在财务报表文本文件中找到正确的单词和行
Finding the right word and row in the Financial Statement text file
我在 Python 中使用 tesseract OCR 将财务报表 pdf 转换为文本文件,同时将长空格转换为“;”。所以文本文件看起来很不错,tables 看起来也不错。
使用此处找到的示例 https://cdn.corporatefinanceinstitute.com/assets/AMZN-Cash-Flow.png
The table would be like the following:
Stock-based compensation;2,119;2,975;4,215
Other operating expense, net;155;160;202
Other expense (income), net;250;(20);(292)
Deferred income taxes;81;(246);(29)
...
好的,所以任务是找到例如 “基于股票的补偿” -> 2,119 之后的第一个总和。我至少遇到过 3 个问题:
第一个问题是我总是以完整的财务报表 pdf 开头,其中包含例如 20 页,并且可以多次包含单词 “基于股票的补偿”在诸如“..是授予基于股票的补偿的日期...”这样的句子中。
第二个问题是在财务报表中找到正确的table。可以有各种较小的 tables 可以发生“基于股票的补偿”。但是,在这种情况下,假设我们正在寻找 table 称为“合并现金流量表”,而不是例如“下一财政年度的估计预算”等
第三题是单词本身。 “Stock-based compensation”可以有不同的形式,例如“Stock based compensation”、“Compensation”、“Stock based compensation & other compensation”等。但是,正如我们现在所说的这种“Stock-based compensation”以一种或另一种形式无论如何应该在右边table,找到正确的线应该不是主要问题。
例如,我使用正则表达式来缩小我正在寻找的正确单词的选项范围
def find_sum(word_to_look_for):
txt_file = r"fina.txt"
find = pattern
digitals = "\d+|;" #trying to find if any digits or ";" can be found on the row
with open(txt_file, "r") as in_text:
for row in in_text:
if re.findall(find, row, flags=re.IGNORECASE):
if re.findall(digitals, row):
expense_row = row.split(";")[1].strip("-")
expenses = re.sub("[^\d\,]", "", expense_row) #if e.g 2.512,00
return expenses
else:
pass
这解决了一些问题,但我目前正在考虑是否应该在这种情况下实施 ML 或 NLP 技术,或者这是否足够容易用正则表达式解决,只需使用 n-amount 缩小可能的行数if 语句?
使用带有空白字符的词来查找,可以在函数中使用 .* 连接符创建正则表达式以允许匹配这些词之间的任何内容。
def find_sum(word_to_look_for):
txt_file = r"fina.txt"
find = ".*".join([re.escape(w) for w in word_to_look_for.split()]) + r"\D*(\d+(?:[,.]\d+)*)"
with open(txt_file, "r") as in_text:
for row in in_text:
match = re.search(find, row, flags=re.IGNORECASE)
if match:
return match.group(1)
return ""
import re
def find_sum(word_to_look_for):
txt_file = r"fina.txt"
find = ".*".join([re.escape(w) for w in word_to_look_for.split()]) + r"\D*(\d+(?:[,.]\d+)*)"
in_text = ['...', 'XXX', 'Stock-based compensation;2,234.55']
#with open(txt_file, "r") as in_text:
for row in in_text:
match = re.search(find, row, flags=re.IGNORECASE)
if match:
return match.group(1)
return ""
wtlf = "Stock based compensation"
print(find_sum(wtlf))
结果:2,234.55
正则表达式:
Stock.*based.*compensation\D*(\d+(?:[,.]\d+)*)
解释
--------------------------------------------------------------------------------
Stock 'Stock'
--------------------------------------------------------------------------------
.* any character except \n (0 or more times
(matching the most amount possible))
--------------------------------------------------------------------------------
based 'based'
--------------------------------------------------------------------------------
.* any character except \n (0 or more times
(matching the most amount possible))
--------------------------------------------------------------------------------
compensation 'compensation'
--------------------------------------------------------------------------------
\D* non-digits (all but 0-9) (0 or more times
(matching the most amount possible))
--------------------------------------------------------------------------------
( group and capture to :
--------------------------------------------------------------------------------
\d+ digits (0-9) (1 or more times (matching
the most amount possible))
--------------------------------------------------------------------------------
(?: group, but do not capture (0 or more
times (matching the most amount
possible)):
--------------------------------------------------------------------------------
[,.] any character of: ',', '.'
--------------------------------------------------------------------------------
\d+ digits (0-9) (1 or more times
(matching the most amount possible))
--------------------------------------------------------------------------------
)* end of grouping
--------------------------------------------------------------------------------
) end of
感谢您的回答,这个
find = ".*".join([re.escape(w) for w in word_to_look_for.split()]) + r"\D*(\d+(?:[,.]\d+)*)"
效果很好。
但是,我仍然遇到一个问题,因为在我的 FinaStatements 中有两个几乎相同的 tables,一个用于预算,一个用于显示去年的数字。这两个 table 都在页面顶部标有清晰的标题。
有了上面的这个答案,我得到了这两个匹配项,因为该行本身看起来很相似,但我只想要另一个匹配项。
我在 OCR 过程中添加了一个文本指示每个页面的开始,然后寻找正确的页面,包括正确的 table,但似乎比想象的要难。有什么想法吗?
我在 Python 中使用 tesseract OCR 将财务报表 pdf 转换为文本文件,同时将长空格转换为“;”。所以文本文件看起来很不错,tables 看起来也不错。
使用此处找到的示例 https://cdn.corporatefinanceinstitute.com/assets/AMZN-Cash-Flow.png
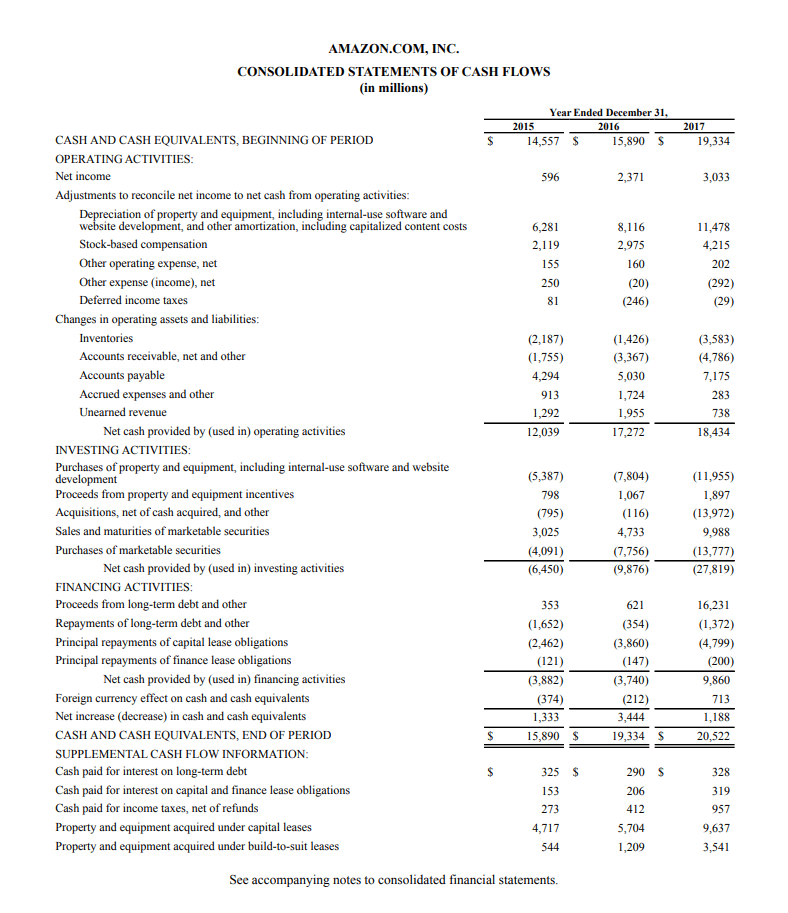{kind=link}
The table would be like the following:
Stock-based compensation;2,119;2,975;4,215
Other operating expense, net;155;160;202
Other expense (income), net;250;(20);(292)
Deferred income taxes;81;(246);(29)
...
好的,所以任务是找到例如 “基于股票的补偿” -> 2,119 之后的第一个总和。我至少遇到过 3 个问题:
第一个问题是我总是以完整的财务报表 pdf 开头,其中包含例如 20 页,并且可以多次包含单词 “基于股票的补偿”在诸如“..是授予基于股票的补偿的日期...”这样的句子中。
第二个问题是在财务报表中找到正确的table。可以有各种较小的 tables 可以发生“基于股票的补偿”。但是,在这种情况下,假设我们正在寻找 table 称为“合并现金流量表”,而不是例如“下一财政年度的估计预算”等
第三题是单词本身。 “Stock-based compensation”可以有不同的形式,例如“Stock based compensation”、“Compensation”、“Stock based compensation & other compensation”等。但是,正如我们现在所说的这种“Stock-based compensation”以一种或另一种形式无论如何应该在右边table,找到正确的线应该不是主要问题。
例如,我使用正则表达式来缩小我正在寻找的正确单词的选项范围
def find_sum(word_to_look_for):
txt_file = r"fina.txt"
find = pattern
digitals = "\d+|;" #trying to find if any digits or ";" can be found on the row
with open(txt_file, "r") as in_text:
for row in in_text:
if re.findall(find, row, flags=re.IGNORECASE):
if re.findall(digitals, row):
expense_row = row.split(";")[1].strip("-")
expenses = re.sub("[^\d\,]", "", expense_row) #if e.g 2.512,00
return expenses
else:
pass
这解决了一些问题,但我目前正在考虑是否应该在这种情况下实施 ML 或 NLP 技术,或者这是否足够容易用正则表达式解决,只需使用 n-amount 缩小可能的行数if 语句?
使用带有空白字符的词来查找,可以在函数中使用 .* 连接符创建正则表达式以允许匹配这些词之间的任何内容。
def find_sum(word_to_look_for):
txt_file = r"fina.txt"
find = ".*".join([re.escape(w) for w in word_to_look_for.split()]) + r"\D*(\d+(?:[,.]\d+)*)"
with open(txt_file, "r") as in_text:
for row in in_text:
match = re.search(find, row, flags=re.IGNORECASE)
if match:
return match.group(1)
return ""
import re
def find_sum(word_to_look_for):
txt_file = r"fina.txt"
find = ".*".join([re.escape(w) for w in word_to_look_for.split()]) + r"\D*(\d+(?:[,.]\d+)*)"
in_text = ['...', 'XXX', 'Stock-based compensation;2,234.55']
#with open(txt_file, "r") as in_text:
for row in in_text:
match = re.search(find, row, flags=re.IGNORECASE)
if match:
return match.group(1)
return ""
wtlf = "Stock based compensation"
print(find_sum(wtlf))
结果:2,234.55
正则表达式:
Stock.*based.*compensation\D*(\d+(?:[,.]\d+)*)
解释
--------------------------------------------------------------------------------
Stock 'Stock'
--------------------------------------------------------------------------------
.* any character except \n (0 or more times
(matching the most amount possible))
--------------------------------------------------------------------------------
based 'based'
--------------------------------------------------------------------------------
.* any character except \n (0 or more times
(matching the most amount possible))
--------------------------------------------------------------------------------
compensation 'compensation'
--------------------------------------------------------------------------------
\D* non-digits (all but 0-9) (0 or more times
(matching the most amount possible))
--------------------------------------------------------------------------------
( group and capture to :
--------------------------------------------------------------------------------
\d+ digits (0-9) (1 or more times (matching
the most amount possible))
--------------------------------------------------------------------------------
(?: group, but do not capture (0 or more
times (matching the most amount
possible)):
--------------------------------------------------------------------------------
[,.] any character of: ',', '.'
--------------------------------------------------------------------------------
\d+ digits (0-9) (1 or more times
(matching the most amount possible))
--------------------------------------------------------------------------------
)* end of grouping
--------------------------------------------------------------------------------
) end of
感谢您的回答,这个
find = ".*".join([re.escape(w) for w in word_to_look_for.split()]) + r"\D*(\d+(?:[,.]\d+)*)"
效果很好。 但是,我仍然遇到一个问题,因为在我的 FinaStatements 中有两个几乎相同的 tables,一个用于预算,一个用于显示去年的数字。这两个 table 都在页面顶部标有清晰的标题。 有了上面的这个答案,我得到了这两个匹配项,因为该行本身看起来很相似,但我只想要另一个匹配项。
我在 OCR 过程中添加了一个文本指示每个页面的开始,然后寻找正确的页面,包括正确的 table,但似乎比想象的要难。有什么想法吗?