需要 Tesseract 收据扫描建议
Tesseract receipt scanning advice needed
我在 Tesseract 的各种 OCR 项目中断断续续地挣扎,今天我发现了一个用例,我认为这对它来说是一个灌篮,但几个小时后我仍然不满意。我想在这里提出问题,看看是否有其他人对如何解决这个任务有建议。
我妻子今天早上来找我,问她是否可以轻松扫描沃尔玛的收据,并随着时间的推移建立类别和特定商品的价格历史记录,以便我们可以做一些趋势分析并轻松深入了解支出的去向。起初我觉得这是一个非常高的要求,但在进行了一些挖掘之后,我发现了一些让我觉得这是可以实现的事情:
沃尔玛收据一般,结构合理,易于阅读。他们甚至包括每个项目的 UPC(可能针对 UPC 数据库进行查找?)并且似乎用 F 或 I 对食品进行分类(不确定有什么区别)并且还有一个税码列,这可能会被证明是有用的我了解了代码含义的秘密。
我进一步发现有某种沃尔玛商品查找 API,我可以访问它,这在 UPC 查找中很有用。
他们有一款适用于智能手机的应用程序,可让您扫描印在每张收据上的二维码。该应用程序从收据中查找 "TC" 代码,并从他们的服务器中提取完整的明细收据。它向您展示了收据的出色图形表示,包括所有项目的缩略图和费用等。如果这个应用程序只是简单地对收据进行分类和汇总,我就完成了!但是,唉,这不是应用程序的目的....
最后一个难题是,您可以导出收据的计算机生成的 PNG 图像,以备您保存并丢弃纸质版本时使用。这对我来说就是赚钱,因为这些 PNG 是计算机创建的,因此不受拍照或扫描纸质收据的问题影响
其中之一的示例(略微编辑以遮盖某些区域,但在其他方面与从应用程序中获得的完全相同)位于此处:
https://postimg.cc/image/s56o0wbzf/
您可以看到文本的重要部分完全对齐在 5 列中,这就是这个问题的最终目的。如何让 Tesseract 准确地将其 OCR 转换为文本。我有很多想法可以从这里获取它,但这一切都始于 OCR!
我自己最接近的是这里的这个例子:
我使用 psm6 和一个字符限制集来强制它只执行大写 + 数字 + 几个符号:
tessedit_char_whitelist 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ#()/*@%-.
乍一看,OCR 似乎几乎匹配。但是当你深入挖掘时,你会发现它总体上非常失败。 3 和 8 几乎总是错误的。与 6s 和 5s 相同。然后有时它会完全跳过字符或开始分崩离析(如示例中的第 31+ 行)。它开始将 2 视为 1,甚至只是缺少字符。第 33 行的 SO PIZZA 应为“2.82”,但结果为“32”。
我尝试对图像进行一些预处理以加厚字符并确保它是纯黑白的,但 none 我的努力比沃尔玛的原始图像更接近 +以上命令。
理想情况下,因为这是一个结构良好的 PNG,它可能始终具有相同的宽度,如果我可以按像素宽度定义列,以便 Tesseract 独立处理每一列,我会很高兴。我试图对此进行研究,但我看到提到的 UZN 文件并没有转化为像素宽度,而且它们似乎高度是一个对这些不起作用的因素,因为高度总是可变的。
此外,我需要弄清楚如何训练 Tesseract 100% 准确地识别数字(字母并不重要)。我开始研究如何训练该程序,但老实说,它很快就让我头疼了,因为文档中的训练范围更多的是让它识别整个语言,而不仅仅是 10 位数字。
最终的最终解决方案是一个命令管道链,它从应用程序中获取原始 PNG,并返回一个 CSV,其中包含收据重要部分的 5 列数据。我不希望出现这个问题,但是任何指导我实现它的帮助将不胜感激!此刻我只是不想再次被Tesseract鞭打,所以我决心想办法掌握她!
我最终完全解决了这个问题并且对结果非常满意所以我想我会 post 它以防其他人发现它有用。
我不必进行任何图像分割,而是使用正则表达式,因为沃尔玛收据是如此可预测。
我在 Windows 所以我创建了一个 powershell 脚本来 运行 转换命令和正则表达式查找和替换:
# -----------------------------------------------------------------
# Script: ParseReceipt.ps1
# Author: Jim Sanders
# Date: 7/27/2015
# Keywords: tesseract OCR ImageMagick CSV
# Comments:
# Used to convert a Wal-mart receipt image to a CSV file
# -----------------------------------------------------------------
param(
[Parameter(Mandatory=$true)] [string]$image
) # end param
# create output and temporary files based on input name
$base = (Get-ChildItem -Filter $image -File).BaseName
$csvOutfile = $base + ".txt"
$upscaleImage = $base + "_150.png"
$ocrFile = $base + "_ocr"
# upscale by 150% to ensure OCR works consistently
convert $image -resize 150% $upscaleImage
# perform the OCR to a temporary file
tesseract $upscaleImage -psm 6 $ocrFile
# column headers for the CSV
$newline = "Description,UPC,Type,Cost,TaxType`n"
$newline | Out-File $csvOutfile
# read in the OCR file and write back out the CSV (Tesseract automatically adds .txt to the file name)
$lines = Get-Content "$ocrFile.txt"
Foreach ($line in $lines) {
# This wraps the 12 digit UPC code and the price with commas, giving us our 5 columns for CSV
$newline = $line -replace '\s\d{12}\s',',$&,' -replace '.\d+\.\d{2}.',',$&,' -replace ',\s',',' -replace '\s,',','
$newline | Out-File -Append $csvOutfile
}
# clean up temporary files
del $upscaleImage
del "$ocrFile.txt"
生成的文件需要在 Excel 中打开,然后将文本转为列功能 运行,这样它就不会通过自动将 UPC 代码转换为数字来破坏 UPC 代码。这是一个众所周知的问题,我不会深入探讨,但有多种方法可以处理,我选择了这种稍微更手动的方法。
我最高兴的是得到一个简单的 .csv 我可以双击但我找不到一个很好的方法来做到这一点而不破坏 UPC 代码更像是用这种格式包装它们:
"=""12345"""
这确实有效,但我希望 UPC 代码只是数字 Excel 中的文本,以防我稍后能够对沃尔玛 API 进行查找。
无论如何,这是他们在导入和一些快速格式化后的样子:
https://s3.postimg.cc/b6cjsb4bn/Receipt_Excel.png
我仍然需要对不是行项目的行进行一些垃圾清理,但这一切只需要几秒钟,所以不会太困扰我。
感谢@RevJohn 在正确方向上的推动,我不会想尝试简单地缩放图像,但这让 Tesseract 的世界变得不同!
收据上的文本识别是 OCR 最难处理的问题之一。
原因很多:
- 收据是用廉价打印机打印在廉价纸上的 - 使它们便宜,不易读!
- 他们有大量的密集文本(尤其是沃尔玛收据)
- 现有的 OCR 引擎几乎专门针对非收据数据(书籍、文档等)进行训练
- 收据结构介于表格和自由格式之间,任何排版引擎都难以处理。
您最好的选择是执行以下操作:
- 分析输入图像。如果它们很难用眼睛阅读,那么它们也很难阅读以进行超正方体。
- 执行额外的图像预处理。图像缩放(0.5x、1.5x、2x)有时会有很大帮助。清除现有噪音也有帮助。
- Tesseract 训练。做起来并不难:)
- OCR 结果后处理以确保排版。
布局最好通过分析结果的几何形状来执行,而不是通过正则表达式。如果 OCR 有错误,则正则表达式会出现问题。例如,使用几何图形,您找到一个很好的 UPC 编号候选者,通过字符的中心画一条线,然后您就可以确切地知道哪个价格属于该 UPC。
此外,一些商业解决方案对收据扫描进行了自定义,甚至可以 运行 在移动设备上非常快。
我正在为移动设备工作的公司,MicroBlink, has an OCR module。如果您使用 iOS,您可以使用 CocoaPods
轻松尝试
pod try PPBlinkOCR
我在 Tesseract 的各种 OCR 项目中断断续续地挣扎,今天我发现了一个用例,我认为这对它来说是一个灌篮,但几个小时后我仍然不满意。我想在这里提出问题,看看是否有其他人对如何解决这个任务有建议。
我妻子今天早上来找我,问她是否可以轻松扫描沃尔玛的收据,并随着时间的推移建立类别和特定商品的价格历史记录,以便我们可以做一些趋势分析并轻松深入了解支出的去向。起初我觉得这是一个非常高的要求,但在进行了一些挖掘之后,我发现了一些让我觉得这是可以实现的事情:
沃尔玛收据一般,结构合理,易于阅读。他们甚至包括每个项目的 UPC(可能针对 UPC 数据库进行查找?)并且似乎用 F 或 I 对食品进行分类(不确定有什么区别)并且还有一个税码列,这可能会被证明是有用的我了解了代码含义的秘密。
我进一步发现有某种沃尔玛商品查找 API,我可以访问它,这在 UPC 查找中很有用。
他们有一款适用于智能手机的应用程序,可让您扫描印在每张收据上的二维码。该应用程序从收据中查找 "TC" 代码,并从他们的服务器中提取完整的明细收据。它向您展示了收据的出色图形表示,包括所有项目的缩略图和费用等。如果这个应用程序只是简单地对收据进行分类和汇总,我就完成了!但是,唉,这不是应用程序的目的....
最后一个难题是,您可以导出收据的计算机生成的 PNG 图像,以备您保存并丢弃纸质版本时使用。这对我来说就是赚钱,因为这些 PNG 是计算机创建的,因此不受拍照或扫描纸质收据的问题影响
其中之一的示例(略微编辑以遮盖某些区域,但在其他方面与从应用程序中获得的完全相同)位于此处:
https://postimg.cc/image/s56o0wbzf/
您可以看到文本的重要部分完全对齐在 5 列中,这就是这个问题的最终目的。如何让 Tesseract 准确地将其 OCR 转换为文本。我有很多想法可以从这里获取它,但这一切都始于 OCR!
我自己最接近的是这里的这个例子:
我使用 psm6 和一个字符限制集来强制它只执行大写 + 数字 + 几个符号:
tessedit_char_whitelist 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ#()/*@%-.
乍一看,OCR 似乎几乎匹配。但是当你深入挖掘时,你会发现它总体上非常失败。 3 和 8 几乎总是错误的。与 6s 和 5s 相同。然后有时它会完全跳过字符或开始分崩离析(如示例中的第 31+ 行)。它开始将 2 视为 1,甚至只是缺少字符。第 33 行的 SO PIZZA 应为“2.82”,但结果为“32”。
我尝试对图像进行一些预处理以加厚字符并确保它是纯黑白的,但 none 我的努力比沃尔玛的原始图像更接近 +以上命令。
理想情况下,因为这是一个结构良好的 PNG,它可能始终具有相同的宽度,如果我可以按像素宽度定义列,以便 Tesseract 独立处理每一列,我会很高兴。我试图对此进行研究,但我看到提到的 UZN 文件并没有转化为像素宽度,而且它们似乎高度是一个对这些不起作用的因素,因为高度总是可变的。
此外,我需要弄清楚如何训练 Tesseract 100% 准确地识别数字(字母并不重要)。我开始研究如何训练该程序,但老实说,它很快就让我头疼了,因为文档中的训练范围更多的是让它识别整个语言,而不仅仅是 10 位数字。
最终的最终解决方案是一个命令管道链,它从应用程序中获取原始 PNG,并返回一个 CSV,其中包含收据重要部分的 5 列数据。我不希望出现这个问题,但是任何指导我实现它的帮助将不胜感激!此刻我只是不想再次被Tesseract鞭打,所以我决心想办法掌握她!
我最终完全解决了这个问题并且对结果非常满意所以我想我会 post 它以防其他人发现它有用。
我不必进行任何图像分割,而是使用正则表达式,因为沃尔玛收据是如此可预测。
我在 Windows 所以我创建了一个 powershell 脚本来 运行 转换命令和正则表达式查找和替换:
# -----------------------------------------------------------------
# Script: ParseReceipt.ps1
# Author: Jim Sanders
# Date: 7/27/2015
# Keywords: tesseract OCR ImageMagick CSV
# Comments:
# Used to convert a Wal-mart receipt image to a CSV file
# -----------------------------------------------------------------
param(
[Parameter(Mandatory=$true)] [string]$image
) # end param
# create output and temporary files based on input name
$base = (Get-ChildItem -Filter $image -File).BaseName
$csvOutfile = $base + ".txt"
$upscaleImage = $base + "_150.png"
$ocrFile = $base + "_ocr"
# upscale by 150% to ensure OCR works consistently
convert $image -resize 150% $upscaleImage
# perform the OCR to a temporary file
tesseract $upscaleImage -psm 6 $ocrFile
# column headers for the CSV
$newline = "Description,UPC,Type,Cost,TaxType`n"
$newline | Out-File $csvOutfile
# read in the OCR file and write back out the CSV (Tesseract automatically adds .txt to the file name)
$lines = Get-Content "$ocrFile.txt"
Foreach ($line in $lines) {
# This wraps the 12 digit UPC code and the price with commas, giving us our 5 columns for CSV
$newline = $line -replace '\s\d{12}\s',',$&,' -replace '.\d+\.\d{2}.',',$&,' -replace ',\s',',' -replace '\s,',','
$newline | Out-File -Append $csvOutfile
}
# clean up temporary files
del $upscaleImage
del "$ocrFile.txt"
生成的文件需要在 Excel 中打开,然后将文本转为列功能 运行,这样它就不会通过自动将 UPC 代码转换为数字来破坏 UPC 代码。这是一个众所周知的问题,我不会深入探讨,但有多种方法可以处理,我选择了这种稍微更手动的方法。
我最高兴的是得到一个简单的 .csv 我可以双击但我找不到一个很好的方法来做到这一点而不破坏 UPC 代码更像是用这种格式包装它们:
"=""12345"""
这确实有效,但我希望 UPC 代码只是数字 Excel 中的文本,以防我稍后能够对沃尔玛 API 进行查找。
无论如何,这是他们在导入和一些快速格式化后的样子:
https://s3.postimg.cc/b6cjsb4bn/Receipt_Excel.png
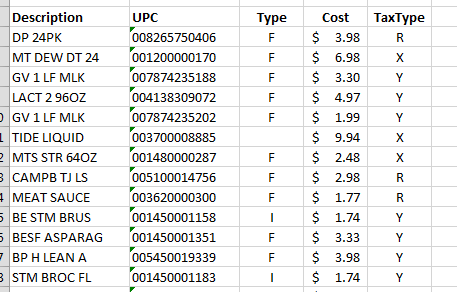{kind=link}
我仍然需要对不是行项目的行进行一些垃圾清理,但这一切只需要几秒钟,所以不会太困扰我。
感谢@RevJohn 在正确方向上的推动,我不会想尝试简单地缩放图像,但这让 Tesseract 的世界变得不同!
收据上的文本识别是 OCR 最难处理的问题之一。
原因很多:
- 收据是用廉价打印机打印在廉价纸上的 - 使它们便宜,不易读!
- 他们有大量的密集文本(尤其是沃尔玛收据)
- 现有的 OCR 引擎几乎专门针对非收据数据(书籍、文档等)进行训练
- 收据结构介于表格和自由格式之间,任何排版引擎都难以处理。
您最好的选择是执行以下操作:
- 分析输入图像。如果它们很难用眼睛阅读,那么它们也很难阅读以进行超正方体。
- 执行额外的图像预处理。图像缩放(0.5x、1.5x、2x)有时会有很大帮助。清除现有噪音也有帮助。
- Tesseract 训练。做起来并不难:)
- OCR 结果后处理以确保排版。
布局最好通过分析结果的几何形状来执行,而不是通过正则表达式。如果 OCR 有错误,则正则表达式会出现问题。例如,使用几何图形,您找到一个很好的 UPC 编号候选者,通过字符的中心画一条线,然后您就可以确切地知道哪个价格属于该 UPC。
此外,一些商业解决方案对收据扫描进行了自定义,甚至可以 运行 在移动设备上非常快。
我正在为移动设备工作的公司,MicroBlink, has an OCR module。如果您使用 iOS,您可以使用 CocoaPods
轻松尝试pod try PPBlinkOCR