进程堆栈和 CPU 堆栈有什么区别?
Whats the difference between a process stack and a CPU stack?
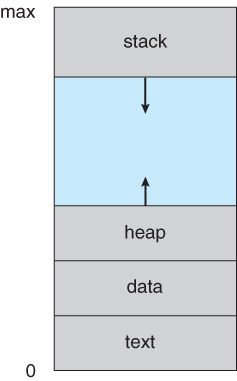
我了解到每个进程在内存中都有自己的area/block,由堆栈、堆、数据和文本(代码)组成(参见this)。
现在我正在阅读有关上下文切换的内容。我读到在上下文切换期间 CPU 寄存器被压入堆栈,然后整个堆栈将被保存到进程控制块中。基本上是这样吗?
如果每个进程都有自己的堆栈,为什么我需要保存堆栈?
当发生上下文切换时,内核会引入一个新进程并 "kicks out" 旧进程。但是当一个旧进程轮到占用CPU时,它之前的状态(它是"kicked out"时的状态)必须恢复到从它停止的地方开始执行。
所有架构的寄存器数量都是有限的。寄存器还包含在要存储以用于逐出的进程状态中。将寄存器保存在堆栈上是为了提高效率,因此您只需将值弹出即可。
此外,每个进程都有自己的进程控制块 (PCB) 来将这些值存储在上下文切换中,这样调度算法就不会受到阻碍,并且可以在一些简单的进程 ID 上工作。当进程获取 CPU 时,附有该 ID 的 PCB 将被恢复。
编辑
据我所知,x86 中没有 CPU 堆栈。 CPU 有指向堆栈第一个元素的堆栈指针。
完整的堆栈未保存在上下文切换中。进程上下文块仅包含我所知道的每个系统上的寄存器值。
堆栈就是一块内存。没有什么特别的。唯一使它成为堆栈的是堆栈指针寄存器引用它。一个进程可以有多个堆栈。事实上,他们通常这样做。进程通常为每个处理器模式都有一个堆栈。在多线程中,每个线程有一个堆栈。
我了解到每个进程在内存中都有自己的area/block,由堆栈、堆、数据和文本(代码)组成(参见this)。
{kind=link}
现在我正在阅读有关上下文切换的内容。我读到在上下文切换期间 CPU 寄存器被压入堆栈,然后整个堆栈将被保存到进程控制块中。基本上是这样吗?
如果每个进程都有自己的堆栈,为什么我需要保存堆栈?
当发生上下文切换时,内核会引入一个新进程并 "kicks out" 旧进程。但是当一个旧进程轮到占用CPU时,它之前的状态(它是"kicked out"时的状态)必须恢复到从它停止的地方开始执行。
所有架构的寄存器数量都是有限的。寄存器还包含在要存储以用于逐出的进程状态中。将寄存器保存在堆栈上是为了提高效率,因此您只需将值弹出即可。
此外,每个进程都有自己的进程控制块 (PCB) 来将这些值存储在上下文切换中,这样调度算法就不会受到阻碍,并且可以在一些简单的进程 ID 上工作。当进程获取 CPU 时,附有该 ID 的 PCB 将被恢复。
编辑 据我所知,x86 中没有 CPU 堆栈。 CPU 有指向堆栈第一个元素的堆栈指针。
完整的堆栈未保存在上下文切换中。进程上下文块仅包含我所知道的每个系统上的寄存器值。
堆栈就是一块内存。没有什么特别的。唯一使它成为堆栈的是堆栈指针寄存器引用它。一个进程可以有多个堆栈。事实上,他们通常这样做。进程通常为每个处理器模式都有一个堆栈。在多线程中,每个线程有一个堆栈。