矩阵乘法的并行和分布式算法
Parallel and distributed algorithms for matrix multiplication
当我查找 Matrix multiplication algorithm
的维基百科页面时出现问题
它说:
This algorithm has a critical path length of Θ((log n)^2) steps, meaning it takes that much time on an ideal machine with an infinite number of processors; therefore, it has a maximum possible speedup of Θ(n3/((log n)^2)) on any real computer.
(引用自第 "Parallel and distributed algorithms/Shared-memory parallelism.")
由于假设有无限个处理器,乘法运算应该在O(1)中完成。然后将所有元素加起来,这也应该是一个常数时间。因此,最长的关键路径应该是 O(1) 而不是 Θ((log n)^2).
我想知道 O 和 Θ 之间是否有区别,我在哪里弄错了?
问题已经解决,非常感谢@Chris Beck。答案应该分为两部分。
首先,一个低级错误是我没有计算求和的时间。求和需要O(log(N))运算(想想二进制加法).
其次,正如 Chris 指出的那样,重要的问题在处理器中需要时间 O(log(N))。最重要的是,最长的关键路径应该是 O(log(N)^2) 而不是 O(1).
对于O和Θ的混淆,我在Big_O_Notation_Wikipedia中找到了答案。
Big O is the most commonly used asymptotic notation for comparing functions, although in many cases Big O may be replaced with Big Theta Θ for asymptotically tighter bounds.
最后的结论我错了。 O(log(N)^2) 不会发生在求和和处理器时,而是发生在我们拆分矩阵时。感谢@displayName 提醒我这一点。此外,克里斯对非平凡问题的回答对于研究并行系统仍然非常有用。感谢下方所有暖心回答者!
"Infinite number of processors" 可能是一种糟糕的措辞方式。
人们从理论的角度研究并行计算时,基本上想问"assuming I have more processors than I need, how fast can I possibly do it"。
这是一个定义明确的问题——仅仅因为你有大量的处理器并不意味着矩阵乘法是 O(1)。
假设您在单个处理器上采用任何简单的矩阵乘法算法。然后我告诉你,如果你愿意,你可以为每条汇编指令配备一个处理器,因此程序可以是 "parallelized",因为每个处理器只执行一条指令,然后与下一条指令共享其结果。
该计算的时间不是“1”个周期,因为一些处理器必须等待其他处理器完成,而这些处理器正在等待不同的处理器,等等。
一般来说,非平凡问题(输入位none不相关的问题)并行计算需要时间O(log n),否则最后的"answer"处理器不会甚至没有时间依赖所有的输入位。
O(log n) 并行时间紧张的问题被认为是高度可并行化的。人们普遍猜测其中一些人没有这个 属性。如果那不是真的,那么根据计算复杂性理论,P 会崩溃到较低的 class,据推测不会。
矩阵乘法可以在 O(logn) 中使用 n^3 处理器完成。方法如下:
输入:两个 N x N 矩阵 M1 和 M2。 M3 将存储结果。
分配 N 个处理器来计算 M3[i][j] 的值。 M3[i][j] 定义为 Sum(M1[i][k] * M2[k][j]), k = 1..N。在第一步中,所有处理器都执行一次乘法。第一个 M1[i][1] * M2[1][j],第二个 M1[i][2] * M2[2][j],...。每个处理器都保持其价值。现在我们必须对所有这些相乘的对求和。如果我们将总和组织成树,我们可以在 O(logn) 时间内完成此操作:
4 Stage 3
/ \
2 2 Stage 2
/ \ / \
1 1 1 1 Stage 1
我们 运行 使用 N^3 个处理器对所有 (i, j) 并行执行此算法。
这个问题有两个方面,解决了这个问题将得到完整的回答。
- 为什么我们不能通过投入足够数量的处理器将 运行 时间缩短为 O(1)?
- 矩阵乘法的关键路径长度如何等于Θ(log2n)?
一道题追下去。
无限数量的处理器
这一点的简单答案是理解两个术语,即。 任务粒度和任务依赖性。
- 任务粒度-表示任务分解的精细程度。即使你有无限的处理器,最大分解对于一个问题来说仍然是有限的。
- Task Dependency - 意味着什么是简单的步骤只能按顺序执行。就像,除非您已阅读输入,否则您无法修改输入。所以修改总是先于读取输入,不能与之并行进行。
因此,对于具有四个步骤 A, B, C, D 的过程,使得 D 依赖于 C,C 依赖于 B,B 依赖于 A,那么单个处理器的工作速度将与 2 个处理器一样快,将与 4 个处理器一样快,将与无限个处理器一样快。
这解释了第一个项目符号。
并行矩阵乘法的关键路径长度
- 如果您必须将大小为
n X n 的方阵分成四个大小为 [n/2] X [n/2] 的块,然后继续划分,直到达到单个元素(或大小为 [= 的矩阵) 13=]) 这种 树状 设计的层数是 O(log (n)).
- 因此,对于并行矩阵乘法,由于我们必须递归地划分两个大小为 n 的矩阵而不是一个矩阵,直到最后一个元素,它需要 O(log2 n)次。
- 事实上,这个界限更紧,不仅仅是 O(log2n),而是 Θ (log2n).
如果我们使用†主定理来证明运行时间,我们可以使用重复:
M(n) = 8 * M(n/2) + Θ(Log n)
这是主定理的情况 - 2 并给出 运行-时间 Θ(log2n) .
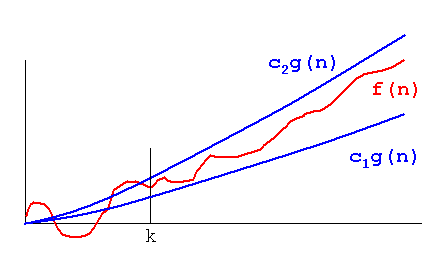
Big O 和 Theta 之间的区别是,Big O 只告诉一个过程不会超出 Big O 提到的范围,而 Theta 告诉函数不仅有上限,还有下限与 Theta 中提到的内容。因此,实际上,函数复杂度的 plot 将夹在同一个函数之间,乘以两个不同的常数,如下图所示,或者换句话说,函数将以同样的速度增长:
图片取自:http://xlinux.nist.gov/dads/Images/thetaGraph.gif
所以,我想说的是,对于你的情况,你可以忽略符号,你没有 "gravely" 在两者之间弄错。
总结...
我想定义另一个术语 加速或并行。它被定义为最佳顺序执行时间(也称为工作)与并行执行时间的比率。您链接到的维基百科页面上已经给出的最佳顺序访问时间是O(n3)。并行执行时间为O(log2n).
因此,加速比为= O(n3/log2n) .
尽管加速看起来如此简单明了,但由于移动数据固有的通信成本,在实际情况下实现它非常困难。
†大定理
设a为大于等于1的整数,b为大于1的实数,设c 是一个正实数,d 是一个非负实数。给定形式的重复 -
T (n) = a * T(n/b) + nc 当 n > 1
然后对于 n 的 b 的幂,如果
- Logba < c, T(n) = Θ(nc);
- Logba = c, T(n) = Θ(nc * Log n);
- Logba > c, T(n) = Θ(nlogba).
当我查找 Matrix multiplication algorithm
的维基百科页面时出现问题它说:
This algorithm has a critical path length of
Θ((log n)^2)steps, meaning it takes that much time on an ideal machine with an infinite number of processors; therefore, it has a maximum possible speedup ofΘ(n3/((log n)^2))on any real computer.
(引用自第 "Parallel and distributed algorithms/Shared-memory parallelism.")
由于假设有无限个处理器,乘法运算应该在O(1)中完成。然后将所有元素加起来,这也应该是一个常数时间。因此,最长的关键路径应该是 O(1) 而不是 Θ((log n)^2).
我想知道 O 和 Θ 之间是否有区别,我在哪里弄错了?
问题已经解决,非常感谢@Chris Beck。答案应该分为两部分。
首先,一个低级错误是我没有计算求和的时间。求和需要O(log(N))运算(想想二进制加法).
其次,正如 Chris 指出的那样,重要的问题在处理器中需要时间 O(log(N))。最重要的是,最长的关键路径应该是 O(log(N)^2) 而不是 O(1).
对于O和Θ的混淆,我在Big_O_Notation_Wikipedia中找到了答案。
Big O is the most commonly used asymptotic notation for comparing functions, although in many cases Big O may be replaced with Big Theta Θ for asymptotically tighter bounds.
最后的结论我错了。 O(log(N)^2) 不会发生在求和和处理器时,而是发生在我们拆分矩阵时。感谢@displayName 提醒我这一点。此外,克里斯对非平凡问题的回答对于研究并行系统仍然非常有用。感谢下方所有暖心回答者!
"Infinite number of processors" 可能是一种糟糕的措辞方式。
人们从理论的角度研究并行计算时,基本上想问"assuming I have more processors than I need, how fast can I possibly do it"。
这是一个定义明确的问题——仅仅因为你有大量的处理器并不意味着矩阵乘法是 O(1)。
假设您在单个处理器上采用任何简单的矩阵乘法算法。然后我告诉你,如果你愿意,你可以为每条汇编指令配备一个处理器,因此程序可以是 "parallelized",因为每个处理器只执行一条指令,然后与下一条指令共享其结果。
该计算的时间不是“1”个周期,因为一些处理器必须等待其他处理器完成,而这些处理器正在等待不同的处理器,等等。
一般来说,非平凡问题(输入位none不相关的问题)并行计算需要时间O(log n),否则最后的"answer"处理器不会甚至没有时间依赖所有的输入位。
O(log n) 并行时间紧张的问题被认为是高度可并行化的。人们普遍猜测其中一些人没有这个 属性。如果那不是真的,那么根据计算复杂性理论,P 会崩溃到较低的 class,据推测不会。
矩阵乘法可以在 O(logn) 中使用 n^3 处理器完成。方法如下:
输入:两个 N x N 矩阵 M1 和 M2。 M3 将存储结果。
分配 N 个处理器来计算 M3[i][j] 的值。 M3[i][j] 定义为 Sum(M1[i][k] * M2[k][j]), k = 1..N。在第一步中,所有处理器都执行一次乘法。第一个 M1[i][1] * M2[1][j],第二个 M1[i][2] * M2[2][j],...。每个处理器都保持其价值。现在我们必须对所有这些相乘的对求和。如果我们将总和组织成树,我们可以在 O(logn) 时间内完成此操作:
4 Stage 3
/ \
2 2 Stage 2
/ \ / \
1 1 1 1 Stage 1
我们 运行 使用 N^3 个处理器对所有 (i, j) 并行执行此算法。
这个问题有两个方面,解决了这个问题将得到完整的回答。
- 为什么我们不能通过投入足够数量的处理器将 运行 时间缩短为 O(1)?
- 矩阵乘法的关键路径长度如何等于Θ(log2n)?
一道题追下去。
无限数量的处理器
这一点的简单答案是理解两个术语,即。 任务粒度和任务依赖性。
- 任务粒度-表示任务分解的精细程度。即使你有无限的处理器,最大分解对于一个问题来说仍然是有限的。
- Task Dependency - 意味着什么是简单的步骤只能按顺序执行。就像,除非您已阅读输入,否则您无法修改输入。所以修改总是先于读取输入,不能与之并行进行。
因此,对于具有四个步骤 A, B, C, D 的过程,使得 D 依赖于 C,C 依赖于 B,B 依赖于 A,那么单个处理器的工作速度将与 2 个处理器一样快,将与 4 个处理器一样快,将与无限个处理器一样快。
这解释了第一个项目符号。
并行矩阵乘法的关键路径长度
- 如果您必须将大小为
n X n的方阵分成四个大小为[n/2] X [n/2]的块,然后继续划分,直到达到单个元素(或大小为 [= 的矩阵) 13=]) 这种 树状 设计的层数是 O(log (n)). - 因此,对于并行矩阵乘法,由于我们必须递归地划分两个大小为 n 的矩阵而不是一个矩阵,直到最后一个元素,它需要 O(log2 n)次。
- 事实上,这个界限更紧,不仅仅是 O(log2n),而是 Θ (log2n).
如果我们使用†主定理来证明运行时间,我们可以使用重复:
M(n) = 8 * M(n/2) + Θ(Log n)
这是主定理的情况 - 2 并给出 运行-时间 Θ(log2n) .
Big O 和 Theta 之间的区别是,Big O 只告诉一个过程不会超出 Big O 提到的范围,而 Theta 告诉函数不仅有上限,还有下限与 Theta 中提到的内容。因此,实际上,函数复杂度的 plot 将夹在同一个函数之间,乘以两个不同的常数,如下图所示,或者换句话说,函数将以同样的速度增长:
图片取自:http://xlinux.nist.gov/dads/Images/thetaGraph.gif
{kind=link}
所以,我想说的是,对于你的情况,你可以忽略符号,你没有 "gravely" 在两者之间弄错。
总结...
我想定义另一个术语 加速或并行。它被定义为最佳顺序执行时间(也称为工作)与并行执行时间的比率。您链接到的维基百科页面上已经给出的最佳顺序访问时间是O(n3)。并行执行时间为O(log2n).
因此,加速比为= O(n3/log2n) .
尽管加速看起来如此简单明了,但由于移动数据固有的通信成本,在实际情况下实现它非常困难。
†大定理
设a为大于等于1的整数,b为大于1的实数,设c 是一个正实数,d 是一个非负实数。给定形式的重复 -
T (n) = a * T(n/b) + nc 当 n > 1
然后对于 n 的 b 的幂,如果
- Logba < c, T(n) = Θ(nc);
- Logba = c, T(n) = Θ(nc * Log n);
- Logba > c, T(n) = Θ(nlogba).