为什么更新`Binary log`有两种方法。(1. Master Binlog dump 2. Master Database)
Why there have two ways to update `Binary log`.(1. Master Binlog dump 2. Master Database)
我在 google image 中看到了快照:
我有一个问题,为什么有两种更新方式Binary log:
- 掌握Binlog转储
- 主数据库。
如果没有Binlog dump来更新Binary log,Master Database更新后也可以更新Binlog。
我猜这样可以增加Relay log read content advanced。
但是为什么主库要重新更新Binlog呢?要确认吗?
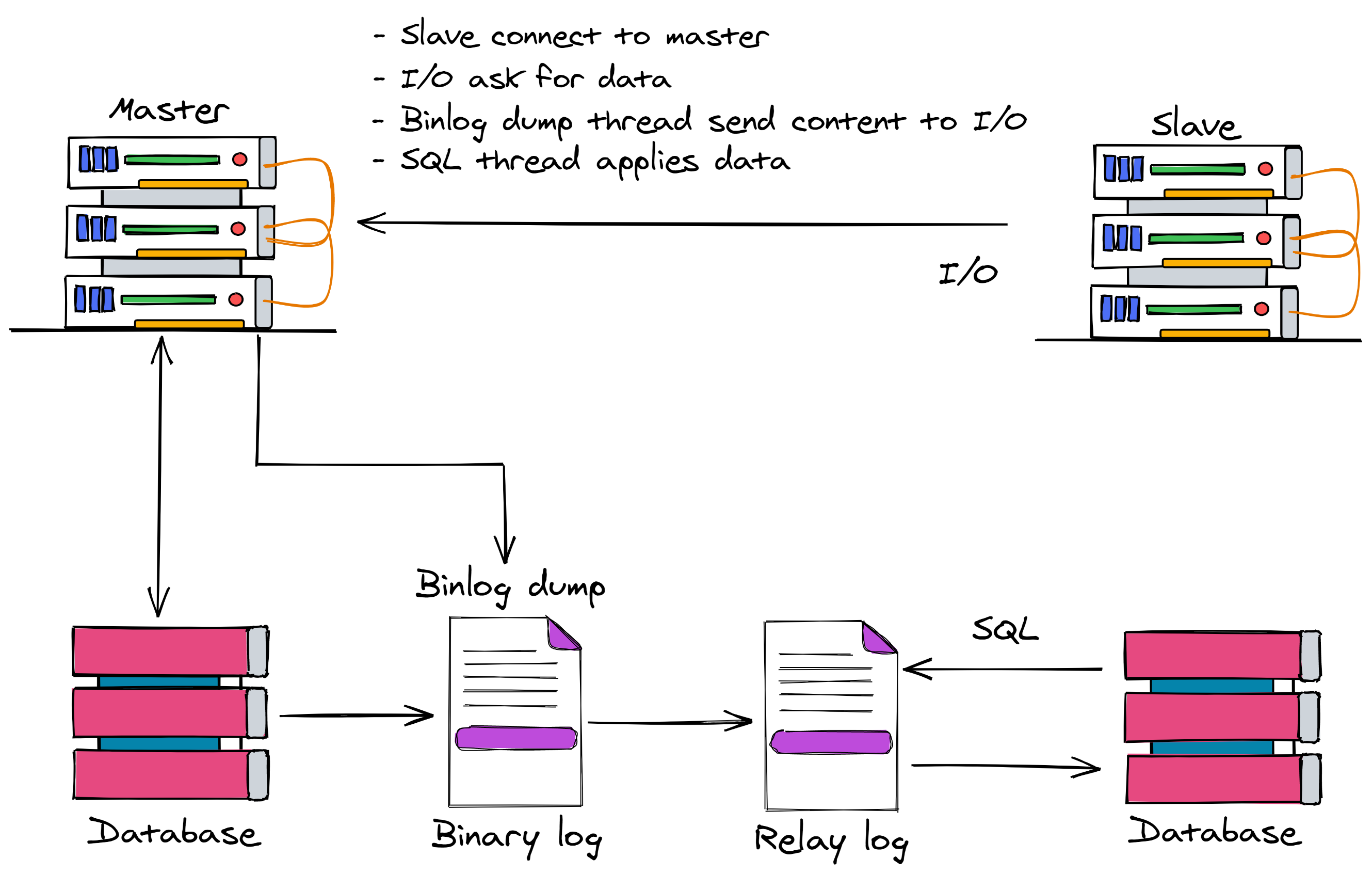
图表令人困惑。只有一件事正在发生,它只是用两种方式描述的。这是正在发生的事情。 (根据 current MySQL documentation,我更喜欢使用术语“来源”和“副本”。)
- 源实例对其数据库执行事务。
- 源实例将事务的事件写入其二进制日志。
- 副本实例的 IO 线程连接到源实例。
- 副本的 IO 线程运行管理命令
binlog dump。这会等待源实例将事件写入其二进制日志,并在事件发生后立即下载它们。
- 副本的 IO 线程将其下载的事件写入副本实例上的中继日志。
- 副本的 SQL 线程等待事件写入中继日志。
- 副本的 SQL 线程从中继日志中读取,并针对副本的数据库执行它们。
我在 google image 中看到了快照:
{kind=link}
我有一个问题,为什么有两种更新方式Binary log:
- 掌握Binlog转储
- 主数据库。
如果没有Binlog dump来更新Binary log,Master Database更新后也可以更新Binlog。
我猜这样可以增加Relay log read content advanced。 但是为什么主库要重新更新Binlog呢?要确认吗?
图表令人困惑。只有一件事正在发生,它只是用两种方式描述的。这是正在发生的事情。 (根据 current MySQL documentation,我更喜欢使用术语“来源”和“副本”。)
- 源实例对其数据库执行事务。
- 源实例将事务的事件写入其二进制日志。
- 副本实例的 IO 线程连接到源实例。
- 副本的 IO 线程运行管理命令
binlog dump。这会等待源实例将事件写入其二进制日志,并在事件发生后立即下载它们。 - 副本的 IO 线程将其下载的事件写入副本实例上的中继日志。
- 副本的 SQL 线程等待事件写入中继日志。
- 副本的 SQL 线程从中继日志中读取,并针对副本的数据库执行它们。