Python/Pandas Select 基于最佳价值分布的列
Python/Pandas Select Columns based on Best Value Distribution
我在 pandas/python 中有一个数据框 (df),其中包含 ['Product'、'OrderDate'、'Sales']。
我注意到有些行、值比其他行具有更好的分布(如在直方图中)。 "Best" 的意思是,形状更分散,或者值的分散使形状看起来比其他行更宽。
如果我想从 +700 种产品中挑选具有更多价差的产品,有没有办法在 pandas/python 中轻松做到这一点?
提前发送。
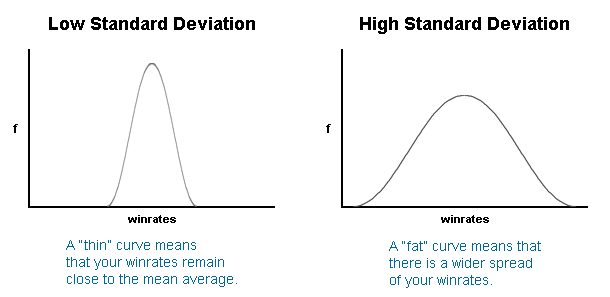
当然可以。您在这里要做的是找到标准偏差最大的 700 个条目。
pandas.DataFrame.std() 将 return 轴的标准偏差,然后您只需要跟踪具有最高对应值的条目。
这里需要注意的是,我不是统计专家,但基本上 scipy 有许多测试可以对您的数据进行测试,以测试它是否可以被视为归一化高斯分布。
我在这里创建了 2 个系列,一个是简单的线性范围,另一个是均值设置为 50,方差设置为 25 的随机归一化采样。
In [48]:
import pandas as pd
import scipy.stats as stats
df = pd.DataFrame({'linear':arange(100), 'normal':np.random.normal(50, 25, 100)})
df
Out[48]:
linear normal
0 0 66.565374
1 1 63.453899
2 2 65.736406
3 3 65.848908
4 4 56.916032
5 5 93.870682
6 6 89.513998
7 7 9.949555
8 8 9.727099
9 9 47.072785
10 10 62.849321
11 11 33.263309
12 12 42.168484
13 13 38.488933
14 14 51.833459
15 15 54.911915
16 16 62.372709
17 17 96.928452
18 18 65.333546
19 19 26.341462
20 20 41.692790
21 21 22.852561
22 22 15.799415
23 23 50.600141
24 24 14.234088
25 25 72.428607
26 26 45.872601
27 27 80.783253
28 28 29.561586
29 29 51.261099
.. ... ...
70 70 32.826052
71 71 35.413106
72 72 49.415386
73 73 28.998378
74 74 32.237667
75 75 86.622402
76 76 105.098296
77 77 53.176413
78 78 -7.954881
79 79 60.313761
80 80 42.739641
81 81 56.667834
82 82 68.046688
83 83 72.189683
84 84 67.125708
85 85 24.798553
86 86 58.845761
87 87 54.559792
88 88 93.116777
89 89 30.209895
90 90 80.952444
91 91 57.895433
92 92 47.392336
93 93 13.136111
94 94 26.624532
95 95 53.461421
96 96 28.782809
97 97 16.342756
98 98 64.768579
99 99 68.410021
[100 rows x 2 columns]
从这个 page 中我们可以使用许多测试,这些测试组合在一起用于 normaltest,即 skewtest 和 kurtosistest,我无法解释这些,但您可以看到线性序列的 p 值很差,而标准化数据的 p 值相对更接近 1:
In [49]:
print('linear skewtest teststat = %6.3f pvalue = %6.4f' % sc.stats.skewtest(df['linear']))
print('normal skewtest teststat = %6.3f pvalue = %6.4f' % sc.stats.skewtest(df['normal']))
print('linear kurtoisis teststat = %6.3f pvalue = %6.4f' % sc.stats.kurtosistest(df['linear']))
print('normal kurtoisis teststat = %6.3f pvalue = %6.4f' % sc.stats.kurtosistest(df['normal']))
print('linear normaltest teststat = %6.3f pvalue = %6.4f' % sc.stats.normaltest(df['linear']))
print('normal normaltest teststat = %6.3f pvalue = %6.4f' % sc.stats.normaltest(df['normal']))
linear skewtest teststat = 1.022 pvalue = 0.3070
normal skewtest teststat = -0.170 pvalue = 0.8652
linear kurtoisis teststat = -5.799 pvalue = 0.0000
normal kurtoisis teststat = -1.113 pvalue = 0.2656
linear normaltest teststat = 34.674 pvalue = 0.0000
normal normaltest teststat = 1.268 pvalue = 0.5304
来自 scipy 网站:
When testing for normality of a small sample of t-distributed
observations and a large sample of normal distributed observation,
then in neither case can we reject the null hypothesis that the sample
comes from a normal distribution. In the first case this is because
the test is not powerful enough to distinguish a t and a normally
distributed random variable in a small sample.
所以你必须尝试上面的方法,看看它是否符合你想要的,希望这对你有所帮助。
我在 pandas/python 中有一个数据框 (df),其中包含 ['Product'、'OrderDate'、'Sales']。 我注意到有些行、值比其他行具有更好的分布(如在直方图中)。 "Best" 的意思是,形状更分散,或者值的分散使形状看起来比其他行更宽。
如果我想从 +700 种产品中挑选具有更多价差的产品,有没有办法在 pandas/python 中轻松做到这一点?
提前发送。
当然可以。您在这里要做的是找到标准偏差最大的 700 个条目。
pandas.DataFrame.std() 将 return 轴的标准偏差,然后您只需要跟踪具有最高对应值的条目。
{kind=link}
这里需要注意的是,我不是统计专家,但基本上 scipy 有许多测试可以对您的数据进行测试,以测试它是否可以被视为归一化高斯分布。
我在这里创建了 2 个系列,一个是简单的线性范围,另一个是均值设置为 50,方差设置为 25 的随机归一化采样。
In [48]:
import pandas as pd
import scipy.stats as stats
df = pd.DataFrame({'linear':arange(100), 'normal':np.random.normal(50, 25, 100)})
df
Out[48]:
linear normal
0 0 66.565374
1 1 63.453899
2 2 65.736406
3 3 65.848908
4 4 56.916032
5 5 93.870682
6 6 89.513998
7 7 9.949555
8 8 9.727099
9 9 47.072785
10 10 62.849321
11 11 33.263309
12 12 42.168484
13 13 38.488933
14 14 51.833459
15 15 54.911915
16 16 62.372709
17 17 96.928452
18 18 65.333546
19 19 26.341462
20 20 41.692790
21 21 22.852561
22 22 15.799415
23 23 50.600141
24 24 14.234088
25 25 72.428607
26 26 45.872601
27 27 80.783253
28 28 29.561586
29 29 51.261099
.. ... ...
70 70 32.826052
71 71 35.413106
72 72 49.415386
73 73 28.998378
74 74 32.237667
75 75 86.622402
76 76 105.098296
77 77 53.176413
78 78 -7.954881
79 79 60.313761
80 80 42.739641
81 81 56.667834
82 82 68.046688
83 83 72.189683
84 84 67.125708
85 85 24.798553
86 86 58.845761
87 87 54.559792
88 88 93.116777
89 89 30.209895
90 90 80.952444
91 91 57.895433
92 92 47.392336
93 93 13.136111
94 94 26.624532
95 95 53.461421
96 96 28.782809
97 97 16.342756
98 98 64.768579
99 99 68.410021
[100 rows x 2 columns]
从这个 page 中我们可以使用许多测试,这些测试组合在一起用于 normaltest,即 skewtest 和 kurtosistest,我无法解释这些,但您可以看到线性序列的 p 值很差,而标准化数据的 p 值相对更接近 1:
In [49]:
print('linear skewtest teststat = %6.3f pvalue = %6.4f' % sc.stats.skewtest(df['linear']))
print('normal skewtest teststat = %6.3f pvalue = %6.4f' % sc.stats.skewtest(df['normal']))
print('linear kurtoisis teststat = %6.3f pvalue = %6.4f' % sc.stats.kurtosistest(df['linear']))
print('normal kurtoisis teststat = %6.3f pvalue = %6.4f' % sc.stats.kurtosistest(df['normal']))
print('linear normaltest teststat = %6.3f pvalue = %6.4f' % sc.stats.normaltest(df['linear']))
print('normal normaltest teststat = %6.3f pvalue = %6.4f' % sc.stats.normaltest(df['normal']))
linear skewtest teststat = 1.022 pvalue = 0.3070
normal skewtest teststat = -0.170 pvalue = 0.8652
linear kurtoisis teststat = -5.799 pvalue = 0.0000
normal kurtoisis teststat = -1.113 pvalue = 0.2656
linear normaltest teststat = 34.674 pvalue = 0.0000
normal normaltest teststat = 1.268 pvalue = 0.5304
来自 scipy 网站:
When testing for normality of a small sample of t-distributed observations and a large sample of normal distributed observation, then in neither case can we reject the null hypothesis that the sample comes from a normal distribution. In the first case this is because the test is not powerful enough to distinguish a t and a normally distributed random variable in a small sample.
所以你必须尝试上面的方法,看看它是否符合你想要的,希望这对你有所帮助。