如何决定激活函数?
How to decide on activation function?
目前有很多激活函数,比如sigmoid,tanh,ReLU(首选),但是我有一个问题是需要考虑哪些选择,以便选择某个激活函数。
例如:当我们想在 GAN 中对网络进行上采样时,我们更喜欢使用 LeakyReLU。
我是这方面的新手,对于在不同情况下使用哪种激活函数,我还没有找到具体的解决方案。
我到目前为止的知识:
Sigmoid :当你有一个二进制 class 来识别
谭:?
ReLU:?
LeakyReLU :当你想上采样时
任何帮助或文章将不胜感激。
这是一个开放的研究问题。激活的选择也与模型的体系结构和可用的计算/资源交织在一起,因此这不是可以孤立地解决的问题。论文 Efficient Backprop, Yann LeCun et. al. 对什么是好的激活函数有很多很好的见解。
话虽如此,这里有一些玩具示例可能有助于获得激活函数的直觉。考虑一个带有一个隐藏层和一个简单分类任务的简单 MLP:
在最后一层中,我们可以将 sigmoid 与 binary_crossentropy 损失结合使用,以便使用逻辑回归的直觉——因为我们只是对学习到的特征进行简单的逻辑回归隐藏层给最后一层。
学习什么类型的特征取决于该隐藏层中使用的激活函数和该隐藏层中的神经元数量。
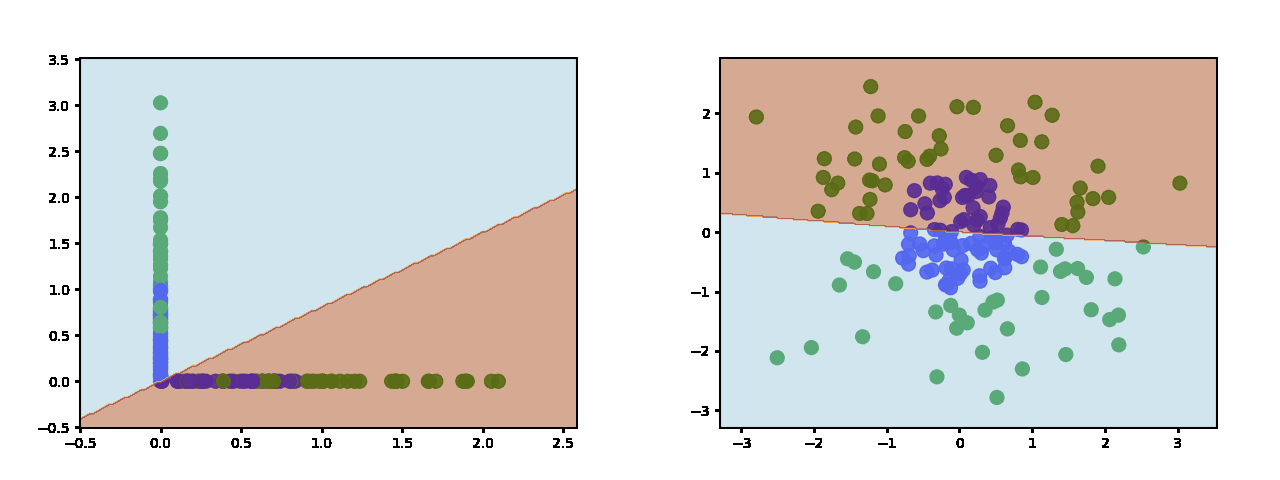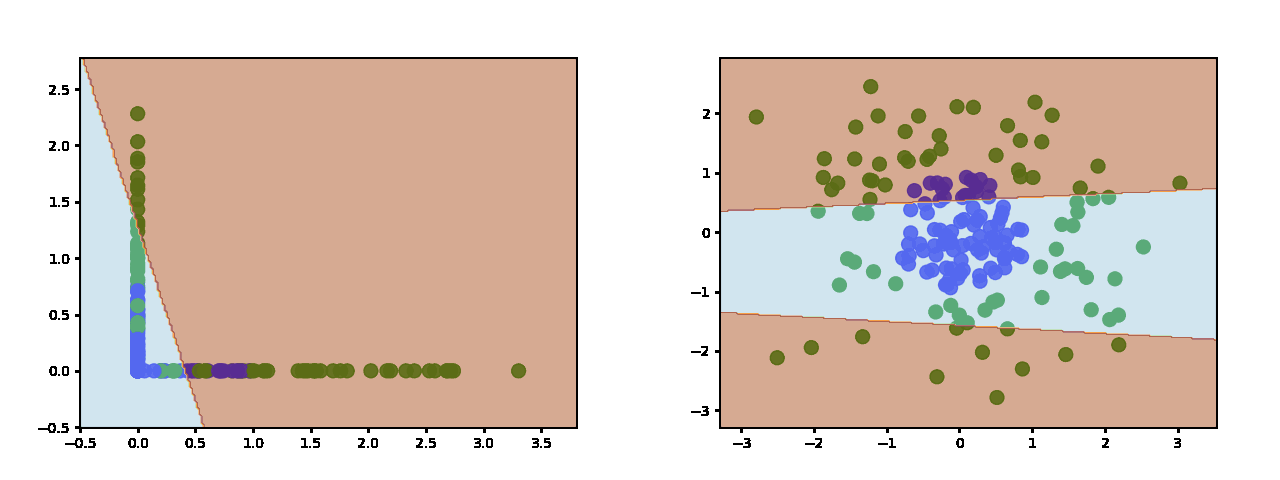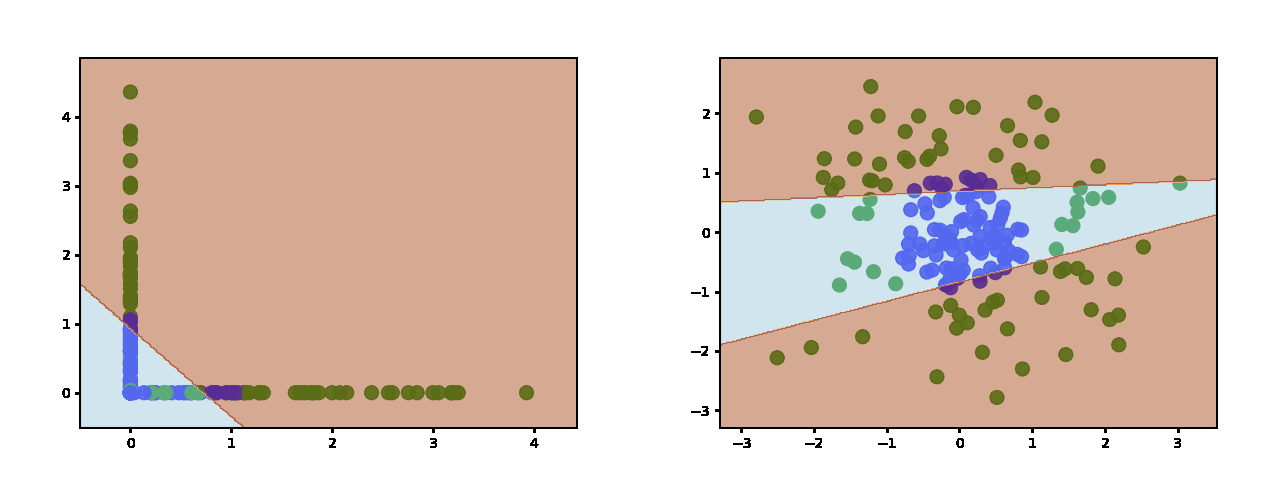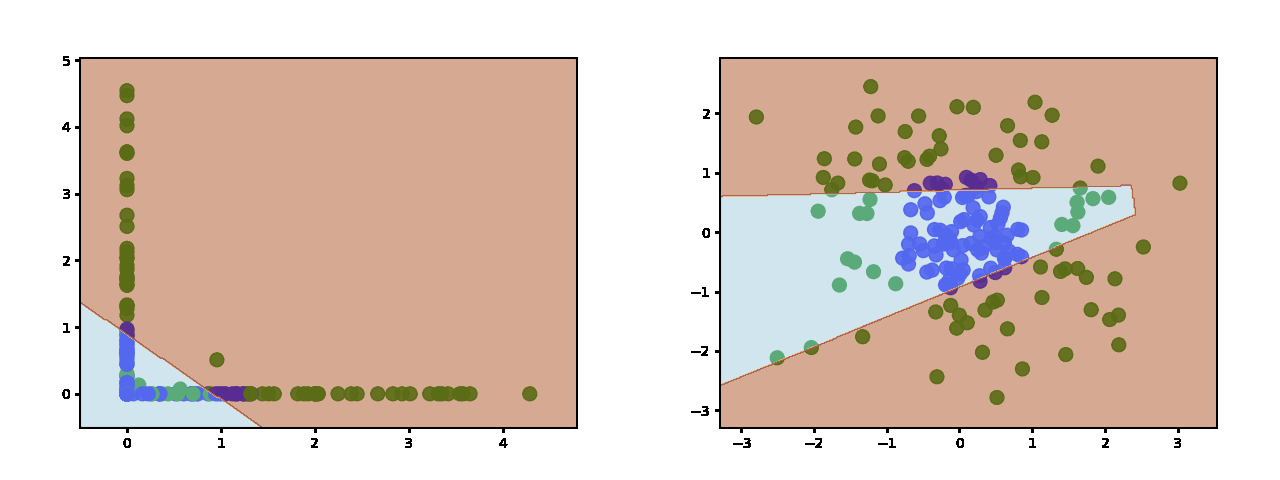
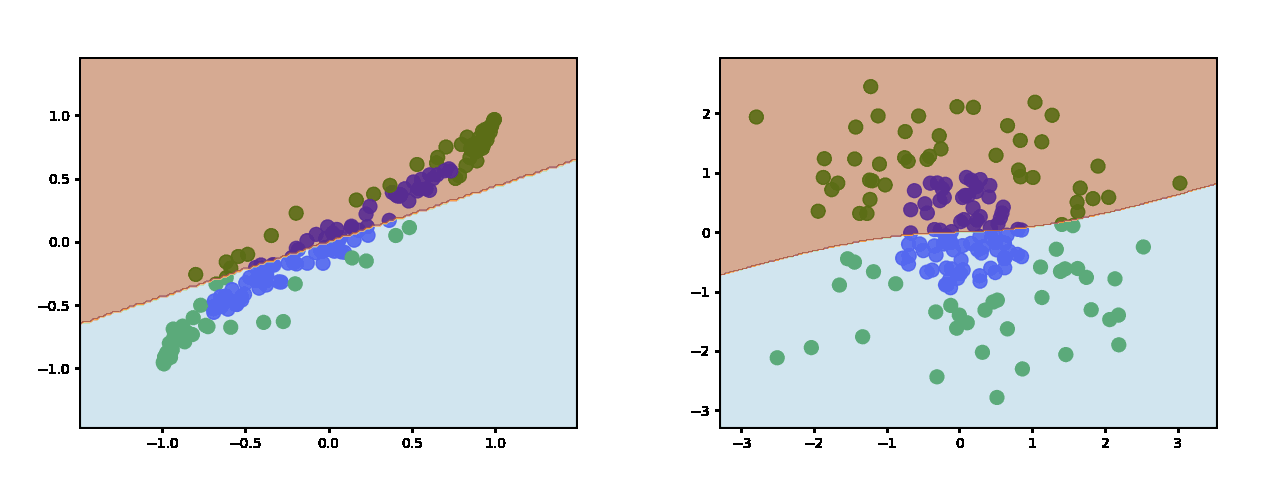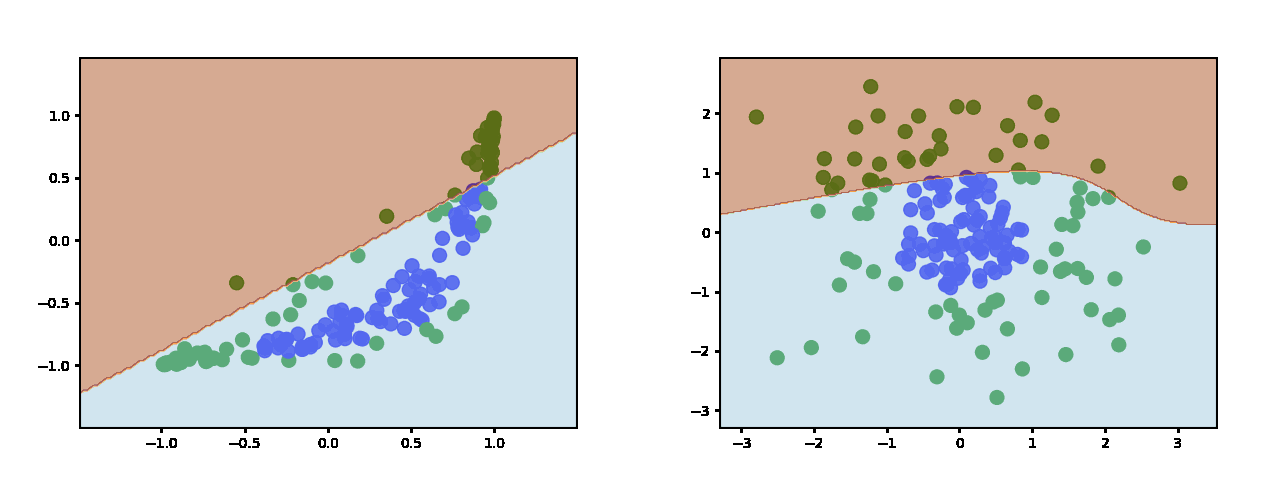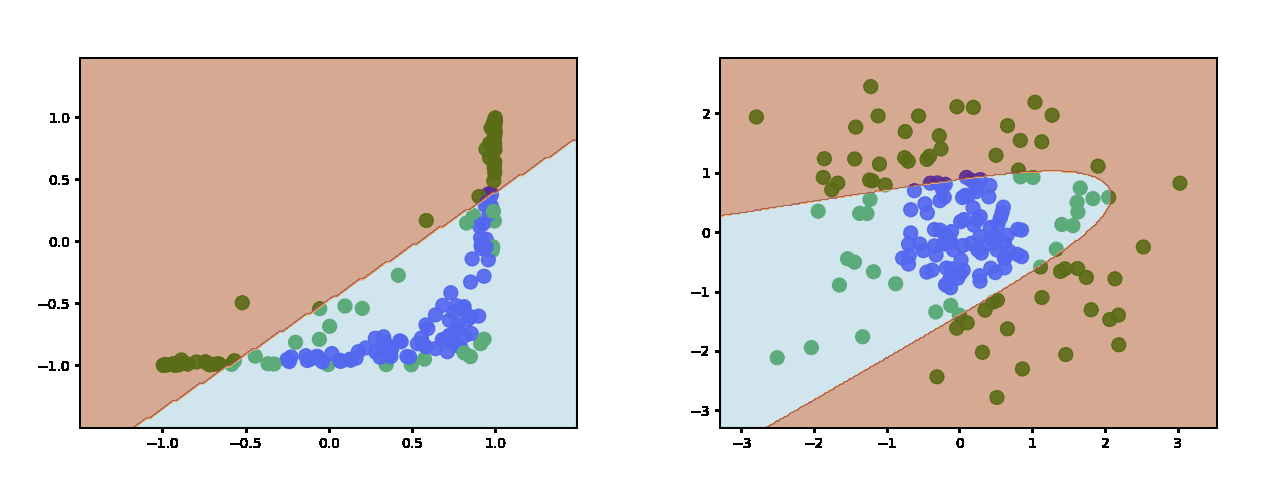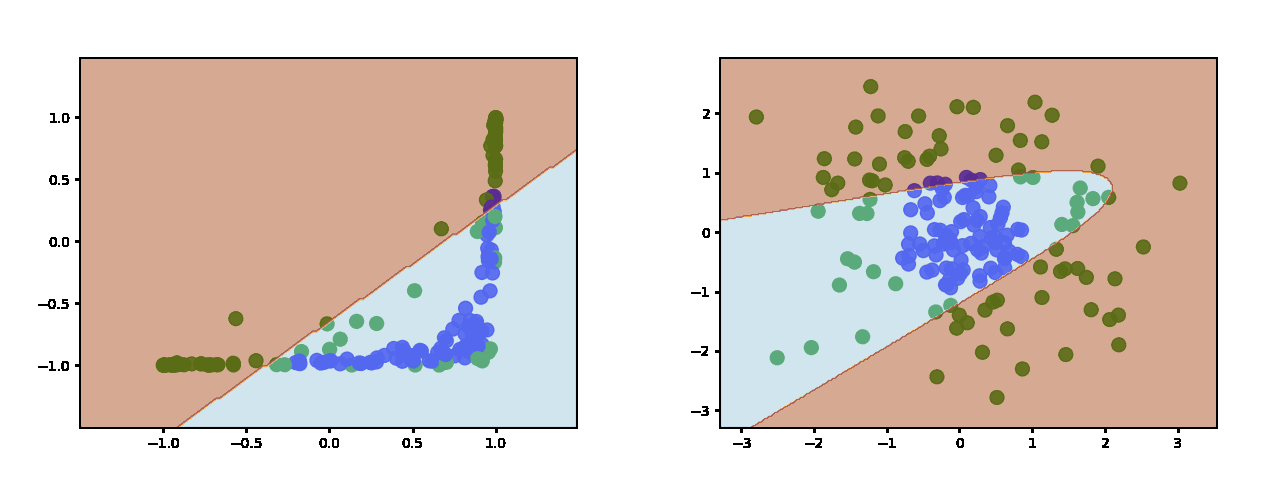
这是 ReLU 在使用两个隐藏神经元时学到的东西:
https://miro.medium.com/max/2000/1*5nK725uTBUeoIA0XjEyA_A.gif
(左边是决策边界在特征中的样子space)
随着你添加更多的神经元,你会得到更多的片段来近似决策边界。这是 3 个隐藏的神经元:
还有 10 个隐藏神经元:
Sigmoid 和 Tanh 产生相似的决策边界(这是 tanh https://miro.medium.com/max/2000/1*jynT0RkGsZFqt3WSFcez4w.gif - sigmoid 是相似的)更连续和正弦。 =23=]
主要区别在于 sigmoid 不是 zero-centered,因此它不是隐藏层的好选择 - 特别是在深层网络中。
目前有很多激活函数,比如sigmoid,tanh,ReLU(首选),但是我有一个问题是需要考虑哪些选择,以便选择某个激活函数。
例如:当我们想在 GAN 中对网络进行上采样时,我们更喜欢使用 LeakyReLU。
我是这方面的新手,对于在不同情况下使用哪种激活函数,我还没有找到具体的解决方案。
我到目前为止的知识:
Sigmoid :当你有一个二进制 class 来识别
谭:?
ReLU:?
LeakyReLU :当你想上采样时
任何帮助或文章将不胜感激。
这是一个开放的研究问题。激活的选择也与模型的体系结构和可用的计算/资源交织在一起,因此这不是可以孤立地解决的问题。论文 Efficient Backprop, Yann LeCun et. al. 对什么是好的激活函数有很多很好的见解。
话虽如此,这里有一些玩具示例可能有助于获得激活函数的直觉。考虑一个带有一个隐藏层和一个简单分类任务的简单 MLP:
在最后一层中,我们可以将 sigmoid 与 binary_crossentropy 损失结合使用,以便使用逻辑回归的直觉——因为我们只是对学习到的特征进行简单的逻辑回归隐藏层给最后一层。
学习什么类型的特征取决于该隐藏层中使用的激活函数和该隐藏层中的神经元数量。
这是 ReLU 在使用两个隐藏神经元时学到的东西:
https://miro.medium.com/max/2000/1*5nK725uTBUeoIA0XjEyA_A.gif
{kind=link}
(左边是决策边界在特征中的样子space)
随着你添加更多的神经元,你会得到更多的片段来近似决策边界。这是 3 个隐藏的神经元:
还有 10 个隐藏神经元:
Sigmoid 和 Tanh 产生相似的决策边界(这是 tanh https://miro.medium.com/max/2000/1*jynT0RkGsZFqt3WSFcez4w.gif - sigmoid 是相似的)更连续和正弦。 =23=]
{kind=link}
主要区别在于 sigmoid 不是 zero-centered,因此它不是隐藏层的好选择 - 特别是在深层网络中。