Cox 回归 HR 分组
Cox regression HR grouping
我想对以下问题进行 Cox 回归:一组患者是否接受“药物”治疗 (0 / 1)。我的时间变量“时间”告诉我观察患者的天数以及患者存活或死亡的“状态”(死亡 = 1,存活 = 0)。
library(survival)
set.seed(123)
df <- data.frame(time = round(runif(100, min = 1, max = 70)),
status = round(runif(100, min = 0, max = 1)),
drug = round(runif(100, min = 0, max = 1)),
age40 = round(runif(100, min = 0, max = 1)),
stringsAsFactors = FALSE)
object <- Surv(df$time, df$status)
model <- coxph(object ~ drug, data = df)
summary(model)
这对我来说效果很好,告诉我 HR 是 0.89,所以药物可以防止患者死亡。
现在我想做一些亚组分析,f.e。如果患者 <= 40 岁或 > 40 岁(40 岁:0 对 1),HR 如何变化。
我需要做的就是将变量“age40”包含到 coxph 中吗?
object2 <- Surv(df$time, df$status)
model2 <- coxph(object2 ~ drug + age40, data = df)
summary(model2)
如果我这样做,我在 drug1 摘要中的 HR 会略微变为 0.86,我会得到另一个 age40 (1.12)。
现在我的问题是:如果患者 <= 40 岁或 > 40 岁,在接受治疗(药物 = 1)时死亡的风险比如何。
编辑:另一个问题是在森林图中以图形方式显示药物对状态影响的不同 HRs、f.e。像这样:https://rpkgs.datanovia.com/survminer/reference/ggforest-2.png。
我想显示 Age40 = 0 vs. 1 和其他变量的 HR,而不是“性”、“rx”、“坚持”等,例如高血压 = 0 vs. 1,吸烟者 = 0 vs. 1。
谢谢!
使用参数 strata.
coxph(object ~ drug + strata(age40), data = df)
您需要使用的函数是 model2 上的 predict,并且需要为其提供一个新数据参数,其中包含您要考虑的所有情况:
exp( predict(model2, newdata=expand.grid(drug=c(0,1), age40=c(0,1))) )
# 1 2 3 4
#1.0000000 0.8564951 1.1268713 0.9651598
您现在已经掌握了所有 4 种药物和年龄 40 可能组合的情况。基本案例具有统一值,因为您正在从 {drug=0, age40=0} 的基线案例中估算风险比率您可以看到其他风险比率与什么相关
expand.grid(drug=c(0,1), age40=c(0,1))
drug age40
1 0 0
2 1 0
3 0 1
4 1 1
请注意,drug=0 与 drug=1 的比例对于单独考虑的每个年龄类别都是相同的。如果您想查看药物对两个年龄组的影响是否不同,您会使用交互模型:
model3 <- coxph(object2 ~ drug * age40, data = df)
summary(model3)
#----------------
Call:
coxph(formula = object2 ~ drug * age40, data = df)
n= 100, number of events= 50
coef exp(coef) se(coef) z Pr(>|z|)
drug -0.18524 0.83091 0.45415 -0.408 0.683
age40 0.09611 1.10089 0.39560 0.243 0.808
drug:age40 0.05679 1.05843 0.63094 0.090 0.928
exp(coef) exp(-coef) lower .95 upper .95
drug 0.8309 1.2035 0.3412 2.024
age40 1.1009 0.9084 0.5070 2.390
drug:age40 1.0584 0.9448 0.3073 3.645
Concordance= 0.528 (se = 0.042 )
Likelihood ratio test= 0.34 on 3 df, p=1
Wald test = 0.33 on 3 df, p=1
Score (logrank) test = 0.33 on 3 df, p=1
现在效果估计有点不同:
exp( predict(model3, newdata=expand.grid(drug=c(0,1), age40=c(0,1))) )
# 1 2 3 4
#1.0000000 0.8309089 1.1008850 0.9681861
我想对以下问题进行 Cox 回归:一组患者是否接受“药物”治疗 (0 / 1)。我的时间变量“时间”告诉我观察患者的天数以及患者存活或死亡的“状态”(死亡 = 1,存活 = 0)。
library(survival)
set.seed(123)
df <- data.frame(time = round(runif(100, min = 1, max = 70)),
status = round(runif(100, min = 0, max = 1)),
drug = round(runif(100, min = 0, max = 1)),
age40 = round(runif(100, min = 0, max = 1)),
stringsAsFactors = FALSE)
object <- Surv(df$time, df$status)
model <- coxph(object ~ drug, data = df)
summary(model)
这对我来说效果很好,告诉我 HR 是 0.89,所以药物可以防止患者死亡。
现在我想做一些亚组分析,f.e。如果患者 <= 40 岁或 > 40 岁(40 岁:0 对 1),HR 如何变化。
我需要做的就是将变量“age40”包含到 coxph 中吗?
object2 <- Surv(df$time, df$status)
model2 <- coxph(object2 ~ drug + age40, data = df)
summary(model2)
如果我这样做,我在 drug1 摘要中的 HR 会略微变为 0.86,我会得到另一个 age40 (1.12)。
现在我的问题是:如果患者 <= 40 岁或 > 40 岁,在接受治疗(药物 = 1)时死亡的风险比如何。
编辑:另一个问题是在森林图中以图形方式显示药物对状态影响的不同 HRs、f.e。像这样:https://rpkgs.datanovia.com/survminer/reference/ggforest-2.png。 我想显示 Age40 = 0 vs. 1 和其他变量的 HR,而不是“性”、“rx”、“坚持”等,例如高血压 = 0 vs. 1,吸烟者 = 0 vs. 1。
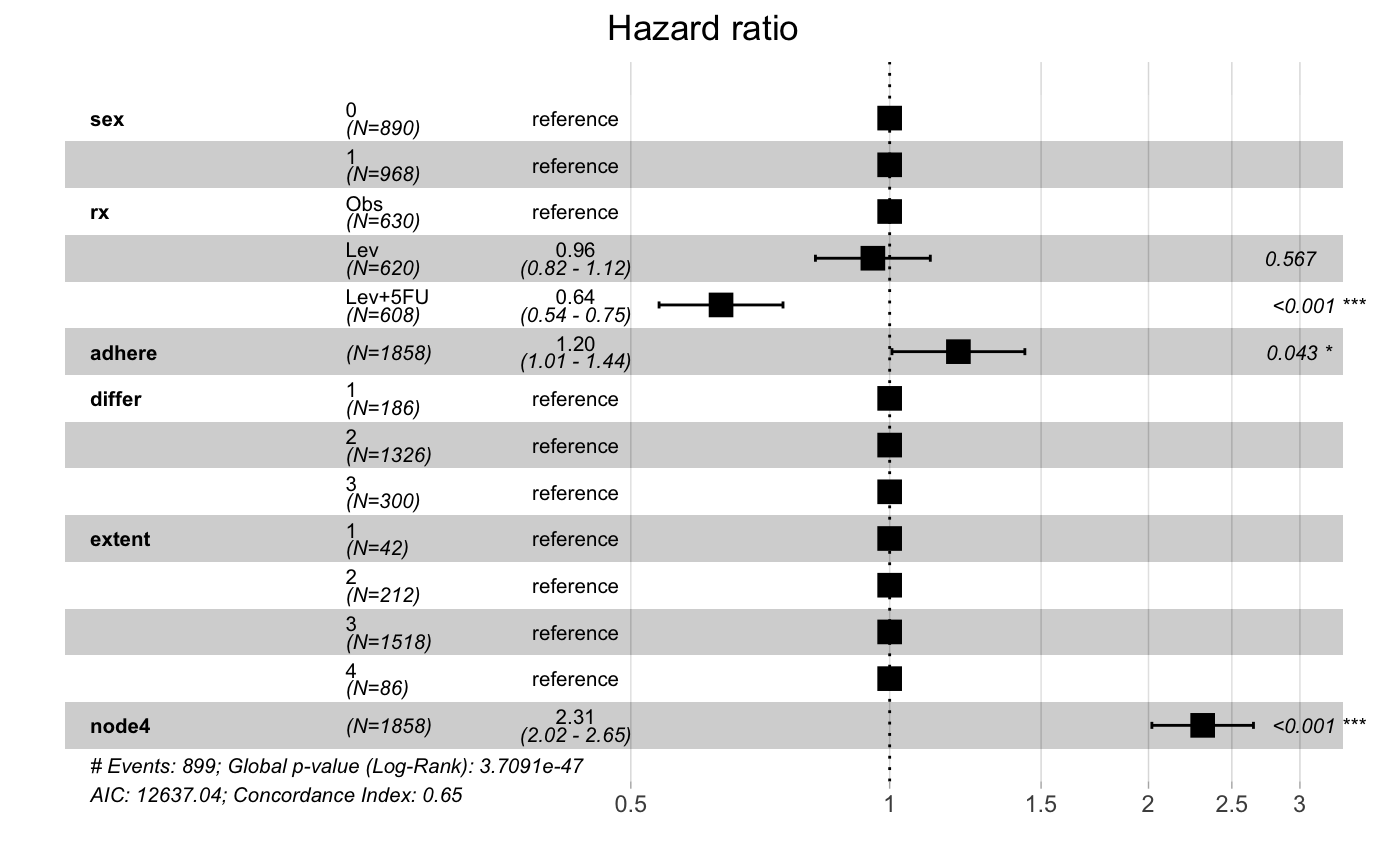{kind=link}
谢谢!
使用参数 strata.
coxph(object ~ drug + strata(age40), data = df)
您需要使用的函数是 model2 上的 predict,并且需要为其提供一个新数据参数,其中包含您要考虑的所有情况:
exp( predict(model2, newdata=expand.grid(drug=c(0,1), age40=c(0,1))) )
# 1 2 3 4
#1.0000000 0.8564951 1.1268713 0.9651598
您现在已经掌握了所有 4 种药物和年龄 40 可能组合的情况。基本案例具有统一值,因为您正在从 {drug=0, age40=0} 的基线案例中估算风险比率您可以看到其他风险比率与什么相关
expand.grid(drug=c(0,1), age40=c(0,1))
drug age40
1 0 0
2 1 0
3 0 1
4 1 1
请注意,drug=0 与 drug=1 的比例对于单独考虑的每个年龄类别都是相同的。如果您想查看药物对两个年龄组的影响是否不同,您会使用交互模型:
model3 <- coxph(object2 ~ drug * age40, data = df)
summary(model3)
#----------------
Call:
coxph(formula = object2 ~ drug * age40, data = df)
n= 100, number of events= 50
coef exp(coef) se(coef) z Pr(>|z|)
drug -0.18524 0.83091 0.45415 -0.408 0.683
age40 0.09611 1.10089 0.39560 0.243 0.808
drug:age40 0.05679 1.05843 0.63094 0.090 0.928
exp(coef) exp(-coef) lower .95 upper .95
drug 0.8309 1.2035 0.3412 2.024
age40 1.1009 0.9084 0.5070 2.390
drug:age40 1.0584 0.9448 0.3073 3.645
Concordance= 0.528 (se = 0.042 )
Likelihood ratio test= 0.34 on 3 df, p=1
Wald test = 0.33 on 3 df, p=1
Score (logrank) test = 0.33 on 3 df, p=1
现在效果估计有点不同:
exp( predict(model3, newdata=expand.grid(drug=c(0,1), age40=c(0,1))) )
# 1 2 3 4
#1.0000000 0.8309089 1.1008850 0.9681861