获这些错误。虽然有一些深度递归的算法,但它们并不常见,并且通常可以重构为迭代算法。
问题在于
int a[1000000];
是不是它“浪费”了堆栈。大多数架构对单个堆栈帧的大小都有相对较小的限制,因此您不能拥有像局部变量这样大的数组。
但除此之外,选择堆内存还是栈内存的通常原因与数据的使用方式有关。堆栈上的变量在程序代码中静态声明。如果您需要可变数量的对象,通常需要使用堆(C 有可变长度数组,但 C++ 没有,并且您不能像使用 realloc() 那样调整它们的大小)。此外,当函数 returns 时,堆栈上分配的内存消失,因此您必须使用堆对象来存储超出单个函数的数据。
不用担心他在 47:40 视频中说的是什么。应用程序只与虚拟内存打交道,物理内存是完全隐藏的,只与内核中的虚拟内存子系统内部有关。
进程中断由 运行时间库的 malloc() 实现使用。您通常不会直接在应用程序中处理它。